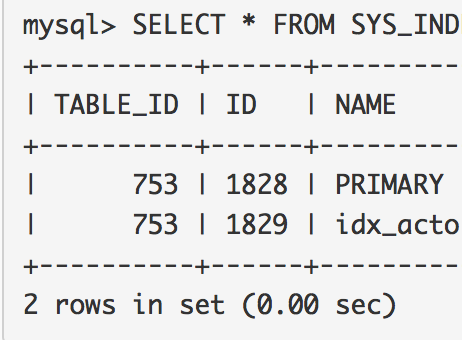
假设你在使用MySQL中的InnoDB表,但是硬件出现问题,或者遇到了驱动程序错误,内核错误,电源故障或某些罕见的MySQL错误,而在InnoDB表空间的某些页被损坏。在这种情况下,Innodb通常打印出如下:
InnoDB: Database page corruption on disk or a failed InnoDB: file read of page 7. InnoDB: You may have to recover from a backup. 080703 23:46:16 InnoDB: Page dump in ascii and hex (16384 bytes): … A LOT OF HEX AND BINARY DATA… 080703 23:46:16 InnoDB: Page checksum 587461377, prior-to-4.0.14-form checksum 772331632 InnoDB: stored checksum 2287785129, prior-to-4.0.14-form stored checksum 772331632 InnoDB: Page lsn 24 1487506025, low 4 bytes of lsn at page end 1487506025 InnoDB: Page number (if stored to page already) 7, InnoDB: space id (if created with >= MySQL-4.1.1 and stored already) 6353 InnoDB: Page may be an index page where index id is 0 25556 InnoDB: (index “PRIMARY” of table “test”.”test”) InnoDB: Database page corruption on disk or a failed
MySQL并且崩溃,日志声称故障。 所以你要如何恢复这样的表呢?
被损坏的可能有各种东西,我将详细查看这篇文章中的简单示例 – 在聚集键中索引页被损坏。这相比于在secondary索引的数据损坏更糟,该情况下简单的OPTIMIZE TABLE足以重建它,但它相对于表字典损坏又较好,因为该情况下表的恢复会更难。
在这个例子中,我其实手动编辑了test.ibd 文件,替换了几个字节使得损坏较轻。
首先,注意在INNODB中的CHECK TABLE 没什么用。从手动损坏的表中获得:
mysql> check table test; ERROR 2013 (HY000): Lost connection to MySQL server during query mysql> check table test; +-----------+-------+----------+----------+ | Table | Op | Msg_type | Msg_text | +-----------+-------+----------+----------+ | test.test | check | status | OK | +-----------+-------+----------+----------+ 1 row in set (0.69 sec)
在这个例子中,数据损坏只发生在页中,所以一旦你以innodb_force_recovery=1 启动Innodb,你能进行如下操作:首先在正常操作模式下运行check table – 在这样的情况下,如果有校验错误(即使我们运行CHECK操作),Innodb 就直接崩溃了。在第二种情况下,我设置innodb_force_recovery=1 ,你能看到即使在日志文件中获得校验故障的信息,CHECK TABLE 仍显示表没问题。这表示你不能相信Innodb中的CHECK TABLE 来确定表没问题。
mysql> CREATE TABLE `test2` (-> `c` char(255) DEFAULT NULL, -> `id` int(10) unsigned NOT NULL AUTO_INCREMENT, -> PRIMARY KEY (`id`) -> ) ENGINE=MYISAM; Query OK, 0 rows affected (0.03 sec) mysql> insert into test2 select * from test; Query OK, 229376 rows affected (0.91 sec) Records: 229376 Duplicates: 0 Warnings: 0
现在,在MyISAM表中有所有的数据,你只要删除旧表,并在在没有innodb_force_recovery选项下重新启动Innodb后将新表转移回Innodb。你还可以重命名旧表,以便以后能详细查看。另一种方法是用MySQLDump转储表并将它加载回来。这差不多是同样的。我正在使用MyISAM表,随后你会看到原因。
你可能会认为你为什么不干脆用OPTIMIZE TABLE重建表?这是因为在innodb_force_recovery模式下运行,Innodb就只对于数据操作可读,这样就不能插入或删除任何数据(虽然你可以创建或删除InnoDB表):
mysql> optimize table test; +-----------+----------+----------+----------------------------------+ | Table | Op | Msg_type | Msg_text | +-----------+----------+----------+----------------------------------+ | test.test | optimize | error | Got error -1 from storage engine | | test.test | optimize | status | Operation failed | +-----------+----------+----------+----------------------------------+ 2 rows in set, 2 warnings (0.09 sec)
我也这样认为,所以我接下来对test.ibd进行了一些编辑,完全删除其中一个页头。现在CHECK TABLE 将会崩溃,即使innodb_force_recovery=1这很简单,对吧?
080704 0:22:53 InnoDB: Assertion failure in thread 1158060352 in file btr/btr0btr.c line 3235 InnoDB: Failing assertion: page_get_n_recs(page) > 0 || (level == 0 && page_get_page_no(page) == dict_index_get_page(index)) InnoDB: We intentionally generate a memory trap. InnoDB: Submit a detailed bug report to http://bugs.mysql.com. InnoDB: If you get repeated assertion failures or crashes, even
如果你得到这样的故障声明,很可能更高的innodb_force_recovery 值也没什么帮助 – 只有在多个系统区域有损坏的情况下有用,但不能以Innodb处理页数据的方式作什么改变。
接下来是试错的做法:
mysql> insert into test2 select * from test; ERROR 2013 (HY000): Lost connection to MySQL server during query
你可能认为mysql将扫描表直到首先损坏的行并在MyISAM表中获得结果?
遗憾的是,test2 在运行后为空的。同时,我看到一些可能被选出的数据。问题是,有一些缓冲发生,而MySQL崩溃时不会将所有能够恢复的数据储存到MyISAM表。
手动恢复时,使用一些带有LIMIT的查询更简便:
mysql> insert ignore into test2 select * from test limit 10; Query OK, 10 rows affected (0.00 sec) Records: 10 Duplicates: 0 Warnings: 0 mysql> insert ignore into test2 select * from test limit 20; Query OK, 10 rows affected (0.00 sec) Records: 20 Duplicates: 10 Warnings: 0 mysql> insert ignore into test2 select * from test limit 100; Query OK, 80 rows affected (0.00 sec) Records: 100 Duplicates: 20 Warnings: 0 mysql> insert ignore into test2 select * from test limit 200; Query OK, 100 rows affected (1.47 sec) Records: 200 Duplicates: 100 Warnings: 0 mysql> insert ignore into test2 select * from test limit 300; ERROR 2013 (HY000): Lost connection to MySQL server during query
注意,即使你不使用MyISAM表,而是获取脚本的数据,在MySQL崩溃时一定要使用LIMIT或PK Rangers,你不会得到所有在网络数据包的数据,由于缓冲你可能得到部分。你能看到,我可以从新的测试的表中获取行,直到最终遇到使MySQL崩溃的行。在这种情况下,我们可以预估在200和300之间有这样的行,我们可以执行一大堆类似的语句,进行“二进制搜索”来查找确切的行号。
所以,现在我们发现在表中损坏的数据,我们需要以某种方式跳过它。为此我们要找到能被恢复的最大PK,并尝试一些更高的值。
mysql> select max(id) from test2; +---------+ | max(id) | +---------+ | 220 | +---------+ 1 row in set (0.00 sec) mysql> insert ignore into test2 select * from test where id>250; ERROR 2013 (HY000): Lost connection to MySQL server during query mysql> insert ignore into test2 select * from test where id>300; Query OK, 573140 rows affected (7.79 sec) Records: 573140 Duplicates: 0 Warnings: 0
因此,我们试图跳过30行,太少,跳过80行,还行。再次使用二进制搜索,获知你需要跳过多少行来恢复尽可能多的数据。行大小对你很有用。在这个例子中,每行约280个字节,所以每页有50行,所以30行不够也不令人吃惊 – 通常,如果页目录已损坏,你至少需要跳过整个页面。如果页面在较高层级在BTREE损坏,你可能需要跳过很多页(整个子树)来使用此恢复方法。
你可能需要跳过多个坏页,而不只示例中的一个。
另一个提示 – 你最好CHECK在MySQL崩溃之后用于恢复的MyISAM表,以确保索引没有被损坏。
我们探讨了如何从简单的InnoDB表获得恢复的数据。在更复杂的情况下,你可能需要使用较高的innodb_force_recovery模式来阻止数据清楚,插入缓冲合并或从事务日志进行恢复。虽然说恢复模式越低,恢复过程中越可能得到更好的数据。
在某些情况下,如数据字典或聚类索引的“root页”损坏,此方法将无法很好地运作。在这种情况下,您可能希望使用恢复软件包,它在需要恢复被删除的行或表时也很有帮助。
我还要说一下,我们提供MySQL恢复的援助,包括对Innodb损坏和被删除的数据进行恢复。