PRM-DUL Oracle Database Recovery Tool (PRM-DUL) is one advanced tool developed for Oracle data recovery.
From release 1.0 to now, more functions and enhancements have been built into the new version. And continuous bug fixes and logical improvements support it to be now more stable in various enterprise environment.
- Many cases have proved that PRM-DUL Oracle Database Recovery Tool can work well on multiple OS platforms (AIX/HPUX/SOLARIS/Linux/Windows). The current version now support Oracle 9i/10g/11g/12c Oracle Databases Data Rescue Operations.
- It is a Java based, free installation software. You can start it directly after download and unzip the package. (On Windows, click the executable file prm.bat. On Linux/Unix, the start file is prm.sh)
** We advise users to use Java 1.6 or higher version before trying PRM-DUL 4.0.
Java official version can support most of PRM-DUL functions except raw device operations. If you are using this tool for raw device data recovery, please install Java OpenJDK instead. - PRM-DUL GUI interface can help user for easy use. It is not necessary for users to learn extra sets of commands or try to understand Oracle data file layout structures. Through PRM-DUL Recovery Wizard, we can easily rescue the database data and “save my life” J.
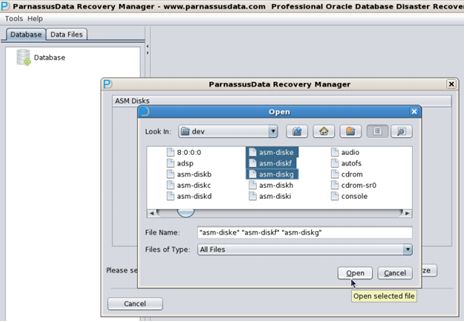
- PRM-DUL supports single data file scan and data extraction, it also supports Oracle ASM storage data recovery.
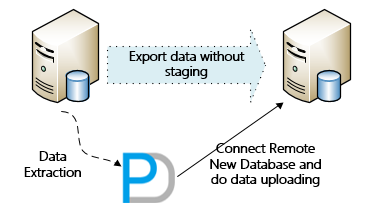
- The rescued data can be exported in sql loader data file format. And also we can use PRM-DUL Data Bridge function to export data and insert into one another new database directly, that means data can be rescued and recovered without staging.
————————-
Version 4.0 Enhancements:
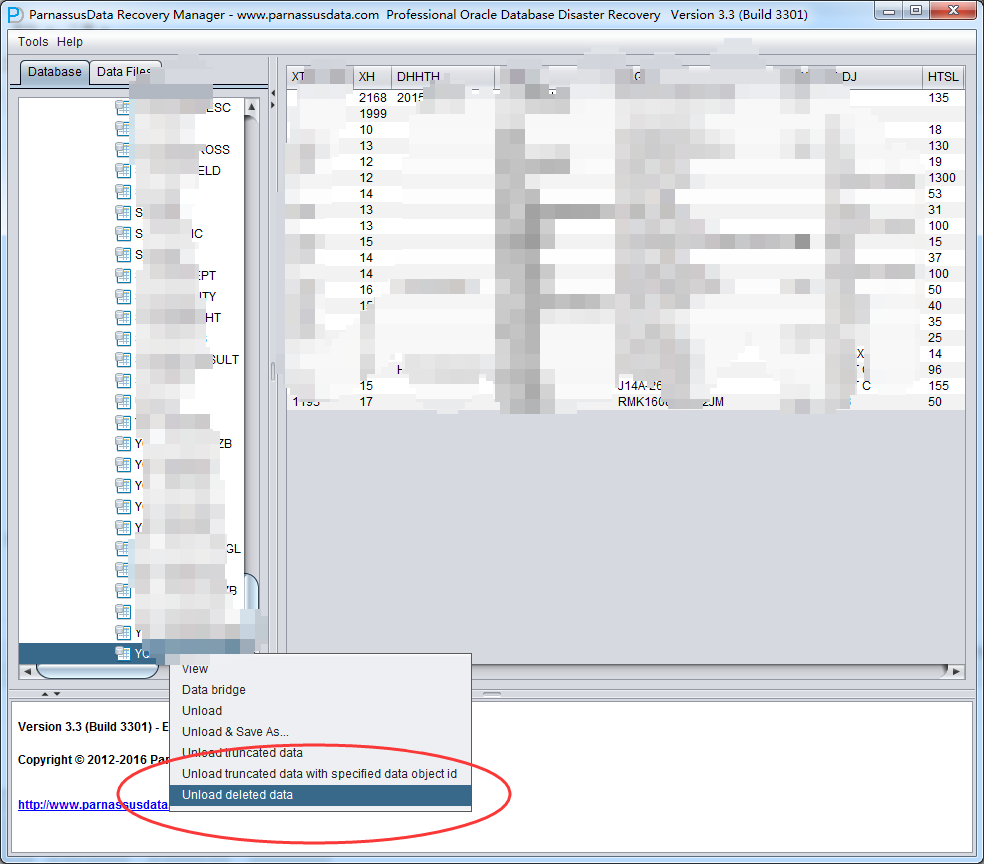
- Support data recovery for table DELETE wrong operations.
- Great improvements on exporting performance for LOB data bridge in dictionary mode.
- Add support for LOB data bridge in non-dictionary mode.
- Add support for re-use dictionary mode/non-dictionary mode scanning data info.
- Add DDL export support at schema level
————————-
PRM-DUL Oracle Database Recovery Tool – Major functions:
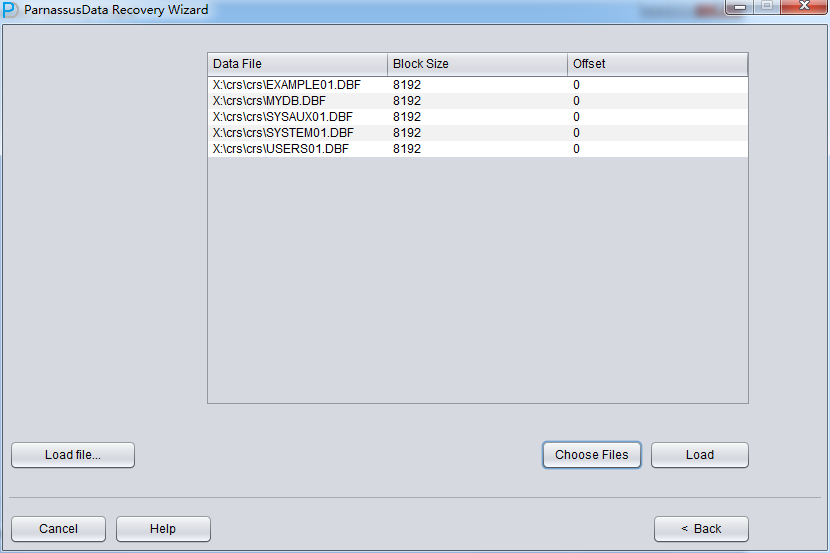
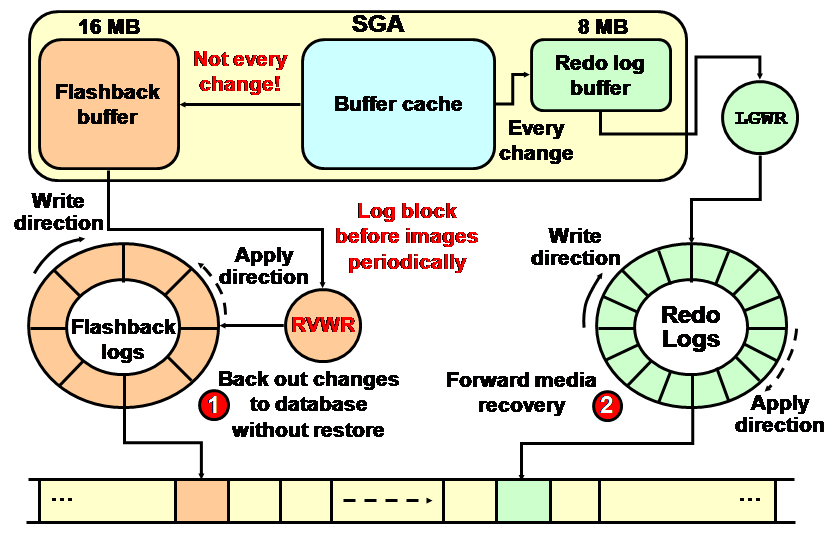
- Can do data scanning and analyzing on database files, no matter Oracle Database is running or not.
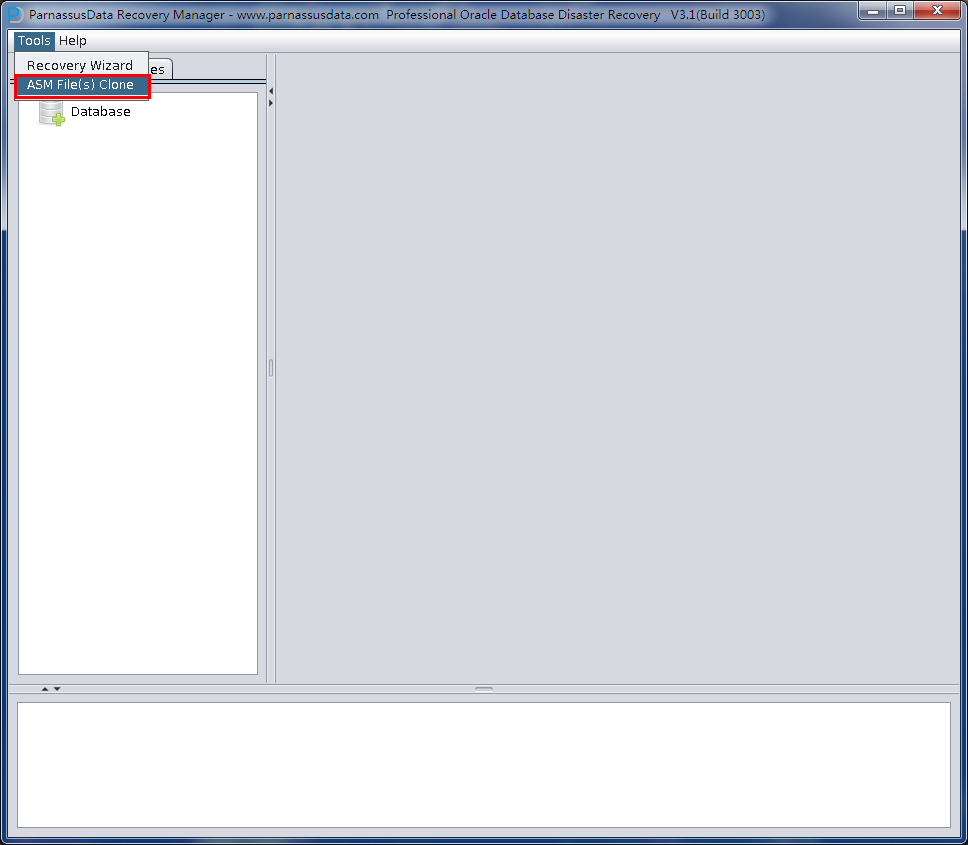
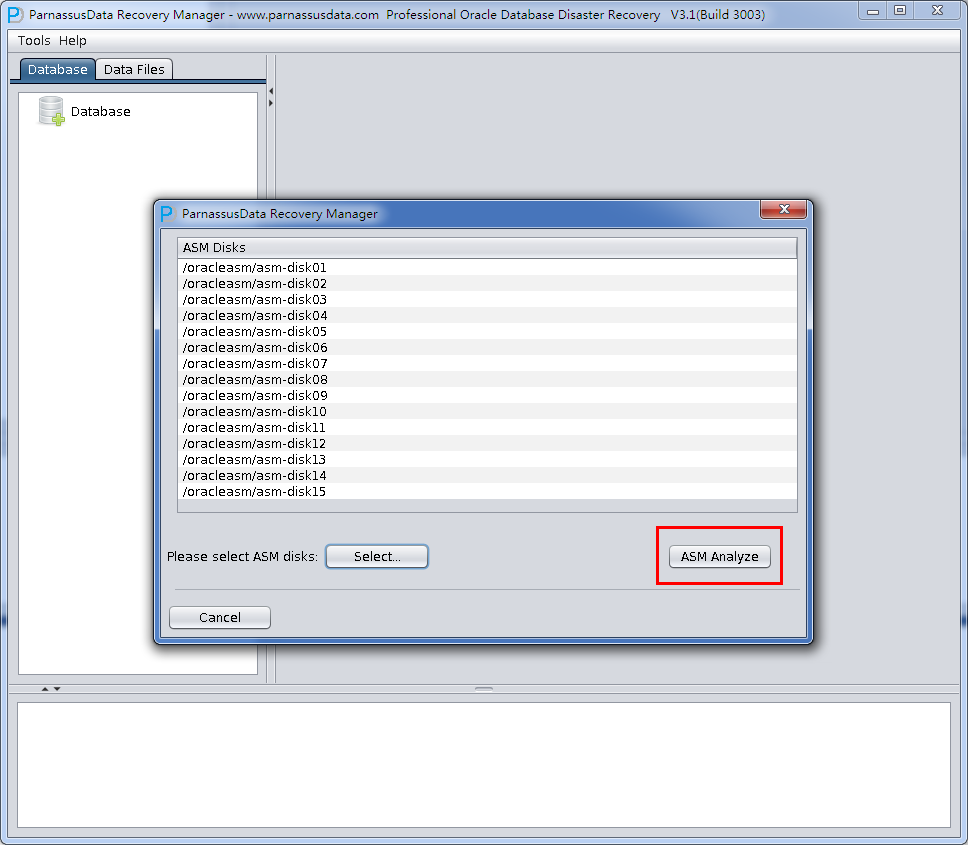
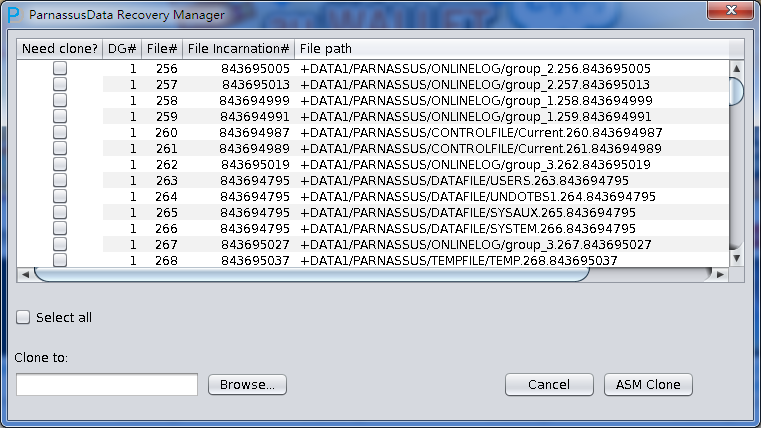
- Support ASM, PRM-DUL can read ASM storage disks directly, find the data files and then do the data scanning and analyzing.
- Support raw devices data files reading.
- Support LOB (CLOB, NCLOB and BLOB) column data recovery, it also supports the case when different LOB columns have different chunk size in one same table.
- Support Oracle database recovery on multiple Big Endian or Little Endian operating systems (AIX/HPUX/SOLARIS/Linux/Windows).
- Support partition, sub-partition data recovery
- Support various table data recovery, which also includes HEAP tables and CLUSTER tables.
- Support truncated table data recovery.
- Support dropped table data recovery.
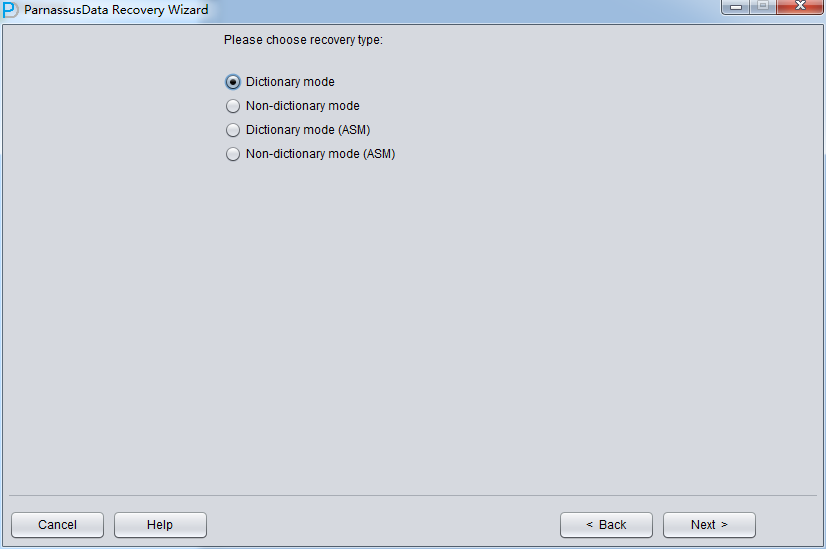
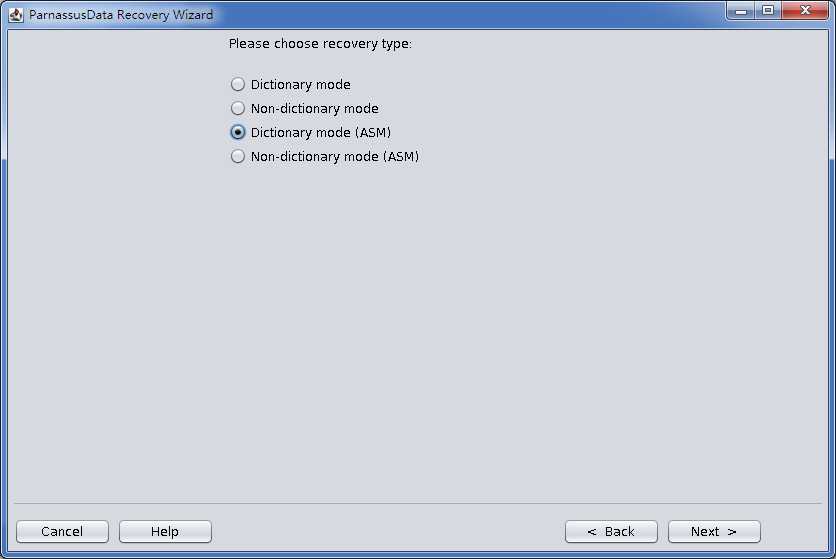
- Support Non-dictionary mode data recovery when SYSTEM table space is missing or data dictionary is broken. Provide part of block data to assist user to determine the data type for recovery.
- Support BigFile table space data recovery.
- Support data files with different block sizes in one same database.
- Support CREATE table SQL file and sqlldr control file auto-generating when rescued data is exported into flat file.
————————-
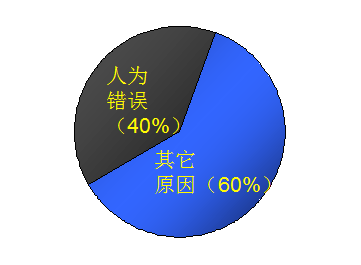
In the growing enterprise IT systems, data capacity is expanding in geometric progression. Even if DBAs are aware of the importance of backup, they will still suffer from problems such as lack of backup storage space, backup failures or unavailable, physical storage disaster damage, and so on. Therefore, it’s necessary for DBAs to familiar with a physical data recovery tool and understand how to use it.
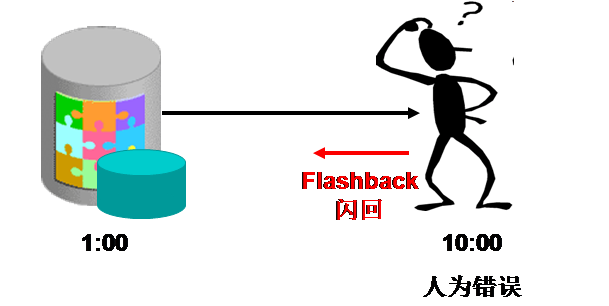
If your Oracle database downs due to an unexpected failure, the physical storage is damaged and cannot be restarted, and you are stuck in the backup is too old to be used. Then you can consider trying PRM-DUL for emergency rescue processing.
————————-
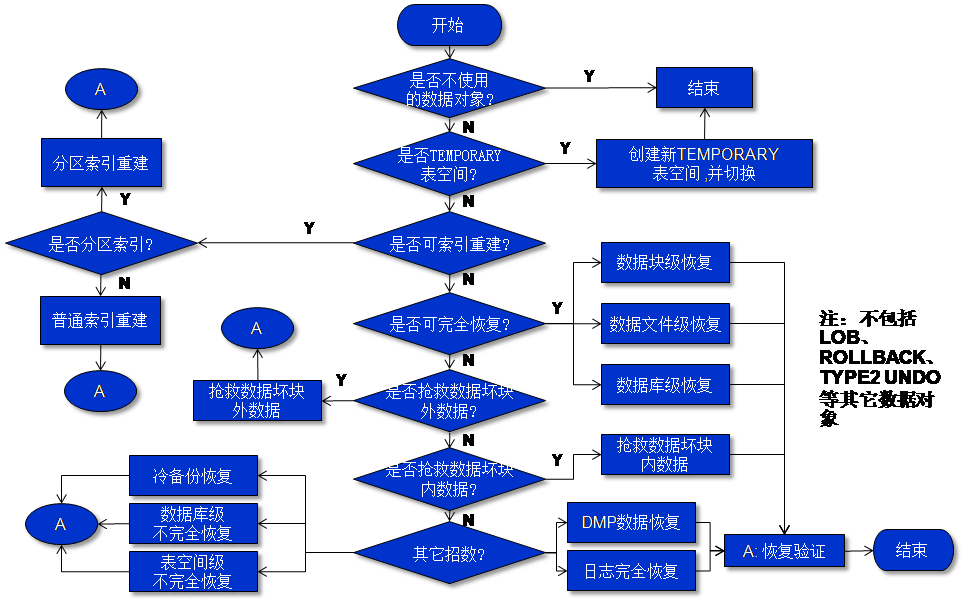
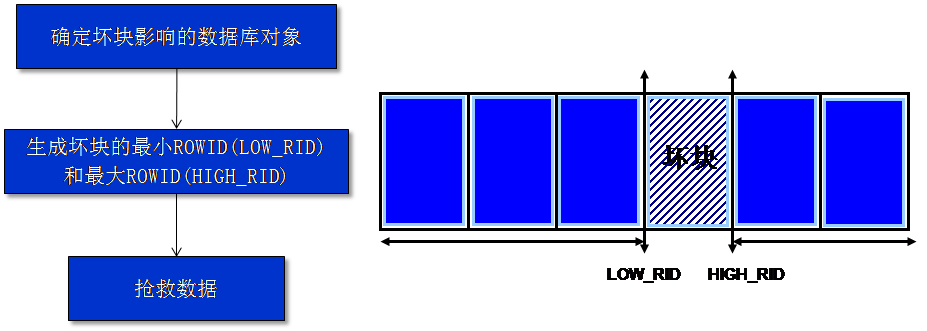
There are many types of errors to show Oracle Database’s disaster damage or block corruption:
Such as block corruption/bad block, index corruption/ bad block, row corruption/ bad block, UNDO corruption/bad block, control file corruption, consistent read problem, data dictionary corruption, data file/RDBA/BL problem etc. If you meet ORA-1578 / ORA-8103 / ORA-1410 / ORA-1499 / ORA-1578 / ORA-81## / ORA-14## / ORA-26040 / ORA-600 …errors but failure to recover it, we advise you to try PRM-DUL as one of your data rescue means.
————————-
PRM-DUL Oracle database recovery tool has two editions (for Community and Enterprise):
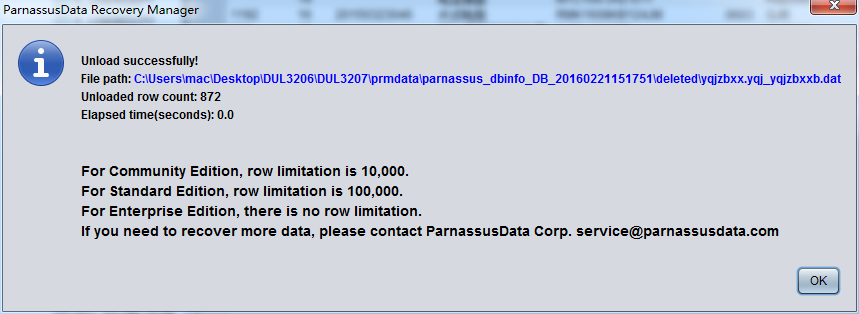
- Community Edition – Oracle database users can free download the latest version at any time from parnassusdata.com. Without the purchase of License, the software is free for use as a community version, the community version allows each table up to 10,000 lines of data rescue export, so users can use the software for free on some small databases.
- Enterprise Edition – If the table row number required to be recovered is more than 10,000 and you’ve tried PRM-DUL and confirm it can fix your problem. Then you can visit the official website and consider to purchase the Enterprise License for this tool. After the registration for the software by using the license you’ve got. Your software can be upgraded from the community edition to the enterprise one. The enterprise edition has no line number limit, and all other functions and enhancements will be open to you.
————————-
If you have more questions about using this tool or you need more help on it, don’t hesitate to visit the official website at http://www.parnassusdata.com/. Call the hotline or email our software service for additional help.











 \
\



