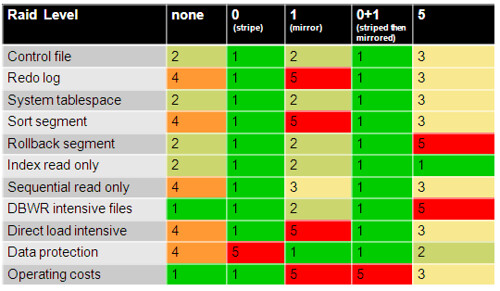
初学Oracle的朋友肯定对Controlfile控制文件中到底记录了何种的信息记录而感到好奇,实际上我们可以通过一个视图v$controlfile_record_section来了解控制文件的信息片段:
SQL> select type, record_size, records_total from v$controlfile_record_section;
TYPE RECORD_SIZE RECORDS_TOTAL
---------------------------- ----------- -------------
DATABASE 316 1
CKPT PROGRESS 8180 35
REDO THREAD 256 32
REDO LOG 72 192
DATAFILE 520 1024
FILENAME 524 4674
TABLESPACE 68 1024
TEMPORARY FILENAME 56 1024
RMAN CONFIGURATION 1108 50
LOG HISTORY 56 292
OFFLINE RANGE 200 1063
ARCHIVED LOG 584 136
BACKUP SET 40 1227
BACKUP PIECE 736 1000
BACKUP DATAFILE 200 1063
BACKUP REDOLOG 76 430
DATAFILE COPY 736 1000
BACKUP CORRUPTION 44 1115
COPY CORRUPTION 40 1227
DELETED OBJECT 20 818
PROXY COPY 928 1004
BACKUP SPFILE 124 131
DATABASE INCARNATION 56 292
FLASHBACK LOG 84 2048
RECOVERY DESTINATION 180 1
INSTANCE SPACE RESERVATION 28 1055
REMOVABLE RECOVERY FILES 32 1000
RMAN STATUS 116 141
THREAD INSTANCE NAME MAPPING 80 32
MTTR 100 32
DATAFILE HISTORY 568 57
STANDBY DATABASE MATRIX 400 31
GUARANTEED RESTORE POINT 212 2048
RESTORE POINT 212 2083
DATABASE BLOCK CORRUPTION 80 8384
ACM OPERATION 104 64
FOREIGN ARCHIVED LOG 604 1002
v$controlfile_record_section 的数据实际来源于X$KCCRS内部表
v$controlfile_record_section 视图的定义
select inst_id,
decode(indx,
0,
'DATABASE',
1,
'CKPT PROGRESS',
2,
'REDO THREAD',
3,
'REDO LOG',
4,
'DATAFILE',
5,
'FILENAME',
6,
'TABLESPACE',
7,
'TEMPORARY FILENAME',
8,
'RMAN CONFIGURATION',
9,
'LOG HISTORY',
10,
'OFFLINE RANGE',
11,
'ARCHIVED LOG',
12,
'BACKUP SET',
13,
'BACKUP PIECE',
14,
'BACKUP DATAFILE',
15,
'BACKUP REDOLOG',
16,
'DATAFILE COPY',
17,
'BACKUP CORRUPTION',
18,
'COPY CORRUPTION',
19,
'DELETED OBJECT',
20,
'PROXY COPY',
21,
'BACKUP SPFILE',
23,
'DATABASE INCARNATION',
24,
'FLASHBACK LOG',
25,
'RECOVERY DESTINATION',
26,
'INSTANCE SPACE RESERVATION',
27,
'REMOVABLE RECOVERY FILES',
28,
'RMAN STATUS',
29,
'THREAD INSTANCE NAME MAPPING',
30,
'MTTR',
31,
'DATAFILE HISTORY',
32,
'STANDBY DATABASE MATRIX',
33,
'GUARANTEED RESTORE POINT',
34,
'RESTORE POINT',
35,
'DATABASE BLOCK CORRUPTION',
36,
'ACM OPERATION',
37,
'FOREIGN ARCHIVED LOG',
'UNKNOWN'),
rsrsz,
rsnum,
rsnus,
rsiol,
rsilw,
rsrlw
from x$kccrs
where indx not in (22)
下表罗列出了controlfile 控制文件可能出现的数据库各类文件的记录,如数据文件记录、文件名记录、表空间记录等:
1. Database Information Record: (1 per database) 2. Checkpoint Progress Record: (1 per thread) 3. Redo Thread Record: (1 per thread) 4. Logfile Record: (1 per logfile) 5. Datafile Record: (1 per datafile) 6. Filename Record: (1 per datafile, tempfile or logfile group member) 7. Tablespace Record: (1 per tablespace) 8. Temporary File Record: (1 per tempfile) 9. RMAN Configuration Record: (1 per configuration parameter) 10. Log History Record: (1 per completed logfile) 11. Offline Range Record: (1 per offline range per datafile) 12. Archived Log Record: (1 per archived log) 13. Backup Set Record: (1 per backup set) 14. Backup Piece Record: (1 per backup piece) 15. Backup Datafile Record: (1 per datafile) 16. Backup Redo-log Record: (1 per archived log) 17. Datafile Copy Record: (1 per datafile) 18. Backup Datafile Corruption Record: (1 per corrupt range) 19. Datafile Copy Corruption Record: (1 per corrupt range) 20. Deleted Object Record: (1 per deleted object) 21. Proxy Copy Record: (1 per proxy datafile or archived log) 22. Backup SPFILE Record: (1 per SPFILE) 23. Extended Database Information Record: (1 per database) 24. Flashback Database Log Record: (1 per flashblack log) 25. Recovery Destination Information Record: (1 per database) 26. Instance Recovery Table Record: (1 per instance) 27. Aged File Record: (1 per aged control file record) 28. RMAN Status Record: (1 per RMAN session/operation) 29. Thread Instance Name Mapping Record: (1 per thread) 30. MTTR Record: (1 per thread) 31. Datafile History Record: (1 per dropped datafile)