什么是High Water Mark 高水位?
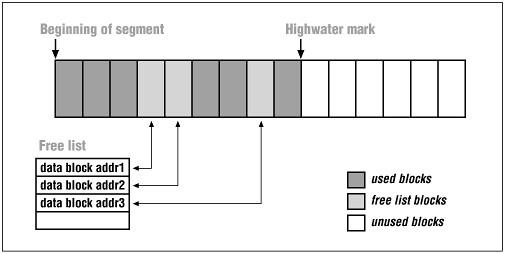
“The high water mark starts at the first block of a newly created table. Ads data is inserted, the high water mark rises. And the HWM will remain at that level in spite of delete operations.
The HWM matters since Oracle will scan all blocks below the HWM even when they contain no data during a full scan – just to see if they have data. TRUNCATE will reset the HWM, so will other operations described next.”
我们知道Oracle中的数据段(segment)均有一个存放数据的上边界。这条上边界被称作High Water Mark”高水位”或者简写为HWM。
高水位标记了那些已经分配给数据段但还没有真正被使用的数据块。常规情况下高水位以每次5个数据块的速度上涨。全表扫描通常从起始Extent开始到高水位标记结束。注意delete操作是无法降低高水位线的,而truncate操作可以,不管是truncate drop storage还是 truncate use storage 均会把 高水位线”置零”。
这里的置零具体是指:
在truncate drop storage 的情况下:
SQL> create table maclean_test1 tablespace users as select * from dba_objects;
Table created.
SQL> create index objd_test1 on maclean_test1(object_id) tablespace users;
Index created.
SQL> create table maclean_test2 tablespace users as select * from dba_objects;
Table created.
SQL> create index objd_test2 on maclean_test2(object_id) tablespace users;
Index created.
SQL> exec dbms_stats.gather_table_stats('SYS','MACLEAN_TEST1',cascade=>TRUE);
PL/SQL procedure successfully completed.
SQL> exec dbms_stats.gather_table_stats('SYS','MACLEAN_TEST2',cascade=>TRUE);
PL/SQL procedure successfully completed.
SQL> analyze index objd_test1 validate structure;
Index analyzed.
SQL> select HEIGHT,BLOCKS,LF_BLKS,BR_BLKS,BTREE_SPACE from index_stats;
HEIGHT BLOCKS LF_BLKS BR_BLKS BTREE_SPACE
---------- ---------- ---------- ---------- -----------
2 40 29 1 239912
SQL> analyze index objd_test2 validate structure;
Index analyzed.
SQL> select HEIGHT,BLOCKS,LF_BLKS,BR_BLKS,BTREE_SPACE from index_stats;
HEIGHT BLOCKS LF_BLKS BR_BLKS BTREE_SPACE
---------- ---------- ---------- ---------- -----------
2 40 29 1 239912
set serveroutput on
DECLARE
TOTAL_BLOCKS number;
TOTAL_BYTES number;
UNUSED_BLOCKS number;
UNUSED_BYTES number;
LAST_USED_EXTENT_FILE_ID number;
LAST_USED_EXTENT_BLOCK_ID number;
LAST_USED_BLOCK number;
BEGIN
dbms_space.unused_space('SYS',
'MACLEAN_TEST1',
'TABLE',
TOTAL_BLOCKS,
TOTAL_BYTES,
UNUSED_BLOCKS,
UNUSED_BYTES,
LAST_USED_EXTENT_FILE_ID,
LAST_USED_EXTENT_BLOCK_ID,
LAST_USED_BLOCK);
dbms_output.put_line('OBJECT_NAME = MACLEAN_TEST1');
dbms_output.put_line('-----------------------------------');
dbms_output.put_line('TOTAL BLOCKS = ' || TOTAL_BLOCKS);
dbms_output.put_line('TOTAL SIZE(KByte) = ' ||
TOTAL_BYTES / 1024);
dbms_output.put_line('UNUSED BLOCKS = ' || UNUSED_BLOCKS);
dbms_output.put_line('UNUSED SIZE(KByte) = ' ||
UNUSED_BYTES / 1024);
END;
/
OBJECT_NAME = MACLEAN_TEST1
-----------------------------------
TOTAL BLOCKS = 256
TOTAL SIZE(KByte) = 2048
UNUSED BLOCKS = 67
UNUSED SIZE(KByte) = 536
PL/SQL procedure successfully completed.
SQL> truncate table maclean_test1 drop storage;
Table truncated.
exec dbms_stats.gather_table_stats('SYS','MACLEAN_TEST1',cascade=>TRUE);
PL/SQL procedure successfully completed.
set serveroutput on
DECLARE
TOTAL_BLOCKS number;
TOTAL_BYTES number;
UNUSED_BLOCKS number;
UNUSED_BYTES number;
LAST_USED_EXTENT_FILE_ID number;
LAST_USED_EXTENT_BLOCK_ID number;
LAST_USED_BLOCK number;
BEGIN
dbms_space.unused_space('SYS',
'MACLEAN_TEST1',
'TABLE',
TOTAL_BLOCKS,
TOTAL_BYTES,
UNUSED_BLOCKS,
UNUSED_BYTES,
LAST_USED_EXTENT_FILE_ID,
LAST_USED_EXTENT_BLOCK_ID,
LAST_USED_BLOCK);
dbms_output.put_line('OBJECT_NAME = MACLEAN_TEST1');
dbms_output.put_line('-----------------------------------');
dbms_output.put_line('TOTAL BLOCKS = ' || TOTAL_BLOCKS);
dbms_output.put_line('TOTAL SIZE(KByte) = ' ||
TOTAL_BYTES / 1024);
dbms_output.put_line('UNUSED BLOCKS = ' || UNUSED_BLOCKS);
dbms_output.put_line('UNUSED SIZE(KByte) = ' ||
UNUSED_BYTES / 1024);
END;
/
OBJECT_NAME = MACLEAN_TEST1
-----------------------------------
TOTAL BLOCKS = 8
TOTAL SIZE(KByte) = 64
UNUSED BLOCKS = 5
UNUSED SIZE(KByte) = 40
这里一个非deffered segment至少仍会使用3个数据块, 而truncate drop storage后高水位线就在这第三个数据块之上
SQL> analyze index objd_test1 validate structure;
Index analyzed.
SQL> select HEIGHT,BLOCKS,LF_BLKS,BR_BLKS,BTREE_SPACE from index_stats;
HEIGHT BLOCKS LF_BLKS BR_BLKS BTREE_SPACE
---------- ---------- ---------- ---------- -----------
1 8 1 0 7996
对表truncate drop storage后,表上的索引收缩到高度为1,且只有一个叶子块
SQL> truncate table maclean_test2 reuse storage;
Table truncated.
SQL> exec dbms_stats.gather_table_stats('SYS','MACLEAN_TEST2',cascade=>TRUE);
PL/SQL procedure successfully completed.
OBJECT_NAME = MACLEAN_TEST2
-----------------------------------
TOTAL BLOCKS = 256
TOTAL SIZE(KByte) = 2048
UNUSED BLOCKS = 253
UNUSED SIZE(KByte) = 2024
PL/SQL procedure successfully completed.
truncate reuse storage后高水位同样回归到第三个数据块以上, 而该数据段的空间并没有回收给表空间
SQL> analyze index objd_test2 validate structure;
Index analyzed.
SQL> select HEIGHT,BLOCKS,LF_BLKS,BR_BLKS,BTREE_SPACE,DEL_LF_ROWS from index_stats;
HEIGHT BLOCKS LF_BLKS BR_BLKS BTREE_SPACE DEL_LF_ROWS
---------- ---------- ---------- ---------- ----------- -----------
1 40 1 0 7996 0
与表段类似索引中的数据已被删除,但是extent空间并不被回收
总结以上测试结果:
Truncate Drop Storage:
- 高水位下降到所能下降的最低位置
- 删除表上的所有数据行并释放空间
- 删除索引上的所有数据,索引的实际结构收缩到高度为1的最少数据块,并释放原有空间
Truncate Reuse Storage:
- 高水位下降到所能下降的最低位置
- 删除表上的所有数据行,但是不释放空间
- 删除索引上的所有数据,索引的实际结构收缩到高度为1的最少数据块,但不释放原有空间
此外值得一提的是11.2.0.2中出现truncate的新特性,截断表目前有了第三种选项:即drop all storage。
对表执行drop all storage的truncate将会导致与该表相关的所有segment均被drop掉,如下例:
SQL> select * from v$version;
BANNER
--------------------------------------------------------------------------------
Oracle Database 11g Enterprise Edition Release 11.2.0.2.0 - 64bit Production
PL/SQL Release 11.2.0.2.0 - Production
CORE 11.2.0.2.0 Production
TNS for Linux: Version 11.2.0.2.0 - Production
NLSRTL Version 11.2.0.2.0 - Production
select * from global_name;
GLOBAL_NAME
---------------------------------------------
www.askmac.cn
conn maclean/maclean
SQL> create table maclean_test3 tablespace users as select * from dba_objects;
Table created.
SQL> create index objd_test3 on maclean_test3(object_id) tablespace users;
Index created.
SQL> col segment_name for a20
SQL> select segment_name,blocks from dba_segments where segment_name in ('MACLEAN_TEST3','OBJD_TEST3');
SEGMENT_NAME BLOCKS
-------------------- ----------
MACLEAN_TEST3 256
OBJD_TEST3 40
SQL> truncate table maclean_test3 drop all storage;
Table truncated.
SQL> select segment_name,blocks from dba_segments where segment_name in ('MACLEAN_TEST3','OBJD_TEST3');
no rows selected
以上可以看到在普通用户模式下对表truncate drop all storage后,该表相关的segment均被事实上的drop了。
注意该drop all storage特性对于SYS用户模式下的对象是无效的,如:
SQL> conn / as sysdba
Connected.
SQL> create table tab1(t1 int);
Table created.
SQL> insert into tab1 values(1);
1 row created.
SQL> commit;
Commit complete.
SQL> select segment_name,blocks from user_segments where segment_name in ('TAB1');
SEGMENT_NAME BLOCKS
-------------------- ----------
TAB1 8
SQL> truncate table tab1 drop all storage;
Table truncated.
SQL> select segment_name,blocks from user_segments where segment_name in ('TAB1');
SEGMENT_NAME BLOCKS
-------------------- ----------
TAB1 8
