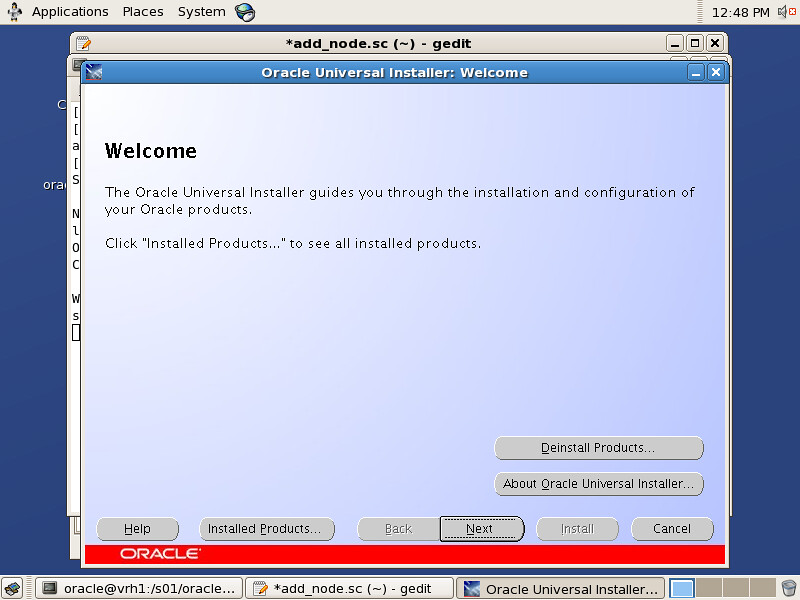
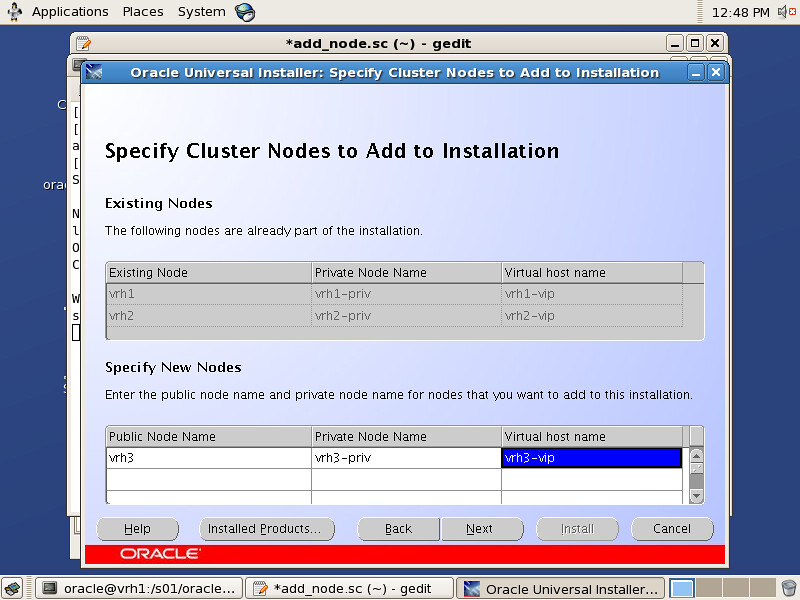
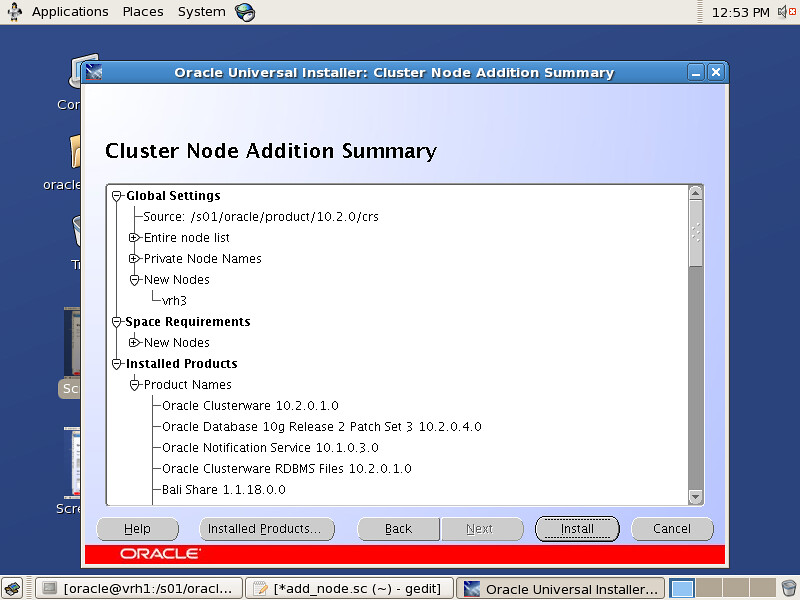
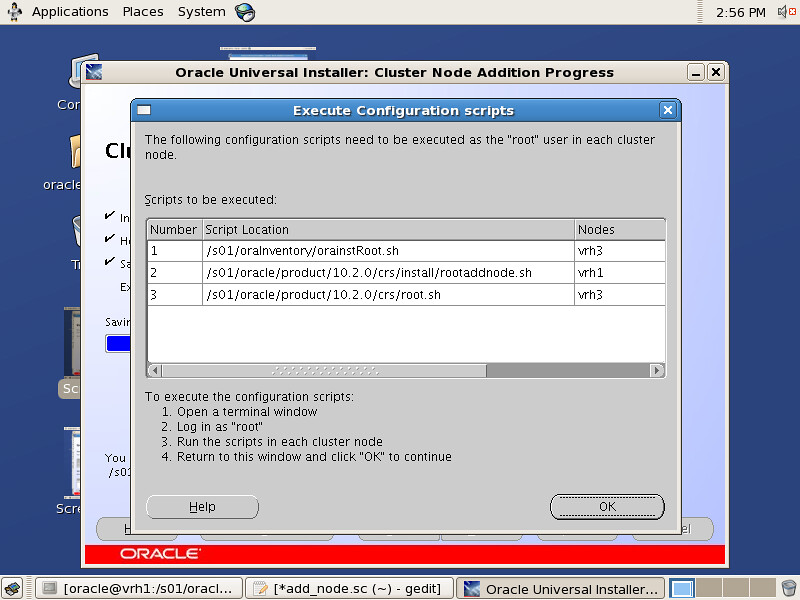
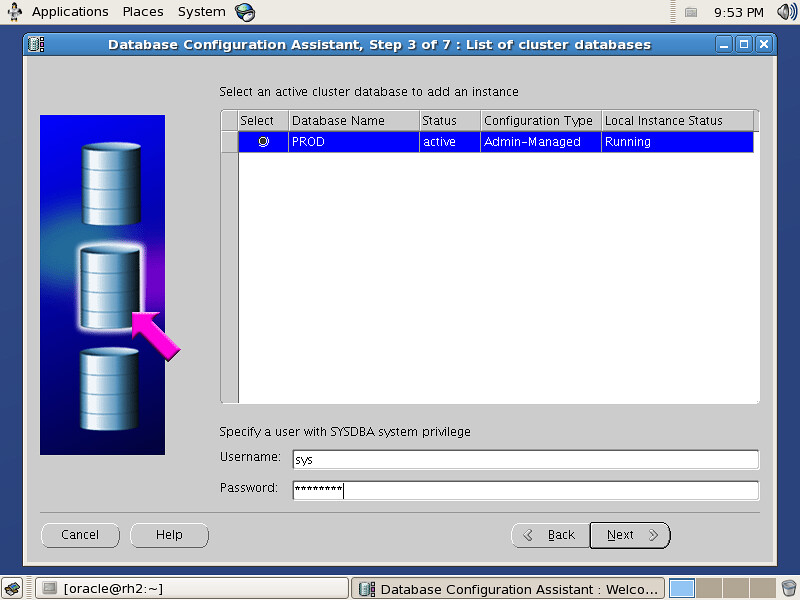
VMware Server版已经2年没有更新,这导致在多个Linux的发行版本上安装VM Server存在种种的阻力。譬如说我现在正在使用的Fedora 15就很难使用Vmware,因此我想到了使用原SUN公司的VirtualBox来替代Vmware。
在网上搜了一圈发现Vbox虚拟RAC环境的Post还不少,花了1天时间实践了一下用VBox部署4节点的11gr2 RAC系统,在这里列出个人对VMware和VirtualBox间特性区别的看法
1.VMware Server可以采用浏览器+插件的方式访问,算的上是一种瘦客户端的应用。就访问的便利而言,Vmware有着明显的优势。VirtualBox默认以前台方式运行,虽然也可以从命令行中以headless方式来后台启动,但就访问来说还是太复杂了
2.Vmware的管理可以完全在管理页面中完成,不需要用户额外去记一些命令,管理上更方便。但是管理页面本身需要Tomcat驱动,如果Tomcat或者管理页面出现一些问题的话那么就令人束手无策了。VirtualBox的图形化界面管理还算流畅,但不是所有操作都支持,很大程度上用户需要记部分VBoxManage命令来达到目的,虽然有一定的学习成本,但加强了用户对VBox的了解,VBoxManage命令简单可靠,是我迁移到VBox的一大理由
3.性能方面VirtualBox有较大的优势,主要体现在内存消耗更少,而且Vbox使用的进程也更少(主要是VBoxXPCOMIPCD,VBoxSVC,VBoxHeadless这三个),关于这一点的讨论见OTN上的Oracle RAC on VMWare vs. Virtualbox这个Thread
4.文档数量上,Vmware占有一定优势,这很大程度上得益于vmware公司作为虚拟化方案巨头的大力宣传。而VirtualBox仅是SUN公司x86虚拟化实现中的一环,当然这不影响Vbox作为我们测试RAC或其他MAA方案的最佳平台。Vbox上的11g r2 RAC最佳实践,可见<Oracle Database 11g Release 2 RAC On Linux Using VirtualBox>
关于VirtualBox的一些信息可以见John Heaton的<Oracle Enterprise Linux and Oracle VM (SUN)Virtual Box>:
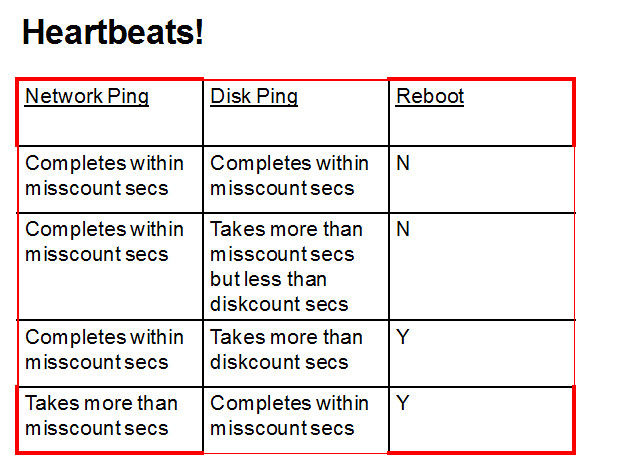
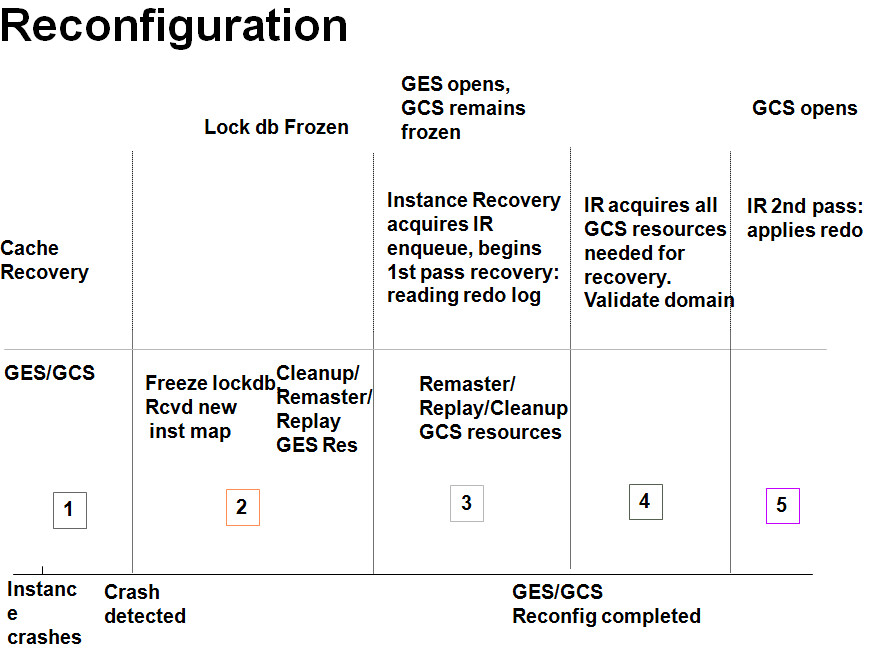
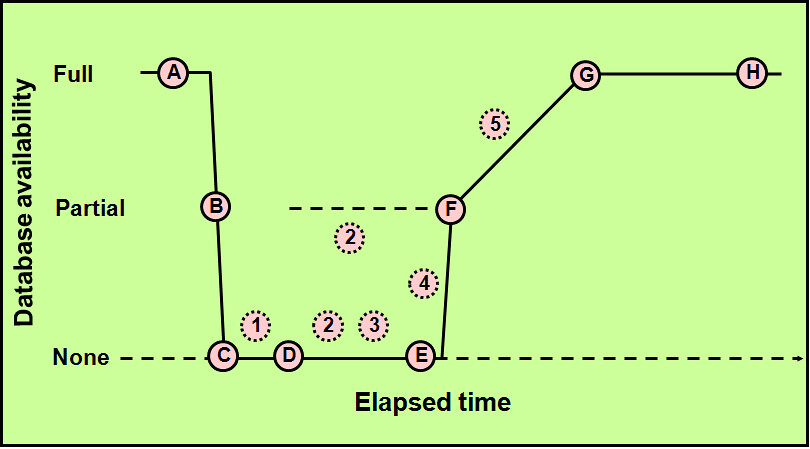
 Internals (INTERNAL ONLY)")