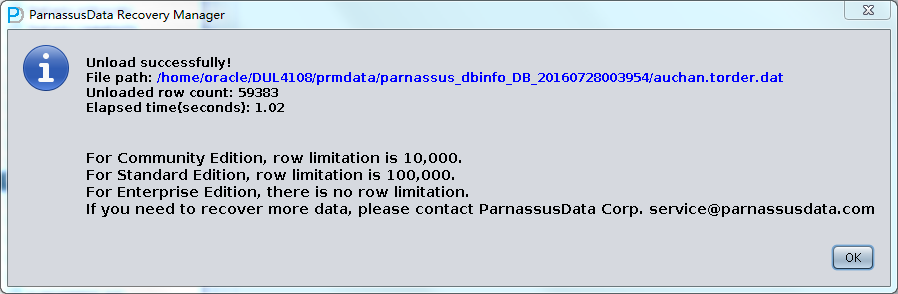
prmscan 是诗檀软件独立研发的ORACLE数据块碎片扫描合并工具,其适用于以下的场景:
- 误手动删除了文件系统(任意文件系统 NTFS、FAT、EXT、UFS、JFS等)或ASM上的数据文件
- 文件系统损坏,导致数据文件大小变成0 bytes即数据文件被清零
- 文件系统损坏,导致文件系统无法MOUNT加载
- ASM存储元数据损坏,导致diskgroup无法mount加载
- 文件系统或ASM其中的LV或PV被物理破坏或丢失
以上场景均可以利用prmscan直接扫描文件系统或ASM对应的 PV、LV 中的残余未被覆盖的oracle block,来实现对这些oracle数据块的合并重组,以达到数据恢复的目的。
PRMSCAN是基于JAVA语言开发的,可以跨一切支持JDK 1.6以后操作系统,包括Windows、Linux、Solaris、AIX、HP-UX。
prmscan 是诗檀软件独立研发的ORACLE数据块碎片扫描合并工具,目前该产品不独立销售,可以联系诗檀软件(13764045638)以服务形式提供恢复服务。
例如下面的例子中/dev/sdb1为ext4文件系统的分区,但是由于ext4文件系统损坏,导致SDB1无法被MOUNT,但该文件系统上存放了一套oracle数据库的数据文件,若无法MOUNT文件系统则oracle数据库也将无法使用。
这里我们使用prmscan的扫描oracle数据文件块和合并功能,从损坏的文件系统中直接将数据文件都重组出来。
- 扫描整个磁盘
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –scan /dev/sdb1 –guess 8k
–scan 选项代表扫描 /dev/sdb1 设备,并指定Oracle blocksize 为8k
[oracle@dbdao01 ~]$ java -jar PRMScan.jar –outputsh ./8kfull.txt
–outputsh 代表写出一个可以合并已扫描到信息的SHELL文件 即这里的8kfull.txt
[oracle@dbdao01 ~]$ sh 8kfull.txt
执行8kfull.txt即可以 在当前目录下生成所有需要合并的数据文件
如下
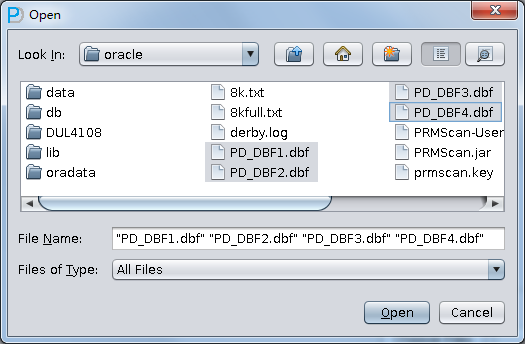
[oracle@dbdao01 ~]$ ls -ll PD*
-rw-r–r– 1 oracle oinstall 295428096 Jul 28 00:37 PD_DBF1.dbf
-rw-r–r– 1 oracle oinstall 83427328 Jul 28 00:37 PD_DBF2.dbf
-rw-r–r– 1 oracle oinstall 220266496 Jul 28 00:37 PD_DBF3.dbf
-rw-r–r– 1 oracle oinstall 1324482560 Jul 28 00:38 PD_DBF4.dbf
使用PRM-DUL扫描这些数据文件
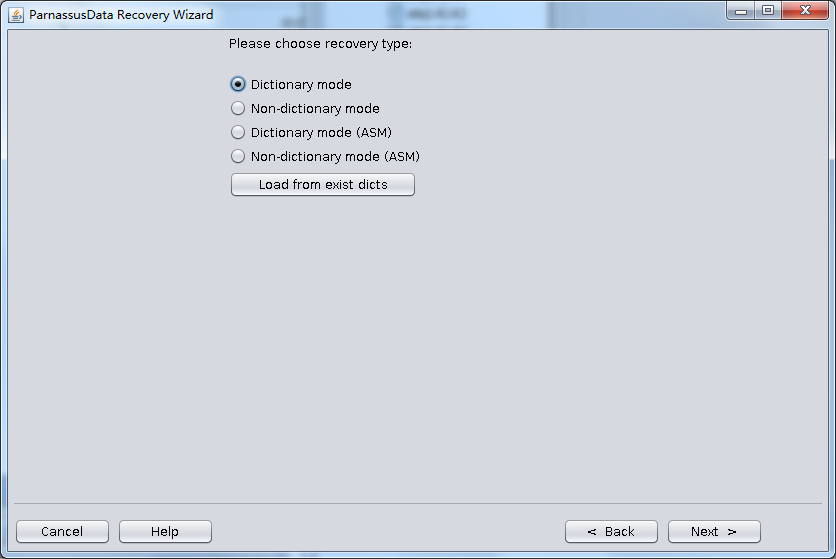

核对数据量