
本文固定链接:https://www.askmac.cn/archives/hadoop-administration.html
Hadoop管理
这一章主要讨论Hadoop在一个多节点集群上的管理。你在这一章将探索Hadoop详细的配置文件,学习Hadoop是如何支持在一个集群中的一个组织中包含多个组的。Hadoop有各种类型的调度器来支持这个功能。本章的目标是使你观察到当一个Hadoop job执行时,集群中每个节点发生了什么微妙变化。
1. Hadoop配置文件
了解了Hadoop中的各种配置文件及其用途后,接下来将要探讨诸如调度器和Hadoop管理之类的概念。
使用Hadoop集群的每一个机器都有其自己的一套配置文件。Hadoop早期版本只有一个配置文件:hadoop-site.xml。接下来的版本将这一文件按功能分为不同文件。此外,有两种配置文件:*-default.xml 和 *-site.xml。*-site.xml文件的配置能覆盖*-default.xml文件的配置。
*-default.xml文件为只读,是直接从JAR文件类路径中读取的。这些文件以及它们相应的位置见表4-1.
表4-1 Hadoop的默认配置文件
配置文件 用途
core-default.xml 默认Hadoop的核心属性。文件位于以下JAR文件中:
hadoop-common-2.2.0.jar(假设版本2.2.0)
hdfs-default.xml 默认HDFS属性。文件位于以下JAR文件中:
hadoop-hdfs-2.2.0.jar (假设版本2.2.0)
mapred-default.xml 默认MapReduce属性。文件位于以下JAR文件中:
hadoop-mapreduce-client-core-2.2.0.jar(假设版本2.2.0)
yarn-default.xml 默认YARN属性。文件位于以下JAR文件中:
hadoop-yarn-common-2.2.0.jar (假设版本2.2.0)
网站特定配置文件通常位于$ HADOOP_CONF_DIR文件夹。这些配置文件会覆盖表4-1中提到的默认文件,代表你的集群(网站)的独特属性 。
网站特定文件中没有提到的属性,使用默认文件中的属性值。这些文件见表4-2.
表4-2 Hadoop网站特定配置文件
配置文件 用途
core-site.xml 网站特定常见Hadoop属性。该文件中配置的属性覆盖core-default.xml文件的属性。
hdfs-site.xml 网站特定HDFS属性。该文件中配置的属性覆盖hdfs-default.xml文件的属性。
mapred-site.xml 网站特定MapReduce属性。该文件中配置的属性覆盖mapred-default.xml文件的属性。
yarn.xml 网站特定YARN属性。该文件中配置的属性覆盖mapred-default.xml文件的属性。
2.配置Hadoop守护进程
除了以上提到的配置文件,Hadoop 管理员可使用以下脚本文件配置Hadoop集群:
- hadoop-env.sh
- yarn-env.sh
- mapred-env.sh
这些脚本文件负责设置如下属性:
- Java主目录
- 各种日志文件位置
- 各种守护进程的JVM选项
管理员可利用表4-3中所示的选项配置个人守护进程。
表4-3. 守护进程配置变量
守护进程 环境变量
主节点 HADOOP_NAMENODE_OPTS
数据节点 HADOOP_DATANODE_OPTS
从元数据节点 HADOOP_SECONDARYNAMENODE_OPTS
资源管理器 YARN_RESOURCEMANAGER_OPTS
节点管理器 YARN_NODEMANAGER_OPTS
例如:用parallelGC配置NameNode,则应添加以下代码到hadoop-env.sh:
export HADOOP_NAMENODE_OPTS="-XX:+UseParallelGC ${HADOOP_NAMENODE_OPTS}
其他可配置的有用属性包括:
- YARN_LOG_DIR: 节点上日志文件存储的目录。这些目录若不存在则启动期间自动生成。
- YARN_HEAPSIZE: 指定堆内存的量以MB计算。其默认值为1,000,表明默认Hadoop为每个守护进程提供1GB的堆内存。虽然只指定一个堆大小,YARN包含多个服务器服务:资源管理器和节点管理器。若每个服务需要不同的堆大小,可单独提供如下等变量值:
- YARN_RESOURCEMANAGER_HEAPSIZE
- YARN_NODEMANAGER_HEAPSIZE
3.Hadoop配置文件的优先级
Hadoop集群中的每个节点都必须有副本配置文件,包括客户端节点。文件中的配置应用如下(按从高到低的顺序):
- 初始化MapReduce作业时,JobConf 或作业对象中的指定值
- 客户端节点上的 *-site.xml
- 从节点上的*-site.xml
- *-default.xml文件上的默认值,这在所有节点上都相同
但是,如果有你不希望客户或程序进行修改的属性,可以将它们标记为最终的,如下所示:
<property>
<name>{PROPERTY_NAME}</name>
<value>{PROPERTY_VALUE}</value>
<final>true</final>
</property>
若从节点上的一个属性被标记为最终的,那么*-site.xml文件客户端版本的配置不能修改它。若客户端节点上的属性被标记为最终,则任务配置(jobconf)实例不能覆盖它。
4.深入Hadoop的配置文件
本节将介绍通过使用前面提到的配置文件,来配置Hadoop集群的一些关键参数,展示Hadoop集群如何在个性化节点级别建立。各种默认的配置文件都记录在下面的链接中:
- http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/core-default.xml
- http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/ hdfs-default.xml
- http://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce- client-core/mapred-default.xml
- http://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
这些链接不仅代表默认值,而且是当前对什么是Hadoop集群设置的最佳实践的认识。然而,Hadoop是既复杂而又新的系统。随着各企业继续使用Hadoop,什么是“最佳实践”的认识将会发生变化。
- 注意:一些属性正不断被弃用,本书中我们使用的hadoop版本为2.2.0,但2.4.1版本已于2014年6月发布。当前现状可参见以下网址:
http://hadoop.apache.org/docs/current/ hadoop-project-dist/hadoop-common/DeprecatedProperties.html
4.1 core-site.xml
core-default.xml文件和core-site.xml文件配置Hadoop系统的公共属性。
本节探讨core-site.xml文件中的主要属性,包括以下内容:
- hadoop-tmp-dir: 其它临时目录的基础。默认值是/tmp/hadoop-${user.name}。有时,我们在 hdfs-site.xml 文件中将此属性引用为几个属性的根目录。
- fs.defaultFs:当没有提供路径时,HDFS客户端使用的默认路径前缀的名称。在第3章“Hadoop框架入门” 中,用hdfs://localhost:9000将其配置伪集群模式。该属性指定主节点的名称和端口(例如hdfs://<NAMENODE>:9000)。对于本地集群,该属性值为file:///。当HDFS的高可用性(HA)功能使用时,该属性应被设置为逻辑HA URI。 (HDFS的HA配置参考Hadoop文档。)
- io.file.buffer-size: 第2章,“Hadoop的概念”中探讨的是HDFS文件创建机制和HDFS文件读取过程。该属性与这些进程有关,指的是缓冲流文件的大小。缓冲器的大小应为硬件页大小(Intel x86 4096)的倍数,并且能决定在读写操作中有多少数据在缓冲。其默认值是4096。
- io.bytes.per.checksum: Hadoop透明的对所有写入的数据应用校验和,并在读取的时候进行验证。该参数定义一个校验和适用的字节数,默认值是512字节。应用CRC-32校验和为4个字节长。因此,默认每存储512字节约有1%的开销(默认设置)。请注意,此参数不能比theio.file.buffer-size的参数值更高,因为校验和是根据HDFS读/写过程中,流动内存中的数据来计算的。它需要在读取处理期间完成计算,来验证在写入过程中存储的校验和。
- io.compression.codecs:一个压缩/解压缩可使用的压缩编解码器类的逗号分隔列表。可用的默认设置是org.apache.hadoop.io.compress.DefaultCodec, org. apache.hadoop.io.compress.GzipCodec, org.apapache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.DeflateCodec, 和 org.apache.hadoop.io.compress. SnappyCodec。(至于压缩方案以及他们是如何应用于Hadoop,在第7章“Hadoop的输入/输出”中将会探讨。)
4.2 hdfs-*.xml
hdfs-default.xml 和hdfs-site.xml文件,配置HDFS的属性。连同接下来将讨论的core-site. Xml文件,都是为集群配置HDFS。正如你在第2章所了解到的,NameNode和Secondary NameNode负责管理HDFS。 hdfs-*.xml文件配置了Hadoop系统的NameNode和Secondary NameNode部分。hdfs-*.xml中的Iare,也用于配置HDFS的运行属性以及与个人数据节点上HDFS文件物理存储有关联的属性。虽然本节中包含的属性名单并不详尽,但可以使我们对物理和运行层面上的HDFS设计有更深的了解。
本节探讨了hdfs-*.xml文件的主要属性。hdfs-site.xml文件的一些重要属性如下:
HDFS-site.xml文件包括以下内容:
- dfs.namenode.name.dir: 存储元数据文件表(fsimage文件)的NameNode本地文件系统上的目录。回想一下,该文件用于存储自上次快照后的HDFS元数据。如果这是一个逗号分隔目录列表,该文件就会被复制到所有目录以备不时之需(确保逗号分隔目录列表中的逗号后没有空格)。该属性的默认值为:file://${hadoop.tmp.dir}/dfs/name。而hadoop.tmp.dir属性指定在core-site.xml文件中(或若 core-site.xml 没有覆盖的话,则为core-default.xml)。
- dfs.namenode.edits.dir:用于存储元数据事务文件(edits文件)的NameNode本地文件系统上的目录。此文件包含自上次快照后HDFS元数据的更改。如果这是一个逗号分隔目录列表,该事务文件就会被复制到所有目录以备不时之需。默认值和dfs.namenode.name.dir相同。
- dfs.namenode.checkpoint.dir: 决定Secondary NameNode存储临时镜像的位置以合并到自身可访问的本地/网络文件系统。回想第2章,这正是NameNode上的fsimage文件被复制并与其edits文件合并的位置。如果这是一个逗号分隔目录列表,该图片就会被复制到所有目录以备不时之需。默认值为:file://${hadoop.tmp.dir}/dfs/namesecondary。
- dfs.namenode.checkpoint.edits.dir: 决定Secondary NameNode从NameNode复制edits文件的存储位置,并与被复制在目录中的fsimage文件合并,该fsimage文件是由Secondary NameNode可访问的、本地/网络文件系统上的dfs.namenode.checkpoint.dir属性定义。如果这是一个逗号分隔目录列表,该edits文件就会被复制到所有目录以备不时之需。默认值与dfs.namenode.checkpoint.dir相同。
- dfs.namenode.checkpoint.period:两个检查点之间的秒数。与参数流逝的时间间隔等同,检查点过程开始,并将NameNode上的edits文件和fsimage文件合并。(该过程在第2章中详细描述过)
- dfs.blocksize: 新文件默认块大小,以字节为单位。默认为128MB。注意:块大小不是一个系统级的参数;它可以在每个文件的基础上指定。
- dfs.replication: 默认块复制。虽然可以为每一文件指定,若未指定则视作文件的复制因子。默认值为3。
- dfs.namenode.handler.count: 代表NameNode用来与DataNodes通信的服务器线程数。默认值为10,建议大概在节点数的10%,最低值为10。如果这个值太低,你可能会看到,DataNode日志上的信息显示:当DataNode试图通过心跳消息与NameNode连接时,该连接被NameNode拒绝。
- dfs.datanode.du.reserved: 单位空间内的预留空间字节,且代表着留给non-HDFS使用的空间数量。默认值为0,但至少应为10GB或总磁盘容量的25%,取最低值。
- dfs.hosts: 这是一个完全限定路径的文件名,包含一系列可与NameNode连接的主机。若未设置属性,所有节点均可与NameNode连接 。
4.3 mapred-site.xml
本节探讨了mapred-site.xml文件的关键属性。需要注意的是,虽然MR V1现在已经被替换成YARN,JobTracker和TaskTracker的原始术语已结转到mapred-site.xml的配置文件中。在探讨这些属性之前,我们先来快速回顾一下MR V2,以及MR V1服务是如何映射到MR v2服务的。
在Hadoop 2中,MapReduce已经被拆分为两部分。集群资源管理的责任现在委托给YARN,而MapReduce特定功能现在是MapReduce作业中一个单独的主应用程序。(YARN结构在第2章中讨论过)
在MR V1中,Hadoop集群由JobTracker服务管理。运行在单个节点上的TaskTracker服务负责启动Map和Reduce任务,并将其健康和进度告知JobTracker。JobTracker跟踪整个集群以及在集群上运行/完成的任务的进程 。
在 MR v2中,JobTracker的功能现分为以下4项服务:
- 资源管理器,属于YARN服务,收到请求并启动应用程序主实例。资源管理器仲裁所有的集群资源,从而管理运行在YARN系统上的分布式应用程序。
- A pluggable (in the Resource Manager) scheduler The role of the Scheduler is to allocate resources to running processes. It does not monitor or track resources. The Resource Manager has other services which perform the role of Monitoring and Tracking processes.
- 可插入(资源管理器中)调度组件。调度的作用是将资源分配给运行中的进程,它不监视或追踪资源。资源管理器有其他可监视、跟踪进程的服务。
- MapReduce的一种由资源管理器启动的主应用程序。 MapReduce主应用程序负责管理它的MapReduce作业,并在作业完成时关闭。这与MR v1不同,JobTracker是一个连续运行的服务,并有单点故障。
- The JobTracker responsibility of providing information about completed jobs has moved to the Job History
- JobTracker中提供有关已完成工作的信息的责任,转移到了Job历史服务器上。
任务管理器的功能现在已被转移到节点管理器上,节点管理器负责启动容器,而每一个容器都能容纳map或reduce任务。它们之间的关系如图4-1所示:

图 4-1. MR v1和 MR v2之间的映射
在读下列列表中的属性时,须牢记图中的关系。这些术语是从MR V1结转的。虽然这些属性仍意味着有多个TaskTracker和一个JobTracker,该参数所指的实际服务仍取决于前面讨论所提供的上下文。
在mapred-site.xml文件中定义的一些重要属性包括这些:
- framework.name: 决定MapReduce作业是否提交给一个YARN集群或利用本地Job Runner在本地运行。该属性的有效值为yarn 和 local。
- mapred.child.java.opts: Map 或 Reduce任务的 JVM堆大小。默认值是-Xmx200m (200 MB的堆空间)。建议指定一个更高的值如512MB或1G,依需求而定。该值应小于或等于在mapreduce.map.memory.mb和mapreduce.reduce.memory.mb属性中的指定值,因为这些属性被主应用程序用来协商来自资源管理器的资源。节点管理器负责启动使用由这些属性指定的JVM堆大小的容器。实际的Map和Reduce任务在容器内执行,该容器使用由mapred.child.opts属性指定的JVM堆大小。如果mapred.child.opts的值比mapreduce.*.memory.mb的属性值高,则任务失败(在“YARN中的内存分配”部分中将会讨论)
- map.memory.mb: 指定需要分配给运行Map任务的容器的内存数量。默认值为1024MB。
- reduce.memory.mb: 指定需要分配给运行Reduce任务的容器的内存数量。默认值为1024MB。
- cluster.local.dir: MapReduce存储中间数据文件的本地目录。它可以是一个不同设备上的逗号分隔目录列表,用于提升磁盘I / O。这些文件的例子有:洗牌排序过程中的映射器处理输出和排序的中间结果。默认值是${hadoop.tmp.dir}/mapred/ local; 这正是dfs.du.reserved值(在core-site.xml中指定)最关键的地方。一般建议是设置该配置,以允许HDFS使用不超过75 %的磁盘空间,使该盘25%的空间用于中间数据文件。
- jobtracker.handler.count: JobTracker所用的服务器线程数(与YARN中的相等)。应为大概4%的从节点数量,最小值为10。默认值也是10。
- job.reduce.slowstart.completedmaps: 任务中的Maps百分比,该Maps在任务调度Reducers之前应是完整的。默认值是0.05,但建议使用0.5到0.8之间的值。
- jobtracker.taskscheduler:负责调度任务的类。默认是被指定为org.apache.hadoop.mapred.JobQueueTaskScheduler的FIFO调度程序。然而,建议使用Fair调度程序或Capacity调度程序(将于本章后面的“调度程序”一节中讨论)
- map.maxattempts: 每一Map任务尝试的最大数量。在放弃或任务失败之前,框架都会一定数量地尝试去执行Map任务。默认值为4。
- reduce.maxattempts: 每一Reduce任务尝试的最大数量。在放弃或任务失败之前,框架都会一定数量地尝试去执行Reduce任务。默认值为4。
4.4 yarn-site.xml
MapReduce经历了从Hadoop-0.23的全面调整。它现在被称为MapReduce 2.0(MRv2)或YARN。最根本的MR v2是资源管理,已经从任务执行中分离出来。每种任务类型是由特定类型的主应用来管理的,该主应用向使用完善定义协议的广义资源管理器请求资源。yarn-site.xml文件用于配置由YARN框架,如资源管理器和节点管理器提供的广义服务守护进程的属性。
yarn-default.xml 和 yarn-site.xml文件都由Hadoop YARN守护进程读取。yarn-default.xml文件提供了默认值,yarn-site.xml文件覆盖了yarn-default.xml中的属性。yarn-*.xml中定义的一些重要属性包括以下内容:
- resourcemanager.hostname: 资源管理器的主机名。
- resourcemanager.address: 资源管理器的服务器上运行的主机名和端口号,默认值为http://${yarn.resourcemanager.hostname}:8032。
- nodemanager.local-dirs: 执行过程中节点管理器发起的容器存储文件的本地逗号分隔目录列表。这些文件通常是附加配置,以及每一分布式主数据文件通过分布式缓存执行任务所需的库。(“分布式缓存”将在第6章《高级MapReduce的发展》中讨论 )当应用程序终止时,这些文件将被删除。
- yarn.nodemanager.aux-services: 由节点管理器执行的辅助服务的逗号分隔列表。其默认值是空白。在第三章中,配置Hadoop安装以使用辅助服务mapreduce_shuffle。在Hadoop2.X中,Shuffle服务被配置为yarn-site.xml中的辅助服务。有关mapreduce_shuffle需要如何配置,可参见第3章了解更多详细信息。
- nodemanager.resource.memory-mb: 在某一节点上,节点管理器执行实例化容器可分配的物理内存总量,默认值是8192。大多数节点的内存都明显高于8GB,并且在考虑到运行OS及其他Hadoop守护进程所需的内存后,应增加该值。
- nodemanager.vmem-pmem-ratio: 设置容器内存限制时,虚拟内存与物理内存之比。容器的分配表示为物理内存的分配,虚拟内存的使用可以超过这个分配的比率。如果yarn.scheduler.maximum-allocation-mb值保持在它的默认值8192,参数设置2.1允许每个容器中虚拟内存上限为8 GB x 2.1 = 16.2 GB。如果超过该比率,则YARN框架可能会舍弃容器。
- yarn.scheduler.minimum-allocation-mb: 根据资源管理器要求每个容器的最低配置,以MB为单位。内存要求低于该最低值则被忽略,指定值被分配的最小。默认值是1024,即1 GB。
- scheduler.maximum-allocation-mb: 根据资源管理器要求每个容器的最高配置,以MB为单位。内存要求最高不超过该值。默认值是8192,即8 GB。
- scheduler.minimum-allocation-vcores: 有关虚拟CPU内核,根据资源管理器要求每个容器的最低配置。要求低于该值无效,且指定值被分配的最小。默认值是1。
- scheduler.maximum-allocation-vcores: 有关虚拟CPU内核,根据资源管理器要求每个容器的最高配置。要求高于该值无效,且最高不得超过该值。默认值是32。
4.5 YARN中的内存分配
正如“配置Hadoop守护进程”一节中所讨论的,Hadoop默认为每一守护进程分配1,000MB的内存,因此节点管理器和数据节点在每一从节点上占据1,000MB的内存。yarn.nodemanager.resource.memory-mb属性,其默认值为8,192MB,指定用于容器的剩余内存。使用默认设置可确保从节点上至少有8,192MB再加上2,000MB可用来执行Hadoop容器。
当主应用程序请求执行Map或Reduce任务时,资源管理器请求节点管理器启动一个容器,其大小由mapreduce.map.memory.mb(或mapreduce.reduce.memory. mb)属性指定。它减少了在被启动的节点上启动另外容器可用的内存量。YARN上被分配来启动容器的总内存(以MB 为单位)是由yarn.nodemanager. resource.memory-mb属性定义的。
如果机器拥有36 GB的RAM ,并决定将24 GB用于YARN容器,8 GB用于剩余的其他,则该属性的值被限定为24576。如果mapreduce.map.memory.mb的值被限定为2 GB(2048),且执行Map任务的容器被启动,则可用来启动其他容器的内存量从24 GB减少到22 GB。
在该容器由节点管理器启动后,它将启动一个子JVM Map或Reduce任务,其堆大小由mapred.child.java.opts属性指定。需要注意的是父进程(已启动的容器)应包含比子JVM(Map或Reduce任务)更多的内存,因为需要额外的内存来聚集如本地库这样的实体。要求是,该容器JVM内存大小代表了容器或它所启动的子任务可用的最大内存。如果这一限制被打破,节点管理器会终止容器,并将其标记为失败。
图4-2 展示了容器任务与容器中启动的Map/Reduce任务之间的关系。

图 4-2 容器任务与Map/Reduce任务之间的关系
附加的约束参数可通过调度程序强加(下一节将会讨论)
5 . Scheduler 调度程序
早期的Hadoop版本仅使用FIFO调度程序。顾名思义,FIFO调度程序依据任务被提交到群集的顺序分配资源。这可能会导致一个长时间运行的任务独占集群资源,阻止更小的任务运行。随后,Hadoop增加了任务优先级,它可以通过为每个任务设置mapred.job.priority属性来配置为下列值:
- VERY_HIGH 非常高
- HIGH 高
- NORMAL 正常
- LOW 低
- VERY_LOW 非常低
虽然用mapred.job.priority属性来控制任务优先级,能在一定程度上缓解该问题,避免任务抢占,但对优先级较低的任务来说仍然有可能垄断资源(如前所述),阻止优先级较高的任务运行。如果在优先级较高的任务进入队列前,低优先级的任务先启动就会发生这种情况。在这种情况下,不用抢占功能,一个长时间运行、低优先级的任务阻止一个高优先级的任务运行,直到它完成。更复杂的调度随后加入来解决这一问题:公平调度和容量调度,后面将会详细讨论。
调度,是资源管理器的一个组成部分,负责分配资源到正在运行的应用程序。资源受如系统容量和队列的限制。调度程序的作用是支持Hadoop集群中的多租户。在多租户中,多组织群可以用最小的资源保证在Hadoop集群上同时执行其应用程序 。
对企业来说,每一个组织通常有足够的资源来满足其峰值条件下的服务水平协议(SLAs)。由于每个组织大部分时间不是在峰值条件下运行的,而且企业内不同组织的高峰期出现在不同的时间,集群的整体利用率较差。而多租户旨在在企业内部利用一个由不同组织共享的共同集群以满足每一组织在峰值条件下的服务水平协议,同时实现对集群的高平均利用率。为发挥这一作用,调度程序需树立以下目标:
- 确保用户和应用程序得到保证份额的集群。
- 使集群的整体利用率最大化
调度器具有可插入的插件政策。 Hadoop2.2.0支持两种类型的可插入式调度器:容量调度和公平调度。确保可插入政策允许开发人员或第三方供应商创建专门的调度。
接下来的两节将详细讨论容量调度和公平调度。
5.1 容量调度
目前容量调度使用以内存为基础的单位分配来分配资源(未来将包括CPU)。这与Hadoop 1.x不同,Hadoop 1.x中分配单位是Map/Reduce槽位。
容量调度通过以下配置支持多租户:
- 跨组织配置保障容量
- 配置资源限制,以防止单个大型应用程序独占集群资源
- 在一个组织群内为各种用户配置资源和访问控制限制
容量调度可通过在表4-4 $HADOOP_CONF_DIR/yarn-site.xml文件属性中所列的设置中进行配置。
表4-4 配置容量调度
属性 值
yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
容量调度有其自己的配置文件,文件位于$HADOOP_CONF_DIR/capacity- scheduler.xml中。
容量调度是基于层次队列的概念,并有一个称为root的预定义队列。
系统中的所有队列都是root队列的子队列,而子队列也都有自己的子队列。队列的容量和限制可在被重新分配给该组的成员后,在组级别进行配置 。
在以下章节中,前述概念将更加清晰。我们假设以下情形-虚拟组织分为三个项目:
- 联机事务处理(OLTP )数据库每晚的ETL 。交易数据汇总到Hadoop集群中的数据仓库
- 在电子商务网站跟踪用户行为。
- 制造集团的资源规划应用程序。
三个项目的用户被划分成以下三个用户组,分别为:
- 运营
- 营销
- 制造
5.2 配置跨组织群的容量担保
容量调度使一个组群各用户及应用间的最小容量得以保证。它为每一组群配置root级队列:运营,市场营销和制造:
yarn.scheduler. capacity.root.queues="operationsmarketing, manufacturing"
在容量调度程序配置文件$HADOOP_CONF_DIR/ capacity-scheduler.xml中配置前述属性实际的语法如下所示。为简洁起见,用前面的符号来代替XML语法中的实际符号:
<property> <name>yarn.scheduler.capacity.root.queues</name> <value>operations, marketing, manufacturing</value> <description>The queues below the root queue(root is the root queue). </description> </property>
接着,在前述组群中集群容量根据总集群容量( 100%)的百分比分类。此时,每一前述组群都会被提供最小容量担保:
前面提到的限制并不只针对MapReduce任务;它们也为Hadoop (YARN) 2.x集群中运行的所有进程定义最低限度的保障,这一区别很重要。YARN的设计允许可插入分布式框架,因此相比MapReduce它支持框架。应调度程序(在资源管理器中运行)要求,资源被节点管理器分配作为容器。因此,运营组无论其运行的任务性质,最少能得到集群40%的担保。同样地,市场组拥有20%的担保 ,而制造组有集群资源40%的担保 。
5.3 强制容量限制
有时,一个组(队列)中的应用程序占用的容量比分配给它的最低资源要少得多。此时,将这些未使用的容量分配给其他队列就很重要。例如,在该例中,运营和制造组也许会将其大部分任务作为夜间流程运行。白天,集群可能更多得被营销队列使用。如果集群具有50%的未使用的容量,那么将该容量分配给营销组是适当的。然而,我们希望限制可分配给营销组的最大容量,可通过在yarn.xml配置文件中使用以下配置来将最高限额设置为50 %:
yarn.scheduler.capacity.root.Marketing.maximum-capacity=50
一个典型的Hadoop集群有长期运行的任务和短期运行的任务。其中Hadoop 1.x 的FIFO调度的一个限制是:一个长期运行的任务可垄断集群资源,阻止短期运行的任务长时间执行。这实际上是个风险,要缓解它最适当的方式是创造一个只针对长期运行任务的分组,限制分配给他们的资源。以下例子就是将一个单独队列定义为一个最低和最高容量都为20%的长期运行任务的配置:
yarn.scheduler.capacity.root.queues="operations,operations-long, marketing, manufacturing" yarn.scheduler.capacity.root.operations-long.capacity=20 yarn.scheduler.capacity.root.operations-long.maximum-capacity=20
5.4强制访问控制限制
最终,各组用户都需要被限制。在一个典型的Hadoop系统中,高级用户因其所执行任务的关键特性,拥有比别人更多的集群资源权限。一个好的系统应该给这些用户更高的优先级,同时不阻止普通用户使用集群。首先,我们通过以下配置允许用户将任务提交到队列:
yarn.scheduler.capacity.root.operations.acl_submit_applications="joe,james,ahmed,ricardo,maria"
接下来,我们限制他们在集群中要求资源的权限:
yarn.scheduler.capacity.root.operations.minimum-user-limit-percent=20
该配置将所有用户在运营队列中运行任务的容量限制到其总容量的20%。
5.5 更新集群中的容量限制变化
容量调度队列,容量和用户ACLs都可动态更新。为了实现目标,我们更新了上述配置并在集群上运行以下管理命令来刷新调度配置,而无需重新启动任何服务:
$HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues
5.6 容量调度方案
在上一节中,我们分配到运营组的五个用户,每一个都被分配了队列总容量的20%。假设用户Joe提交一个作业,那么Joe是活跃在集群中运营组的唯一用户。在这种情况下,运营组的全部容量都被分配给Joe。
如果用户Ahmed提交了另一份作业,操作队列的容量被平均分配给Joe 和 Ahmed(50%给Joe,50%给Ahmed)。如果由于某种原因Ahmed只需要30%的容量,则Joe将被得到剩余的70%。请注意,没有任何任务为了给Ahmed的作业让路而被中断。在Hadoop集群中一个典型作业包括好几个被调度执行的任务。当Joe的任务完成后,不会再有新的任务分配给Joe,除非Joe的资源利用率低于规定限额。
前述过程仍会继续,直到所有五个用户都提交自己的作业,而且每个人都有运营组20%的容量。随着每个用户的作业完成后,额外容量就会被分配给剩余的用户 。
如果出现第六个用户,集群容量将不会被进一步划分。首先容量调度程序会尝试完成五个用户的作业。仅当其中一个作业完成后,资源才会分配给第个六个用户的作业。此功能可以防止集群资源被大量用户过度划分利用。
容量调度程序提供了多种配置旋钮。有关容量调度支持的各种配置参数,请参考Apache文档。
5.7 公平调度
公平调度的目标与容量调度相似,但有细微的差别。容量调度的设计使得FIFO集群为每个组的每个用户模拟,但公平调度的设计是为了保证,平均每个作业都能获得相等份额的资源。如果只有一个作业在运行,它就占用整个集群资源。随着更多的作业被提交,已释放的资源就会被划分给各作业,以便每个作业都能得到大致相同的资源量。
公平调度的动机最开始是从Facebook开始的,Facebook一开始只有几个作业用来分析每天的内容和日志数据。然而,Facebook内的其他组开始使用Hadoop,生产作业的数量也在增加。最终,用户开始通过Hive提交即席查询(Facebook将SQL开发为Hadoop的一种查询语言)。这些短期运行的作业常常与长期运行的作业争夺资源。为长时间运行的作业使用单独的集群将是非常昂贵的,不仅仅是从成本角度,也是从运营角度考虑的,因为相同的数据必须同时存在于两个集群。 Facebook开发了公平调度将资源均匀地分配在各作业之间,同时提供容量担保。
公平调度将应用程序组织到各队列中,并在这些队列间公平地分享资源。默认队列名为default。如果一个应用程序在其容器资源请求中请求特定队列,则会被提交到该队列。队列可在配置基础上通过默认来分配。在这种情况下分配给队列的应用取决于用户的主要信息,例如用户名或该用户被分配的UNIX组。
公平调度可通过在表4-5中$HADOOP_CONF_DIR/yarn-site.xml文件属性的设置来配置。
表4-5 配置公平调度
属性 值
yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
公平调度的目标如下:
- 允许多个用户共享集群资源
- 允许短期临时性作业同长期运行作业分享集群
- 允许集群资源按比例管理,确保集群资源的有效利用
5.6 公平调度的配置
类似于容量调度,公平调度允许分层队列的配置。最高队列的名称是root,所有的队列都是从该队列依次下降。资源被分配给叶队列中被调度执行的应用程序。
类似于容量调度方案,公平调度有四个队列:
- operations
- operations-long
- marketing
- manufacturing
每个队列都可用其自定义策略进行配置。可通过扩展类创建一个新的自定义策略,如下所示
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair. SchedulingPolicy
以下策略可供选择:
- FIFO
- fair(默认):调度决策建立在内存基础上。
- DominantResourceFairness (drf) :基于内存和CPU的调度决策,是由Ghodsi等人开发的。原来的文件被命名为“主导资源公平:对多个资源类型的公平分配。 ”
配置公平调度需更新两套文件:
- $ HADOOP_CONF_DIR /yarn-site.xml中:调度范围选项设置在此文件中。
- Allocation File Listing: 包含此列表的文件位置配置在yarn-site.xml的yarn.scheduler.fair.allocation.file 属性中。实际的队列、其容量及其它属性都配置在该文件中。该文件每10秒将被重新装载,允许运行时即将被应用的队列发生变化。
5.7 yarn-site.xml配置
本节介绍了设置在$ HADOOP_CONF_DIR /yarn-site.xml文件中的调度范围选项。有些配置可通过该文件用于公平调度,如下所示:
For an exhaustive list of configurations, refer to the Hadoop documentation.
- scheduler.fair.allocation.file:分配文件路径。配置文件是指一个描述队列和属性的XML清单,除了某些策略默认值。下节中将会介绍此文件必须以XML格式存在。如果给出一个相对路径,则在类路径(通常包括$ HADOOP_CONF_DIR)中搜索该文件。默认值是fair-scheduler.xml。
- yarn.scheduler.fair.preemption:如果一个队列低于最低资源限制,是否使用抢占。抢占使其他队列中的容器被提前终止,以便把资源提供给未充分利用的队列。记住,它不会导致作业失败的,因为这两个Map和Reduce进程在mapred-site.xml配置文件中都进行了最大的配置尝试。这些参数的默认值是4,这意味着只要同一Map 或 Reduce进程不失败超过四次,该作业就没有失败。但是请注意,抢占在版本2.2.0中是实验性的。默认值是false,且明智的做法是继续在版本2.2.0中保持为false。
- yarn.scheduler.fair.sizebasedweight:决定分配给单个应用程序的资源份额是以大小为基础的,而非无论大小给所有应用提供同等份额。当设置为true时,应用程序是按一的自然对数加总的应用程序请求内存,除以2的自然对数计算的。默认值是false。
5.7 配置文件格式和配置
这是配置在yarn- site.xml文件中的自定义文件。它被用于配置队列及其运行属性,如队列内的最小和最大的资源,重调度策略,子队列和用户级约束。样本配置文件列表如下所示:
<?xml version="1.0"?> <allocations> <queue name="sample_queue"> <minResources>10000 mb,0vcores</minResources> <maxResources>90000 mb,0vcores</maxResources> <maxRunningApps>50</maxRunningApps> <weight>2.0</weight> <schedulingPolicy>fair</schedulingPolicy> <queue name="sample_sub_queue"> <minResources>5000 mb,0vcores</minResources> </queue> </queue> <user name="sample_user"> <maxRunningApps>30</maxRunningApps> </user> <userMaxAppsDefault>5</userMaxAppsDefault> </allocations>
前面的文件显示公平调度支持分层队列。子队列继承父队列属性。子队列也可修改父队列中的任何属性。在该文件中,root标签是allocations,包含了用于配置单个队列的队列标签。配置元件如下所述。
Queue代表队列的属性,包含以下元素:
- minResources:队列有权得到的最小资源,被定义为“X mb,Y cores”。当scheduling Policy属性值为fair,核心规范将被忽略,且份额仅以内存为基础。如果一个队列的最低份额得不到满足,则会在同一父队列的其他队列之前得到资源。
- maxResources:队列有权得到的最大资源,被定义为“X mb,Y cores”。与minResources类似,当schedulingPolicy属性值为fair时,核心规范将被忽略,且份额仅以内存为基础。一个队列不可能会被分配一个容器,这样它的总使用量将超过此限制。
- maxRunningApps:在队列中可执行的应用程序数量上设最大限制。
- weight: 允许集群资源被不按比例共享。默认值是1。如果设为2,队列将获得是默认权重队列两倍的资源。
- schedulingPolicy :为特定队列确定任务的调度策略,如前面所讨论的。允许值是FIFO ,fair和drf。默认值是fair。或者,自定义调度策略,它是一个扩展apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy类的类名。其属性与minResources属性进行交互。例如,在fair配置下,如果它的内存使用低于其最小内存份额,则认为该队列是未得到满足的。在drf配置下,如果有关集群容量主导资源的使用低于该资源的最小份额,则认为该队列是未得到满足的。(主导资源共享将在下节讨论。 )
User代表管理单个用户行为的设置。它包含以下属性:
- maxRunningApps :限制可被一个用户同时运行的应用程序的数量。
- userMaxAppsDefault :适用于其maxRunningApps设置没有明确指定的用户。
- defaultQueueSchedulingPolicy :适用于其schedulingPolicy元素没有明确指定的队列。默认值是fair。
注意 在早期的Hadoop版本中,用于“queue”的词是“pool”。由于其向后兼容性,前述队列元件也可称为池元素。
5.8 确定drf策略中的主导资源份额
Drf策略下,有两种资源类型可被指定:
- 内存,以MB为单位
- 内核中的CPU
受其minResouces和maxResources限制,队列可利用每一资源的不同量。
考虑其资源总量如下的集群:
- 1000 GB
- CPU内核300
假设两个队列: Q1和Q2 。假设这些队列中运行的作业使用如图4-3所示的集群资源。
- Q1:600 GB ,CPU内核100
- Q2:200 GB ,CPU内核200

图4-3 描述服务器资源的队列利用
基于队列之间内存和CPU资源的分布,就可推断出Q1正运行I / O密集型作业,Q2运行CPU密集型作业。 Q1占整个集群内存的60%,CPU内核的33%。 Q2占据集群内存的20 %和CPU内核的66%,因此Q1的主导资源是内存, Q 2的主要资源是CPU内核。
现在假设我们将Q1的minResources属性改为到700,000 MB、50 vcores,Q2的改为100,000 MB、250 vcores。由于这种变化,在DRF调度策略下,两队列都不能满足其最小份额。公平调度试图将一些CPU内存资源从Q1转移到Q2,同时将内存分配从Q2转移至Q1。
5.9 奴隶文件
在一个典型的配置中,集群中有一台机器被指定为主节点,一台被指定为从节点,一台被指定为资源管理器。剩余的机器中,每个都发挥节点管理器以及DataNode的作用。他们被称之为奴隶。这些奴隶的主机名或IP地址都列在$ HADOOP_CONF_DIR /奴隶文件中,每行一个奴隶。
接下来将讨论的机架感知功涉及使Hadoop集群机架感知到关于在从节点上执行的Hadoop和YARN部件。
5.10 机架感知
Hadoop被设计运行在商品机的大型集群上,这些商品机常常被设置为跨越多个物理机架。每个物理机架由于使用低成本的单个开关,可以是一个单点故障,所以Hadoop试图在各自的机架中保存副本。机架感知集群的复制行为指的是在一个机架中存储一个副本,而将其余副本(通常为两个)存储在另一机架中。
5.11 为Hadoop提供网络拓扑
默认情况下,Hadoop不知道任何有关机架节点位置的信息。假定所有的节点属于同一机架:/default-rack。
为了使Hadoop集群机架能够感知,$ HADOOP_CONF_DIR /core-site.xml文件中的下列参数必须进行更新:
- node.switch.mapping.impl:指定一个Java类实现。你可以在此插入自己的类,但默认设置是org.apache.hadoop.net.ScriptBasedMapping。该实现需要用户提供的脚本,该脚本指定在下一项目符号讨论的属性中。
- net.topology.script.file.name:指定该文件的名称和路径,该文件是由前一项目符号中参数的默认设置所指定的Java类执行。这个脚本的作用是记录DNS名称并将其分解为网络拓扑结构的名称。例如,该脚本将采用10.1.1.1和返回/ rack1作为输出。如果该值未设置此属性,则对所有节点名称返回/default-rack的默认值。
- net.topology.script.number.args:用net.topology.script.file.name配置的脚本应该运行的参数的最大数量。每个参数都是一个DNS名称或IP地址。默认值是100。
该设置net.topology.script.file.name的样本列表如表4-1所示。该列表是借鉴以下链接并稍作修改:http://wiki.apache.org/hadoop/topology_rack_ awareness_scripts。
表4-1 net.topology.script.file.name的样本列表
HADOOP_CONF=$HADOOP_HOME/etc/hadoop/
while [ $# -gt 0 ] ; do nodeArg=$1
exec< ${HADOOP_CONF}/topology.data result=""
while read line ; do ar=( $line )
if[ "${ar[0]}" = "$nodeArg" ] ; then result="${ar[1]}"
fi done shift
if[ -z "$result" ] ; then echo -n "/default/rack "
else
echo -n "$result "
fi done
该脚本是对包含从主机名或IP地址到机架名映射的$HADOOP_CONF_DIR/topology.data中文本文件的解析。样本列表如表4-2所示:
表4-2 $HADOOP_CONF_DIR/topology.data的列表
Hadoop1 /dc1/rack1 Hadoop2 /dc1/rack1 Hadoop3 /dc1/rack1 /dc1/rack1 /dc1/rack1 /dc1/rack2
当集群启动时,hdfs-site.xml文件的dfs.hosts属性为只读。如果它被设置为前面一节中提到的$ HADOOP_CONF_DIR/slaves文件的完整路径,则一次调用奴隶文件中的所有主机名调用列表4-1,同时由net.topology.script.number.args属性指定的每次调用中可调用的奴隶数量有限制。如果属性dfs.hosts为空,作为启动过程中NameNode的报告,每个DataNode调用一次列表4-1.
6 集群管理工具
本节回顾了集群管理实用程序,如下所示:
- 检查HDFS损坏的块
- 执行命令行的Hadoop管理
- 从集群中添加/删除节点
- 再平衡HDFS数据
此列表并不详尽,访问以下页面(注意URL中的版本号)获得详尽的命令列表:
http://hadoop.apache.org/docs/r2.2.0/hadoop-project-dist/hadoop-common/CommandsManual.html
所有命令通过调用$HADOOP_HOME/bin/hdfs命令调用。一般调用命令语法如下:
hdfs [–config confdir] [COMMAND] [GENERIC_OPTIONS][COMMAND_OPTIONS]
- -config confdir: 覆盖默认配置目录$HADOOP_CONF_DIR。示例中将不会覆盖该属性。
- COMMAND: 命令的名称(例如:fsck 和dfsadmin)
- GENERIC_OPTIONS: 可传递给作业的通用参数列表。唯一适于本节的是-config<配置文件>,它指定应用程序配置文件,以及-D<属性>=<值>,它允许将属性名称/值对传递到命令。虽然这类似于传递系统属性到Java命令行,请注意语法的差异:–D 和<property>之间有空格。
- COMMAND_OPTIONS: 其它的特定命令参数。
6.1 检查HDFS
文件系统检查(fsck)实用工具用于检查HDFS损坏或缺失的数据块。该命令的语法如下:
hdfs fsck [GENERIC_OPTIONS] <path> [-move | -delete | -openforwrite] [-files [-blocks [-locations |
-racks]]]
表4-6展示了fsck命令的各种命令选项。
表 4-6. fsck 命令选项
属性 值
Path 检查HDFS路径。为检查所有文件,需提供值为 “/”
-move 将损坏文件移到 /lost+found 文件夹
-delete 删除损坏文件
-openForWrite 打印打开要写的文件
-files 打印被检查的文件
-blocks 打印块报告
-locations 打印每个块的位置
-racks 打印数据节点位置网络拓扑。这是替代–locations
样本fsck命令被列在这里:
- bin/hdfs fsck/:为整个文件系统获取报告。输出示例如下:
Connecting to namenode via http://ip-10-139-18-58.ec2.internal:9101 FSCK started by hadoop (auth:SIMPLE) from /10.139.18.58 for path / at Sun Jan 12 16:52:17 UTC 2014 ..Status: HEALTHY Total size: 288324 B Total dirs: 14 Total files: 2 FSCK ended at Sun Jan 12 16:52:17 UTC 2014 in 6 milliseconds
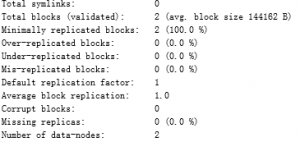
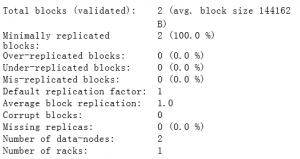
- bin/hdfs fsck / -files: 为HDFS中的所有文件获取报告。输出示例如下:
Connecting to namenode via http://ip-10-139-18-58.ec2.internal:9101 FSCK started by hadoop (auth:SIMPLE) from /10.139.18.58 for path / at Sun Jan 12 16:53:54 UTC 2014 / <dir> /tmp <dir> /tmp/hadoop-yarn <dir> /tmp/hadoop-yarn/staging <dir> /tmp/hadoop-yarn/staging/hadoop <dir> /tmp/hadoop-yarn/staging/hadoop/.staging <dir> /tmp/hadoop-yarn/staging/history <dir> /tmp/hadoop-yarn/staging/history/done <dir> /tmp/hadoop-yarn/staging/history/done/2014 <dir> /tmp/hadoop-yarn/staging/history/done/2014/01 <dir> /tmp/hadoop-yarn/staging/history/done/2014/01/12 <dir> /tmp/hadoop-yarn/staging/history/done/2014/01/12/000000 <dir> /tmp/hadoop-yarn/staging/history/done/2014/01/12/000000/job_1389544292752_0001- 1389544406547-hadoop-streamjob4494792172397765215.jar-1389544533181-19-5-SUCCEEDED- default.jhist 205681 bytes, 1 block(s): OK /tmp/hadoop-yarn/staging/history/done/2014/01/12/000000/job_1389544292752_0001_conf.xml 82643 bytes, 1 block(s): OK /tmp/hadoop-yarn/staging/history/done_intermediate <dir> /tmp/hadoop-yarn/staging/history/done_intermediate/hadoop <dir> Status: HEALTHY Total size: 288324 B Total dirs: 14 Total files: 2 Total symlinks: 0 FSCK ended at Sun Jan 12 16:53:54 UTC 2014 in 8 milliseconds
- bin/hdfs fsck / -files –block: 获取一个块报告。
- bin/hdfs fsck / -files –block –locations: 获取一个块报告,且报告记录有每个块的位置
- bin/hdfs fsck / -files –block –racks: 获取一个块报告,报告记录有承载每个块的机架
注意 在集群使用低谷时期,将fsck命令作为计划任务执行,来主动识别hdFs中的问题,这是一个很好的做法 。
6.2 令行 HDFS管理
Hadoop包括HDFS管理的dfsadmin工具。本节将探讨dfsadmin命令的各种功能。
6.3 HDFS集群健康报告
执行下列命令以获得HDFS集群健康的基本数据。它提供以下有关集群的反馈:NameNode的状态,DataNode的状态,可用磁盘容量,等等。
hdfs dfsadmin -report
上述命令的示例输出如下:
Configured Capacity: 1800711258112 (1.64 TB) Present Capacity: 1800711258112 (1.64 TB) DFS Remaining: 1800710930432 (1.64 TB) DFS Used: 327680 (320 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 ------------------------------------------------- Datanodes available: 2 (2 total, 0 dead) Live datanodes: Name: 10.240.106.239:9200 (domU-12-31-39-04-65-01.compute-1.internal) Hostname: domU-12-31-39-04-65-01.compute-1.internal Decommission Status : Normal Configured Capacity: 900355629056 (838.52 GB) DFS Used: 12288 (12 KB) Non DFS Used: 0 (0 B) DFS Remaining: 900355616768 (838.52 GB) DFS Used%: 0.00% DFS Remaining%: 100.00% Last contact: Sun Jan 12 17:01:33 UTC 2014 Name: 10.96.157.76:9200 (domU-12-31-39-16-9E-A2.compute-1.internal) Hostname: domU-12-31-39-16-9E-A2.compute-1.internal Decommission Status : Normal Configured Capacity: 900355629056 (838.52 GB) DFS Used: 315392 (308 KB) Non DFS Used: 0 (0 B) DFS Remaining: 900355313664 (838.52 GB) DFS Used%: 0.00% DFS Remaining%: 100.00% Last contact: Sun Jan 12 17:01:35 UTC 2014
要获得更详细的数据,则执行以下命令:
hdfs dfsadmin –metasave filename
上述filename的示例列表如下:
16 files and directories, 2 blocks = 18 total Live Datanodes: 2 Dead Datanodes: 0 Metasave: Blocks waiting for replication: 0 Mis-replicated blocks that have been postponed: Metasave: Blocks being replicated: 0 Metasave: Blocks 0 waiting deletion from 0 datanodes. Metasave: Number of datanodes: 2 10.240.106.239:9200 IN 900355629056(838.52 GB) 12288(12 KB) 0.00% 900355616768(838.52 GB) Sun Jan 12 17:21:15 UTC 2014 10.96.157.76:9200 IN 900355629056(838.52 GB) 315392(308 KB) 0.00% 900355313664(838.52 GB) Sun Jan 12 17:21:14 UTC 2014
6.4 增加/删除节点
Hadoop允许新的节点添加到集群。这些节点可用两种属性配置:
- hosts:正如前面章节中所讨论的,它是一个文件路径,文件中列出允许与NameNode通信的节点。
- hosts.exclude: 完全限定路径的文件,其中包含不允许连接到NameNode的主机列表。
要从集群中增加或删除节点,需更新之前的文件,并执行以下命令:
hdfs dfsadmin –refreshNodes
6.5 将HDFS置于安全模式
在启动期间,NameNode会从fsImage和edits日志文件中加载文件系统状态。 NameNode等待DataNodes报告其块,以避免过早地复制那些已经被充分复制的块。此操作期间,NameNode处于安全模式。该状态下,HDFS可被读出,但不向HDFS或块更新。当DataNodes报告了足够量的块信息给NameNode时,NameNode离开该模式。它是由hdfs-site.xml配置文件中的dfs.safemode.threshold.pct参数指定。
HDFS可手动置于安全模式,以阻止对HDFS的修改。该模式下不可执行复制操作,也不允许创建或删除文件。在安全模式中执行任务的命令语法如下:
hdfs dfsadmin –safemode action
该行为可采取以下值:
- enter: HDFS进入安全模式。
- leave: HDFS被迫退出安全模式。
- get: 返回一个字符串,显示当前安全模式状态为ON或OFF。
- wait: 等待,直到安全模式已退出并返回。仅当安全模式关闭时,它适用于需要在HDFS上执行操作的shell脚本 。
6.6 重新平衡HDFS数据
要添加新的节点到Hadoop集群,需遵循以下步骤:
1.安装同一版本的Hadoop,与集群的其他部分应用相同的配置。
2.添加新节点到奴隶文件。该文件通常由dfs.hosts属性指向。
3.启动DataNode,并使其加入集群。
新的DataNode最初不具有任何数据。当新文件添加时,它们被存储在新的DataNode以及现有的DataNodes中。因此该集群目前是不平衡的。平衡器工具能使集群得以重新平衡。
平衡器工具是由类所执行的。
org.apache.hadoop.hdfs.server.balancer.Balancer
这个类的作用是平衡各节点的块,以在一个给定的阈值中实现块的均匀分布,以百分比表示。默认值是10%。
平衡器脚本的语法如下:
bin/start-balancer.sh –threshold utilization-threshold%
一个示例调用是bin/ start-balancer.sh – threshold 5,其向平衡器指出HDFS集群节点必须在利用率为5%的阈值内实现均匀分布。实现较低的阈值需要更长的时间,达到0%是不可能的。这种情况下的节点利用率是指在节点上使用的数据存储量。如果其利用率低于所有节点的平均利用率,则节点未充分利用。相反,如果其利用率高于平均利用率则使用过度。测量节点上整体磁盘的利用率。平衡器工具不考虑块安置。每个节点上块的数目可能有很大的不同,尤其当文件使用自己的块大小而非hdfs-site.xml中dfs.blocksize属性指定的默认块大小 。
当指定的利用阈值目标实现,或出现错误,或无法找到更多候选块移动以实现更好的平衡时,平衡器自动终止。通过由管理员运行bin/ stop-balancer.sh,平衡器总是可以安全终止。
平衡脚本通常是在低集群利用率的情况下运行。然而,当其需要与集群作业的其余部分一起运行时,可能存在这样的担忧:它使用大量的带宽,从而对其它作业产生不利影响。可使用dfs.datanode.balance.bandwidthPerSec配置参数的属性来限制每秒每个DataNode用来平衡其内存的字节数。默认值是1,048,576(1 MB/秒)。一般建议使用10%的网络传输速度。例如,在一个1 GB /秒的网络中,使用10MB/秒。
6.7 从HDFS复制大量数据
要求将数据从HDFS移动到另一集群(用于备份),或从另一分布式存储,如亚马逊S3移动到HDFS,这都是常见的现象。Hadoop的安装附带一个分布式副本(distcp)实用程序。以下是discp命令的语法:
bin/hadoop distcp srcdir destdir
下面是参数:
- srcdir:源目录的完全限定路径。当数据被从一个集群移动到另一集群时(例如:/user/mydir, hdfs://namenode1:9000/user/mydir),该路径甚至可包括NameNode主机和端口。
- destdir: 目标目录的完全限定路径。当数据被从一个集群移动到另一集群时(例如:/user/mydestdir, hdfs://namenode2:9000/user/mydir),该路径甚至可包括NameNode主机和端口
- S3路径可被指定为s3://bucket-name/key。
前述路径被假定为目录,并从源目录递归复制到目标目录。distcp工具启动MapReduce作业,以将数据从源目录平行复制到目标目录。
7 总结
本章从总体上探讨了Hadoop系统,尤其是HDFS的基本详细信息。描述了Hadoop中的各种配置文件和多租户,以及使用的各种调度。从非常基本的FIFO调度开始,了解了更复杂的容量和公平调度,以及如何利用它们来最大限度地提高企业的集群利用率。最后,讨论了几个HDFS管理工具。本章的目标是帮助你领会Hadoop的物理和操作设计。
有了这方面的知识,你就可以在Hadoop系统上执行基本管理任务。此外,了解了Hadoop的内部,你还可以调试棘手的编程问题,设计基于Hadoop的应用程序。

Comment