
ORACLE的分区(Partitioning Option)是一种处理超大型表的技术。分区是一种“分而治之”的技术,通过将大表和索引分成可以管理的小块,从而避免了对每个表作为一个大的、单独的对象进行管理,为大量数据提供了可伸缩的性能。分区通过将操作分配给更小的存储单元,减少了需要进行管理操作的时间,并通过增强的并行处理提高了性能,通过屏蔽故障数据的分区,还增加了可用性。
在Oracle 11g中,Oracle支持三种普通分区以及两种组合分区。
ORACLE的分区表的划分方法包括:按字段值进行划分的范围分区(RANGE);按字段的HASH 函数值进行的划分HASH 分区;按字段值列表进行划分的列表 (LIST) 分区方法。
Oracle支持两种组合分区,分别是先按范围划分,再按HASH 划分的RANGE-HASH组合分区;另一种是先按范围进行分区,再按LIST进行子分区的RANGE-LIST组合分区。
管理员可以指定每个分区的存储属性,分区在宿主文件系统(Storage subsystem)中的放置情况,这样便增加了对超大型数据库的控制粒度(granularity)。分区可以被单独地删除、卸载或装入、备份、恢复,因此减少了需要进行管理操作的时间。
还可以为表分区创建单独的索引分区,从而减少了需要进行索引维护操作的时间。此外,还提供了种类繁多的局部和全局的索引技术。分区操作也可以被并行执行。
分区技术还提高了数据的可用性。当部分数据由于故障或其它原因不可用时,其它分区内的数据可用不收影响继续使用。
分区对应用是透明的,可以通过标准的SQL语句对分区表进行操作。Oracle 的优化器在访问数据时会分析数据的分区情况,在进行查询时,那些不包含任何查询数据的分区将被忽略,从而大大提高系统的性能。
Range分区
范围分区是最常使用的一种分区。
分区介绍
范围分区根据分区字段(Partition Key)的值实现数据和分区的映射。
分区的字段可以是一个或多个字段(an ordered list of columns)组合。分区字段可以是除ROWID,LONG,LONG,LOB TIMESTAMP WITH TIME ZONE之外其他数据库内嵌数据类型。
在创建范围分区时,应指定各分区的值域和各个分区的存储特性。
适用情景
范围分区特别适用于待处理分区数据在分布上具有逻辑范围或范围值域,如数据在按月份进行分区。当数据能够在所有分区上均匀分布时范围分区能获得非常好的性能,若因数据分布不均匀而导致各个分区数据在数据量上变化很大,则应考虑采用其他的分区方法。
范围分区也适用于数据随时间变化而增长的情景。
范围分区亦适用于数据归档和定期维护的需要,若能结合业务的需要定义好范围分区可实现按分区归档和数据维护的需要。
通过设定分区的值域(partition bond),范围分区可以显式地指定数据的分布。
示例
分区字段为单一字段
CREATE TABLE sales_range
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_amount NUMBER(10),
sales_date DATE)
COMPRESS
PARTITION BY RANGE(sales_date) —- partition key
(PARTITION sales_jan2000 VALUES LESS THAN(TO_DATE(’02/01/2000′,’DD/MM/YYYY’)),
PARTITION sales_feb2000 VALUES LESS THAN(TO_DATE(’03/01/2000′,’DD/MM/YYYY’)),
PARTITION sales_mar2000 VALUES LESS THAN(TO_DATE(’04/01/2000′,’DD/MM/YYYY’)),
PARTITION sales_apr2000 VALUES LESS THAN(TO_DATE(’05/01/2000′,’DD/MM/YYYY’)));
分区字段为单一字段
CREATE TABLE sales
( invoice_no NUMBER,
sale_year INT NOT NULL,
sale_month INT NOT NULL,
sale_day INT NOT NULL )
PARTITION BY RANGE (sale_year, sale_month, sale_day) –partition key
( PARTITION sales_q1 VALUES LESS THAN (1999, 04, 01)
TABLESPACE tsa,
PARTITION sales_q2 VALUES LESS THAN (1999, 07, 01)
TABLESPACE tsb,
PARTITION sales_q3 VALUES LESS THAN (1999, 10, 01)
TABLESPACE tsc,
PARTITION sales_q4 VALUES LESS THAN (2000, 01, 01)
TABLESPACE tsd );
Hash分区
哈希分区是Oracle支持的、通过哈希算法来实现记录和分区映射的一种分区方法。
分区介绍
哈希分区是实现数据在各个分区上均匀分区的最佳分区方式,哈希分区可以保证各个分区大小近似,记录数相当。
Oracle所采用的哈希算法是一种线性算法,即哈希分区不是根据业务规则或者数据本身的逻辑来分布数据,哈希分区数应该是2的指数(2,4,6,8,…)。
分区字段(partition key) 可以是单一字段或者字段列表(不能超过16个字段)。
分区字段不支持ROWID,UROWID, LONG, LOB等数据类型。
在创建哈希分区时,可以通过individual_hash_partitions 的方式单独指定每个分区的特征;

在创建哈希分区时,也可以通过hash_partitions_by_quantity的方式指定哈希分区数(partition quantity),如下图
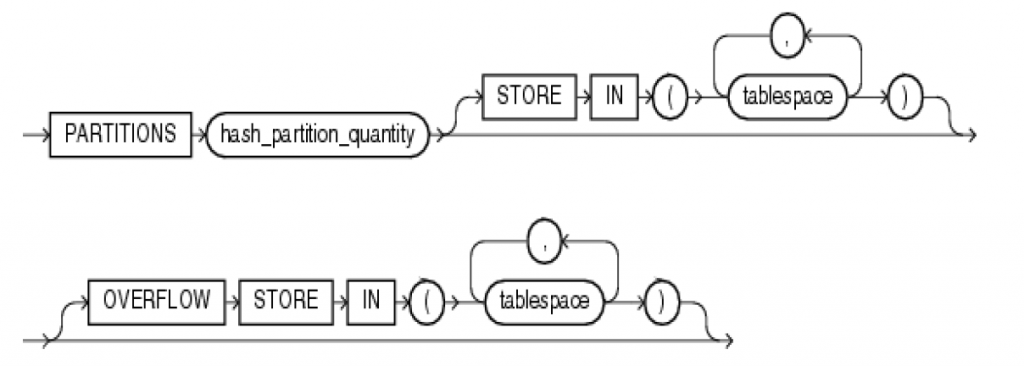
当数据与时间的关系不紧密时,哈希分区可用于替代范围分区。
因为数据的分布完全由哈希算法决定,因此采用哈希分区主要是希望通过将数据均匀分布到各个分区以获得性能上的提升。
由于哈希分区的实现是基于哈希函数,因此不支持如删除哈希分区、合并哈希分区以及拆分哈希分区操作等一些分区操作。但支持增加、交换、移动、缩减等分区操作。
示例
individual_hash_partitions
hash_partitions_by_quantity
下面的示例是创建一个4个HASH 分区表的例子,并为各个分区指定了表空间。
CREATE TABLE scubagear
( id NUMBER,
name VARCHAR2 (60))
PARTITION BY HASH (id) –哈希分区
PARTITIONS 4 –分区数
STORE IN (gear1, gear2, gear3, gear4);
List分区
List分区是Oracle 9i引入的一种分区方式。
分区介绍
LIST分区是指通过为分区字段(partition key)指定一组离散的值来实现的。
可以指定缺省LIST分区,这样不满足任何分区条件的记录可以存储到缺省的分区。
分区字段(Partition Key)不能是LOB类型,也不能是多个字段的组合。
适用情景
当需要显式地控制数据与分区的映射关系时应采用LIST分区。
List分区以可以实现将无关、无序的离散数据集组合到一个分区。
示例
CREATE TABLE sales_list
(salesman_id NUMBER(5),
salesman_name VARCHAR2(30),
sales_state VARCHAR2(20),
sales_amount NUMBER(10),
sales_date DATE)
PARTITION BY LIST(sales_state) –范围分区
(PARTITION sales_west VALUES(‘California’, ‘Hawaii’),
PARTITION sales_east VALUES (‘New York’, ‘Virginia’, ‘Florida’),
PARTITION sales_central VALUES(‘Texas’, ‘Illinois’),
PARTITION sales_other VALUES(DEFAULT)); –缺省分区
Composite分区:Range-Hash
在11g 中,Oracle提供了2中组合分区方式,即Range-Hash分区和Range-List分区。
分区介绍
Oracle首先通过指定值域的方式对数据进行了范围分区,然后在分区的基础上按哈希算法进一步划分。Range-Hash分区兼具范围分区和哈希分区的优势。
适用情景
适用于特大型的数据表。
数据在分区的级别上实现了按值域范围划分,同时在分区内又通过哈希函数将数据均匀分布到各个子分区内。
在子分区上也可实现并行数据操纵操作(PDML)。
支持分区排除(Partition-Pruning)和Partition-Wise Join。
示例
CREATE TABLE scubagear
(equipno NUMBER, equipname VARCHAR(32), price NUMBER)
PARTITION BY RANGE (equipno) –第一层Range分区
SUBPARTITION BY HASH(equipname) –第二层Hash分区
SUBPARTITIONS 8 STORE IN (ts1, ts2, ts3, ts4) –指定哈希子分区数
(PARTITION p1 VALUES LESS THAN (1000),
PARTITION p2 VALUES LESS THAN (2000),
PARTITION p3 VALUES LESS THAN (MAXVALUE));
Composite分区:Range-List
Range-List是一种实现2层分区的分区技术。
分区介绍
数据首先通过指定值域的方式进行范围分区,然后在分区的基础上通过指定离散的值来进一步划分分区内无序、无关的数据。
适用情景
特大型数据表可考虑采用。
要求分区(第一级)可以通过划分子分区的方式分布到不同的表空间和存储介质上以充分利用MPP和多通道I/O处理能力,以进一步提升性能。
支持分区排除(Partition-Pruning)和Partition-Wise Join。
示例
CREATE TABLE quarterly_regional_sales
(deptno NUMBER, item_no VARCHAR2(20),
txn_date DATE, txn_amount NUMBER, state VARCHAR2(2))
PARTITION BY RANGE (txn_date) –第一层 范围分区
SUBPARTITION BY LIST (state) –第二层 列表分区
SUBPARTITION TEMPLATE( –指定子分区特征
SUBPARTITION northwest VALUES (‘OR’, ‘WA’) TABLESPACE ts1,
SUBPARTITION southwest VALUES (‘AZ’, ‘UT’) TABLESPACE ts2,
SUBPARTITION northeast VALUES (‘NY’, ‘VM’, ‘NJ’) TABLESPACE ts3,
SUBPARTITION southeast VALUES (‘FL’, ‘GA’) TABLESPACE ts4,
SUBPARTITION northcentral VALUES (‘SD’, ‘WI’) TABLESPACE ts5,
SUBPARTITION southcentral VALUES (‘NM’, ‘TX’) TABLESPACE ts6)
(PARTITION q1_1999 VALUES LESS THAN(TO_DATE(‘1-APR-1999′,’DD-MON-YYYY’)),
PARTITION q2_1999 VALUES LESS THAN(TO_DATE(‘1-JUL-1999′,’DD-MON-YYYY’)),
PARTITION q3_1999 VALUES LESS THAN(TO_DATE(‘1-OCT-1999′,’DD-MON-YYYY’)),
PARTITION q4_1999 VALUES LESS THAN(TO_DATE(‘1-JAN-2000′,’DD-MON-YYYY’)));
分区原则
下面主要列出在进行表分区常遵循的一些设计原则。这些原则也适用于确定哪些表或者索引应考虑分区。
表分区原则
表的大小
对于大表进行分区,将有益于大表操作的性能和大表的数据维护。通常当表的大小超过1.5GB-2GB,或对于OLTP系统,表的记录超过1000万,都应考虑对表进行分区。
数据访问特性
若基于表的大部分查询应用,只访问表中少量或者部分数据,对于这样表进行分区,可充分利用分区排除无关数据查询 (partition-pruning) 的特性。
数据维护
某些表的数据维护,经常按时间段删除成批的数据或者按特定规则进行数据归档,例如按月删除历史数据。对于这样的表需要考虑进行分区,以满足维护的需要。因为删除(Delete)大量的数据,对系统开销很大,有时甚至是不可接受的。
只读数据
如果一个表中大部分数据都是只读数据,通过对表进行分区,可将只读数据存储在只读表空间中,对于数据库的备份是非常有益的。
并行数据操作 (Parallel DML)
对于经常执行并行操作 (如 Parallel Insert, Parallel Update 等) 的表应考虑进行分区。
表的可用性
当对表的部分数据可用性要求很高时,应考虑进行表分区。
索引分区
索引分区原则
索引分区与数据表分区的关系
对表进行分区的规则同样适用对索引进行分区。
表(无论分区与否)上的索引可以是分区的也可以是非分区的。
分区表可以有分区的或者不分区的B-Tree索引。
索引分区设计适当,也可以提高索引的可管理性、应用性能和可用性。
索引分区介绍
Oracle提供的索引分区类型
Oracle 提供了如下三种分区索引:
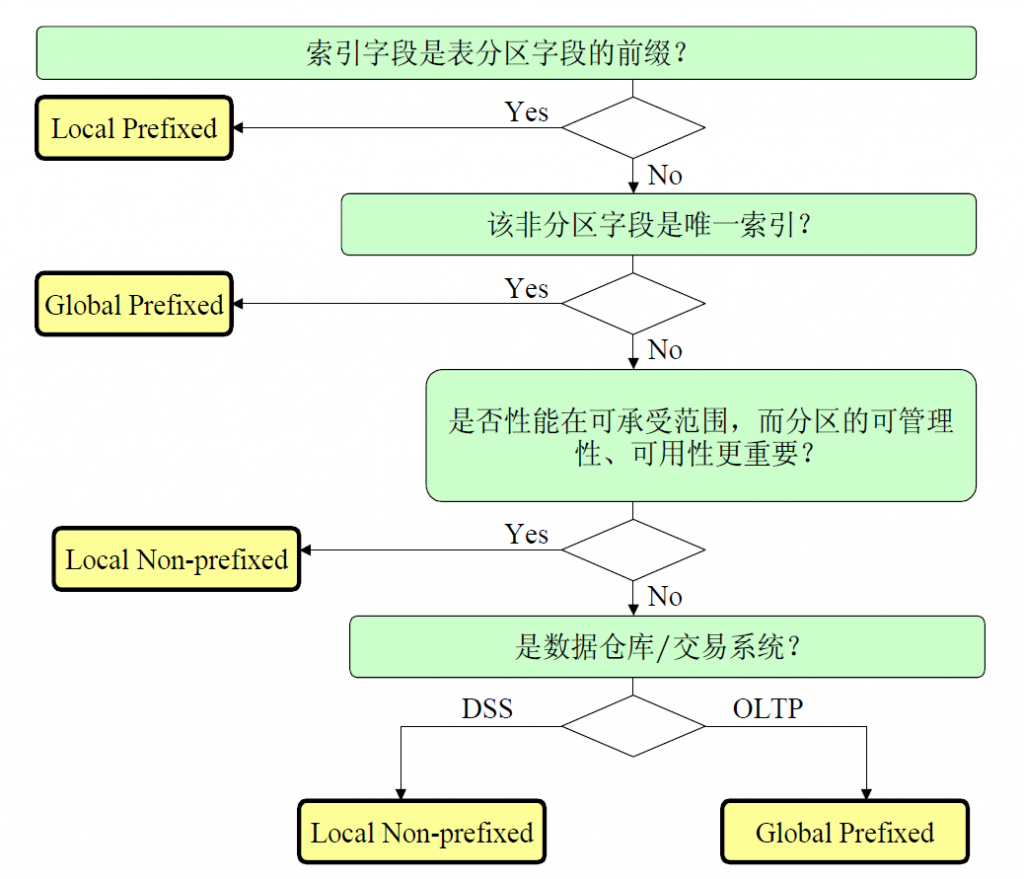
Local Index
1. Local Prefixed Index
2. Local Non-Prefixed Index
Global Prefixed Index
Local Index指的是索引分区内的索引键值指向的记录都对应到基表的一个分区,即索引分区和基表分区是equipartitioned(分区一一对应)。
Global Index是指索引分区与表分区相互独立,不存在索引分区和表分区之间的一一对应关系
Local Index
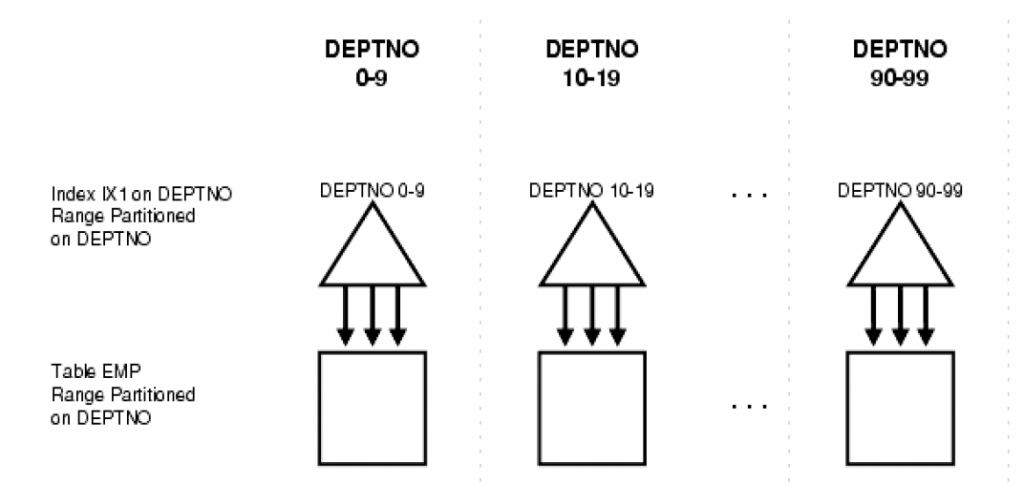
Local Prefixed Index
若分区索引的partition key 是基表(Base table)的partition key的严格左前缀,则称之为Local Prefixed Index。
如下表中,表EMP按DEPTNO进行范围分区,表上索引IX1(基于字段DEPTNO)同样按DEPTNO进行分区,使得索引分区和表分区一一对应。
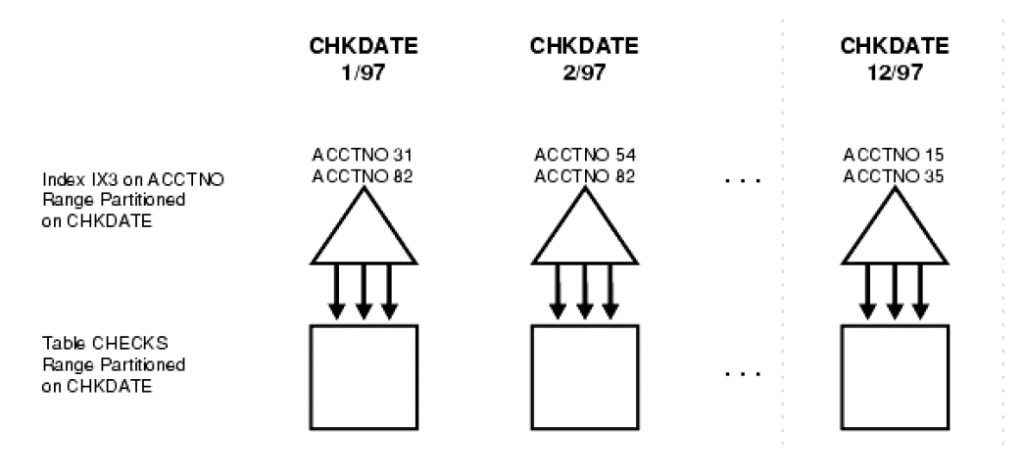
Local Non-prefixed Index
若索引分区的partition key不是基表partition key的严格左前缀(left prefix),则称之为Local Non-prefixed Index。
如下图中,数据表CHECKS基于字段CHKDATE进行了范围分区(Range),但是范围分区索引IX3(基于ACCTNO字段)则采用了ACCTNO进行分区,而ACCTNO不是CHKDATE的左前缀。
Global Prefixed Index
全局分区索引
若一个全局分区索引按其索引字段的严格左前缀进行分区则称之为Global Prefixed Index。反之,若全局分区索引不采用其索引字段的左前缀进行分区则称为Global Non-prefixed Index。Oracle不支持采用Global Non-prefixed Index。
例:假设索引基于字段(A、B、C),则可以采用(A、B、C)、(A、B)、(A、C)或者A作为全局分区的Partition Key;但不可以采用(B、C)、B或者C作为Partition Key。
Oracle支持两种Global Partition Index,分别是按Range或Hash进行全局索引划分,如下图:
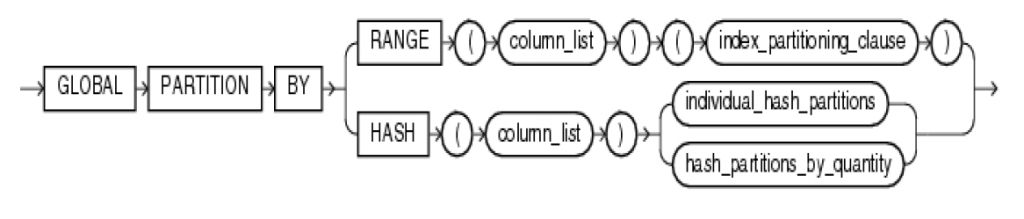
Global Partition By Range
如下图,表EMP按字段DEPTNO进行了Range分区,而基于EMPNO字段的全局分区索引IX03则按EMPNO字段进行了Range分区。每个索引分区存储的键值可以指向底层表的任意数据分区。

Global Partition By Hash
在以HASH进行全局分区的索引中,每个索引分区包含由Oracle HASH函数所确定的键值对。
采用HASH全局分区索引,索引键值被HASH按分区字段(Partition Key)分散到不同的分区上,有效地降低了竞争和提高了性能。包含有“=”或者“IN”等条件子句的查询能够有效地利用全局HASH索引分区的特性,在以下两种情景尤其适用:
1. 在并发多用户应用(OLTP)中若索引的部分页节点数据库存在竞争,则采用HASH进行全局索引分区能有效提高性能;
2. 若索引所对应的索引字段在应用上存在单调增的特性,则容易导致索引一直进行右扩,索引树严重不均衡,最右端的索引块容易成为“热点”,导致性能下降;
如何确定索引类型
上述索引分别适应于不同的性能和数据管理需求,一般可通过下图所定义的规则,可确定分区索引类型:

Comment