
SHOUG成员 – ORACLE ACS高级顾问罗敏
Oracle集群数据库RAC(Real Application Cluster)自Oracle公司在2001年 9i版本推出以来,经过10g、11g和最新的12c等多个版本的发展,产品已经得到不断发展和稳定,尤其在国内银行、电信、政府、制造等诸多行业得到了广泛、深入的应用。
但是,作为保障数据库系统高可用性的重要产品,却时常出现宕机、挂起等故障。究其原因,与RAC自身版本和补丁、主机和操作系统环境、网络环境,以及与应用等多方面都有关系。
如何遵循Oracle公司RAC实施方法论和最佳实践经验,合理组织RAC的实施,确保RAC运行的稳定性,同时充分发挥RAC在性能、扩展性等方面的作用,是本章的宗旨。
本章将结合一些具体案例来叙述RAC实施方法论和最佳实践经验,并在RAC高可用性、RAC运维管理等领域展开一些深入介绍,希望能给大家在RAC实施过程中起到抛砖引玉的作用。
客户哑口了
某典型故障
某日,我接到某移动公司DBA发过来的邮件,描述了其RAC数据库两次出现宕机的情况。邮件要点如下:
- 系统环境
某关键业务系统运行在 IBM AIX 5.3,数据库为两节点10.2.0.4.12 RAC环境,存储技术采用裸设备,即采用IBM HACMP软件。
- 故障现象及初步原因分析
在5月8日和6月20日由CRS发起了主机重启,从数据库的日志来看, vote disk心跳超时导致重启的,但是从主机上看,当时系统并未发现异常。由于本次重启,在主机侧未发现任何异常,IBM主机工程师认为是当时主机繁忙,在短时间内未响应,导致数据库误认为主机已经异常或者HANG住了。
IBM工程师进一步分析由于HACMP和Oracle Clusterware心跳检测参数设置不匹配,是导致宕机的一个重要因素。其中HACMP心跳检测参数为600秒,而CRS缺省为30秒。
即IBM工程师认为是Clusterware检测参数设置过小,导致Clusterware过于敏感了,应用软件压力大点,Clusterware在30秒中未检测到对方心跳,就以为对方宕机或 HANG住了。
- 初步解决方案
为了避免此问题,IBM公司的ORACLE数据库工程师建议将misscount的值改动到大于HACMP的心跳超时的值。这样的话,一旦主机有问题将由HACMP进 行重启,不会由数据库来发动重启,而且在他们实施的案例中,修改过这个参数之后,这个问题就避免了。
- 客户提出的问题
如果修改这个参数的值 为600秒,会导致数据库出现什么问题,从经验来看,该值一般设置为多大合适?
Oracle官方建议
仅分析上述邮件内容,就感觉该问题涉及的层面比较多,既可能与应用压力过大相关,也与HACMP和Clusterware底层参数设置相关,更与整个系统架构相关。为此,我首先在Metalink中查询了好几篇关于CSS参数设置相关的文档,特别是《CSS Timeout Computation in Oracle Clusterware [ID 294430.1]》。在此文档中,Oracle总体建议是谨慎调整MISSCOUNT参数。例如,在该文档的“CONSIDERATIONS WHEN CHANGING MISSCOUNT FROM THE DEFAULT VALUE”一节中,特别指出:
“ … … 5. An increase in misscount to compensate for i/o latencies directly effects reconfiguration times for network failures. The network heartbeat is the primary indicator of connectivity within the cluster. Misscount is the tolerance level of missed 'check ins' that trigger cluster reconfiguration. Increasing misscount will prolong the time to take corrective action in the event of network failure or other anomalies effecting the availability of a node in the cluster. This directly effects cluster availability. … … 7. Do not change default misscount values if you are running Vendor Clusterware along with Oracle Clusterware. The default values for misscount should not be changed when using vendor clusterware. Modifying misscount in this environment may cause clusterwide outages and potential corruptions. … … ”
可见,第5条大意是指调高misscount,一旦网络出现故障,会增加集群重组的时间,重组时间越长,将影响集群高可用性。
第7条更是明确说明,当Clusterware与HACMP等操作系统厂商的集群软件混用时,建议不要修改misscount缺省值,否则会导致集群宕机等严重故障。
另外,针对该问题,Oracle技术支持部门在SR 3-7483242251、SR 3-7412760111中也明确指出misscount值不建议进行修改。其中一个理由是misscount值调大,甚至超过HACMP设置的600秒,HACMP其实并不能有效检测出心跳故障,反而增加 RAC运行风险。
我的远程分析和建议
Oracle官方建议既然如此,那客户系统宕机原因究竟何在,又如何解决呢?由于在远程无法得到进一步信息,于是,我提出了如下更进一步建议:
第一,如果如IBM工程师所言,由于应用压力过大,导致心跳无法正常检测,最终某个节点重启。那么,对应用进行专题和持续的优化才是解决该问题根本。
第二,系统目前的技术架构是:IBM HACMP + 10g Clusterware + 10g RAC。建议考虑升级到11g,并采用 11g GI(Clusteware + ASM) + 11g RAC的技术架构。针对该问题的好处是不再涉及IBM HACMP,技术架构更简洁,问题也更容易诊断,而且在某些平台如LINUX等,misscount参数不再需要设置。
第三,不知道XX移动10g RAC当年实施的详细情况。如果按照Oracle公司的RAC实施方法论,我们Oracle服务团队会提供更专业的RAC实施,例如在RAC最佳实践经验中,我们会针对不同平台提供各种参数的合理配置,包括操作系统、网络、存储、Clusterware、数据库初始化参数等。
客户当场哑口了
就在我们和客户通过邮件沟通后不久,我们参加了客户组织的由多方人员参与的问题讨论会。在会上,我们首先了解到其实两次宕机时,数据库服务器的压力并不是很大,排除了先前分析的是由于应用压力过大,导致Clusterware无法检测到心跳,而最终导致宕机的原因分析。
接下来,几方又回到是否调整Clusterware的misscount参数进行讨论了,我们Oracle技术人员坚持Oracle官方的建议,即保持缺省值为30秒,而IBM工程师则说根据他们的实施经验,应该调大,避免Clusterware检测过于敏感。
就在几方相持不下,各持己见时。忽然间,不知道是谁问了客户,你们心跳线是直连的,还是经过交换机?客户回答:直连的。哇,Oracle技术人员一下炸开了锅: Oracle 10g以后版本不支持心跳线直连了!
我也在一旁为自己的先见之明而暗自得意,我回复邮件的第三条不就是在怀疑客户可能没有遵循Oracle RAC最佳实践经验吗?喏,以下就是在《RAC: Frequently Asked Questions [ID 220970.1]》中,Oracle关于不支持心跳线直连的官方回答和原因解释:
“Is crossover cable supported as an interconnect with RAC on any platform ?
-
CROSS OVER CABLES ARE NOT SUPPORTED. The requirement is to use a switch:
Detailed Reasons: 1) cross-cabling limits the expansion of RAC to two nodes 2) cross-cabling is unstable:
-
a) Some NIC cards do not work properly with it. They are not able to negotiate the DTE/DCE clocking,
-
and will thus not function. These NICS were made cheaper by assuming that the switch was going to have the clock. Unfortunately there is no way to know which NICs do not have that clock.
-
b) Media sense behaviour on various OS's (most notably Windows) will bring a NIC down when a cable is disconnected.
-
Either of these issues can lead to cluster instability and lead to ORA-29740 errors (node evictions).
”
总之,这是Oracle官方根本不支持的配置,不用再对上述内容进行翻译和详细解释了。出了问题,Oracle公司当然没有责任和义务进行分析和解释。客户这下子彻底哑口了。估计当年RAC安装实施的时候,可能没有在环境准备、网络配置等方面进行深入细致的研究和部署,也没有全面研究Oracle RAC有关最佳实践经验。
现在怎么办?赶紧将私网线由直连改成通过交换机进行连接吧。客户DBA又一次有苦难言,原因是网络配置是网络部规划的,现在交换机端口都插满了,需要增加交换机并进行级联,DBA需要协调更多部门和资源进行调整。DBA最后无奈地说:“不搞了,再撑几个月吧,反正系统要迁移到新服务器,并升级到11g了,但愿这几个月不再出事了吧。”大家在一片笑声中一哄而散了。
RAC实施方法和实施内容
本章以上述案例作为开篇,并非要刨根问底地深究HACMP和Clusterware的心跳检测参数的内部细节,而是想说明RAC实施方法和最佳实践经验的重要性。的确,作为Oracle数据库最高端产品的RAC系统,一方面给客户IT系统,特别是数据库系统的高可用性、高性能、可扩展性提供了良好的技术基础架构,另一方面,由于其自身多个技术层面的复杂性,特别是对操作系统、网络等环境要求较高 ,因此RAC本身也成了一个高贵而脆弱的东西,也成了客户经常诟病的对象:“我们使用你们RAC本来是保障高可用性的,没想到你们RAC自己这么娇气,动不动就宕机了。”
如何高质量地实施Oracle RAC架构,并降低运行风险呢?遵循Oracle公司官方提出的RAC实施方法和最佳实践经验,就是一条确保成功的有效途径。
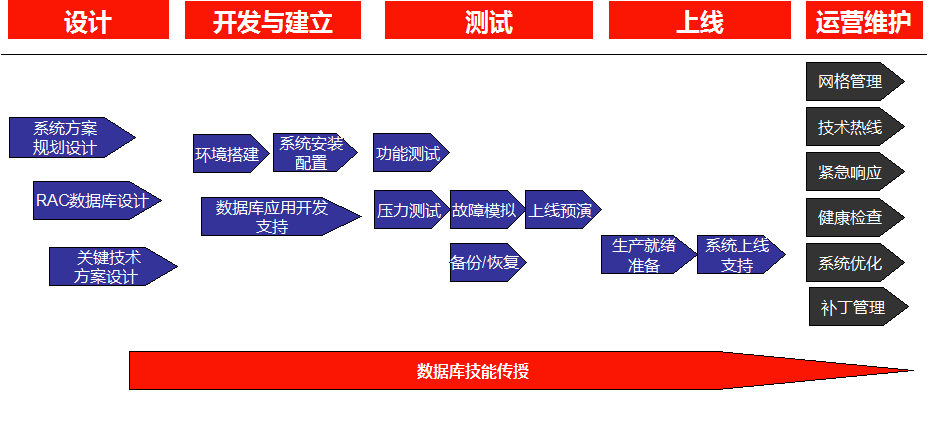
Oracle 11g RAC实施解决方案是一种面向Oracle RAC客户群体的高级客户服务,提供从设计,安装、配置、优化,运维支持以及技能传授等服务。通过对用户的系统数据库和应用环境的深入了解,以及专业的技术应用,Oracle的11g RAC实施解决方案可以帮助用户提高关键业务系统的高可用性、高扩展性,高效、稳定地提供关键业务服务。Oracle在RAC系统实施管理生命周期各个阶段提供不同的服务协助用户高效的管理 11g RAC系统。主要服务内容包括:
- 11g RAC实施方案总体规划
- 11g RAC数据库系统设计
- 11g RAC环境搭建和配置
- 11g RAC系统综合测试
- 11g RAC系统上线支持协助
- 11g RAC系统管理技能传授
- 11g RAC系统性能优化支持
- 11g RAC系统健康检查和问题诊断解决
RAC实施方法论已广泛地为Oracle国内外客户所采用和实践,并在实践中不断得到丰富和发展。对加快项目实施,同时可减少项目实施风险起到了非常好的指导作用。其主要流程和内容如下:
下面我们将基于Oracle RAC实施方法论,并结合某案例,介绍RAC一个重要特性:高可用性方案的设计和测试。
18.3 11g RAC高可用性方案设计
RAC高可用性相关概念
Oracle RAC 11g 提供了实现数据中心高可用性的基础架构。在其基础架构中,具有多种涉及高可用性、负载均衡能力等方面的技术。下面先简要介绍这些技术,再结合XX项目具体需求,分别设计不同的高可用性方案。
- Client Connect-Time Load Balance
客户端连接负载均衡(Client Connect-Time Load Balance)是指在RAC中,客户连接请求在多个协议地址表中随机地选择Listener,在RAC的多个Listener中实现连接负载均衡的特性。
在TNSNAMES.ORA中设置如下参数:
load_balance=on
如果load_balance=off,则Oracle Net在多个协议地址表中顺序选择Listener,直至连接成功。
- Client Connect-Time Failover
客户端连接故障切换(Client Connect-Time Failover)是指在RAC中,当客户连接请求在连接到第一个Listener失败之后,再连接到其它Listener的特性。协议地址表中Listener个数决定了Oracle Net连接失败再尝试的次数。
在TNSNAMES.ORA中设置如下参数:
Failover=on
缺省值为on。如果Failover = off,则Oracle Net只对一个Listener进行连接。
- Server Connect-Time Load Balance
服务器端连接负载均衡(Server Connect-Time Load Balance)是指在RAC中,在多个Instance或Dispatcher中再进行连接负载均衡的特性。
如果采用Dedicated Server模式,Oracle通过如下顺序选择Instance:
- 负载最轻的节点。
- 负载最轻的实例。
如果采用Shared Server模式,Oracle通过如下顺序选择Instance:
- 负载最轻的节点。
- 负载最轻的实例。
- 该实例上负载最轻的Dispatcher
即Oracle通过在服务器端根据节点或实例的负载情况,例如:节点或实例的运行队列长度等,再对客户连接进行负载均衡分配,从而更合理地保证应用吞吐量和处理能力的均衡化。
服务器端连接负载均衡特性主要通过Local_Listener和Remote_Listener等数据库参数的设置,利用Oracle动态服务注册(Dynamic Service Registration)功能,加以实现。
- Transparent Application Failover(TAF)
透明应用故障切换(Transparent Application Failover,TAF)是指在RAC中,当数据库实例出现故障时,已连接到该实例的连接将被Oracle自动切换到正常实例中,并可恢复SELECT操作的特性。TAF主要由OCI提供,因此在客户端具有OCI Driver的情况下,应用将具有这种特性。
在TNSNAMES.ORA中设置如下参数:
Failover_mode
- Service概念
在Oracle 10g/11g中,可针对复杂的应用系统划分为若干服务(Service),并以服务为单位进行整个系统负载的监控和管理。
在10g/11g RAC中,可将各个服务在RAC体系结构中进行应用部署和管理。例如在正常情况下,可将某些服务分配到某个实例中(称之为Preferred Instance),在这些实例出现故障时,这些服务可连接到其它实例中(称之为Available Instance)。
另外,在Oracle的AWR中,可以服务为单位进行性能的监控分析,更有效地进行应用的性能管理。在Resource Manager中,也可以服务为单位进行资源的细粒度分配,能更合理地有效利用系统资源。Oracle的其它工具和产品,例如Oracle Scheduler, Parallel Query, and Oracle Streams Advanced Queuing等均能有效地运用Service概念,进行系统负载的管理工作。
- 单一客户端访问名称SCAN
11g提供了新技术:SCAN。SCAN提供了一个固定的客户端访问名,当RAC增加或者调整某些节点时,客户端无需进行任何变化,从而简化了客户端配置。
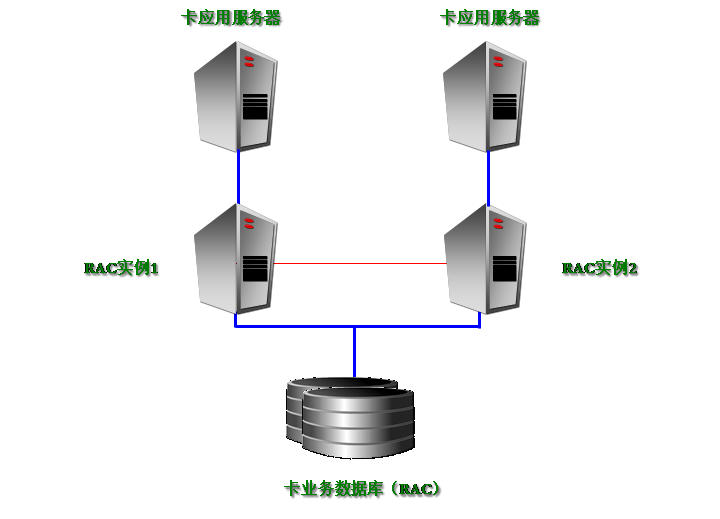
XX系统高可用性方案设计
根据 XX客户对RAC实施的总体需求,并结合XX系统的上述特点, XX系统RAC高可用性方案的示意图如下:
- 不进行SCAN方案设计
由于各系统目前均采用2节点RAC,而且没有配置域名服务器,因此,建议暂时不采用11g的新技术:SCAN。
- 不进行Service方案设计
由于XX项目确定每个应用系统直接部署在一套两节点的RAC环境之中,这样每套RAC系统业务比较单一,因此暂时不考虑Service的设计。
- 负载均衡设计
不采用Client Connect-Time Load Balance、Server Connect-Time Load Balance策略。即在客户端和服务端两级都不进行负载均衡设计。
针对XX应用系统,由于卡表按卡号进行HASH分区,因此应用开发中将通过分析Oracle HASH算法,来选择连接的Oracle实例,有效实现负载均衡,并降低数据访问冲突。
- Client Connect-Time Failover配置
配置Client Connect-Time Failover。确保在某个节点出现各类故障时,新连接请求能Failover到未失效节点。
- TAF配置
配置Transparent Application Failover(TAF)。确保在某个节点出现各类故障时,支持TAF应用的现有连接能Failover到未失效节点。但Oracle不支持JDBC Thin Driver方式程序的TAF。
RAC高可用性方案配置
根据上述方案思路,相关配置如下:
- tnsnames.ora配置
ABROADDB_PERSON = (DESCRIPTION = (LOAD_BALANCE = off) (ADDRESS = (PROTOCOL = TCP)(HOST = p570l0502-vip)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = p570l0505-vip)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = abroaddb) (FAILOVER_MODE = (BACKUP = ABROADDB_CORPOR) (TYPE = SELECT) (METHOD = BASIC) (RETRIES = 180) (DELAY = 5) ) ) ) ABROADDB_CORPOR = (DESCRIPTION = (LOAD_BALANCE = off) (ADDRESS = (PROTOCOL = TCP)(HOST = p570l0505-vip)(PORT = 1521)) (ADDRESS = (PROTOCOL = TCP)(HOST = p570l0502-vip)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = abroaddb) (FAILOVER_MODE = (BACKUP = ABROADDB_PERSON) (TYPE = SELECT) (METHOD = BASIC) (RETRIES = 180) (DELAY = 5) ) ) )
- JDBC Thin Driver连接方式
节点1的JDBC Thin Driver连接方式如下:
url="jdbc:oracle:thin:@(DESCRIPTION= (LOAD_BALANCE=off) (ADDRESS_LIST= (ADDRESS=(PROTOCOL=TCP)(HOST=p570l0502-vip)(PORT=1521)) (ADDRESS=(PROTOCOL=TCP)(HOST=p570l0505-vip)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME=abroaddb)))"
节点2的JDBC Thin Driver连接方式如下:
url="jdbc:oracle:thin:@(DESCRIPTION= (LOAD_BALANCE=off) (ADDRESS_LIST= (ADDRESS=(PROTOCOL=TCP)(HOST=p570l0505-vip)(PORT=1521)) (ADDRESS=(PROTOCOL=TCP)(HOST=p570l0502-vip)(PORT=1521))) (CONNECT_DATA=(SERVICE_NAME= abroaddb)))"
JDBC Thin Driver方式不支持透明应用切换(TAF),因此不需要进行Failover配置。
- 相关参数配置
实例1:
NAME TYPE VALUE -------------------- ------- ------------------- local_listener string LISTENER_P570L0503 remote_listener string
实例2:.
NAME TYPE VALUE -------------------- ------- ------------------- local_listener string LISTENER_P570L0504 remote_listener string
11g RAC高可用性测试
测试目的
- 通过对不同应用系统情况特点分析,制定不同的高可用性方案,为未来其它业务系统的RAC高可用性方案设计提供参考。
- 在应用系统的真实运行环境下,验证Oracle RAC体系结构对各种故障的恢复能力。
- 为客户日常运行维护提供各种故障恢复的可操作性步骤。
测试范围
根据XX项目采用11g R2 RAC的架构特点,并参考Oracle公司研发部门RAC Assurance Team的官方建议,此次高可用性测试方案,将至少包括如下案例:
| 序号 | 测试分类 | 案例编号 |
测试案例 |
| 1. | 系统测试案例 | SYS_01 | 节点正常重启 |
| SYS_02 | OCR主节点异常宕机 | ||
| SYS_03 | 重启宕机节点 | ||
| SYS_04 | 同时重启所有节点 | ||
| SYS_05 | 数据库实例异常宕机 | ||
| SYS_06 | 数据库实例正常宕机 | ||
| SYS_07 | 重启宕机实例 | ||
| SYS_08 | ASM实例异常宕机 | ||
| SYS_09 | 多个数据库实例异常宕机 | ||
| SYS_10 | Listener异常宕机 | ||
| SYS_11 | 拔所有公网线 | ||
| SYS_12 | 拔一根公网线 | ||
| SYS_13 | 拔所有私网线 | ||
| SYS_14 | 拔一根私网线(采用OS或第三方网卡冗余配置) | ||
| SYS_15 | 拔一根私网线(采用Oracle网卡冗余配置) | ||
| SYS_16 | 交换机故障测试(交换机冗余配置) | ||
| SYS_17 | 节点无法访问CSS Voting设备 | ||
| SYS_18 | 节点无法访问OCR 设备 | ||
| SYS_19 | 拔一根存储连接线路 | ||
| SYS_20 | ASM盘丢失 | ||
| SYS_21 | ASM盘恢复 | ||
| SYS_22 | 一个多路复用Voting 设备无法访问 | ||
| SYS_23 | 一个OCR 设备丢失和恢复 | ||
| 2. | Clusterware测试案例 | CRS_01 | CRSD进程宕机 |
| CRS_02 | EVMD进程宕机 | ||
| CRS_03 | CSSD进程宕机 | ||
| CRS_04 | CRSD ORAAGENT RDBMS进程宕机 | ||
| CRS_05 | CRSD ORAAGENT Grid Infrastructure进程宕机 | ||
| CRS_06 | CRSD ORAROOTAGENT进程宕机 | ||
| CRS_07 | OHASD ORAAGENT进程宕机 | ||
| CRS_08 | OHASD ORAROOTAGENT进程宕机 | ||
| CRS_09 | CSSDAGENT进程宕机 | ||
| CRS_10 | CSSMONITOR进程宕机 | ||
| 3. | 其它类 | OTHER_01 | dbverify测试 |
| OTHER_02 | Dbms_file_transfer测试 | ||
| OTHER_03 | 数据库Hang测试 |
限于篇幅,我们将真实环境的测试过程列举若干如下。
SYS_05:数据库实例异常宕机
- 模拟操作测试
采用kill -9 pmon 模拟数据库实例crash
- 预期测试结果
*.inst资源将显示为offline状态。并且集群将会自动重启数据库实例
- 测量过程记录
使用第2节点测试。
kill 掉pmon 进程后 alert 日志显示如下,同时可以发现crs 理解侦测到了实例crash,并且立即尝试重启。
| Sat Jan 19 14:53:07 2013
Shutting down instance (abort) License high water mark = 3 USER (ospid: 27960): terminating the instance Instance terminated by USER, pid = 27960 Sat Jan 19 14:53:12 2013 Instance shutdown complete Sat Jan 19 14:53:13 2013 Starting ORACLE instance (normal) LICENSE_MAX_SESSION = 0 LICENSE_SESSIONS_WARNING = 0 |
最终恢复后状态如下:
| /home/grid-> crsctl stat res -t
——————————————————————————– NAME TARGET STATE SERVER STATE_DETAILS ——————————————————————————– Local Resources ——————————————————————————– ora.LISTENER.lsnr ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pa ONLINE ONLINE w4sd14pb ora.asm OFFLINE OFFLINE w4sd13pa Instance Shutdown OFFLINE OFFLINE w4sd13pb Instance Shutdown OFFLINE OFFLINE w4sd14pa Instance Shutdown OFFLINE OFFLINE w4sd14pb Instance Shutdown ora.gsd OFFLINE OFFLINE w4sd13pa OFFLINE OFFLINE w4sd13pb OFFLINE OFFLINE w4sd14pa OFFLINE OFFLINE w4sd14pb ora.net1.network ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pa ONLINE ONLINE w4sd14pb ora.ons ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pa ONLINE ONLINE w4sd14pb ——————————————————————————– Cluster Resources ——————————————————————————– ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE w4sd13pb ora.cvu 1 ONLINE ONLINE w4sd14pb ora.integ.db 1 ONLINE ONLINE w4sd13pa Open 2 ONLINE ONLINE w4sd14pa Open 3 ONLINE ONLINE w4sd13pb Open 4 ONLINE ONLINE w4sd14pb Open ora.integ.srv14.svc 1 ONLINE ONLINE w4sd13pa ora.integ.srv24.svc 1 ONLINE ONLINE w4sd14pb ora.integ.srv34.svc 1 ONLINE ONLINE w4sd13pb ora.oc4j 1 OFFLINE OFFLINE ora.scan1.vip 1 ONLINE ONLINE w4sd13pb ora.w4sd13pa.vip 1 ONLINE ONLINE w4sd13pa ora.w4sd13pb.vip 1 ONLINE ONLINE w4sd13pb ora.w4sd14pa.vip 1 ONLINE ONLINE w4sd14pa ora.w4sd14pb.vip 1 ONLINE ONLINE w4sd14pb |
- 测试效果总结
数据库实例如果异常crash此时集群会自动监测到状态异常并且尝试重启,时间间隔仅为2秒左右,最终数据库实例会恢复。
CRS_01:CRSD进程crash模拟测试
- 模拟操作步骤
采用 ‘kill -9 crsd进程ID’模拟CRSD进程失效
- 预期测试结果
CRSD进程立刻被重起
- 测量过程记录
在第2节点测试
/home/grid-> ps -fe |grep crsd
root 8345 1 0 Dec 26 ? 288:08 /oracle/grid/grid_home/bin/crsd.bin reboot
grid 28160 28097 0 13:44:08 pts/0 0:00 grep crsd
/home/grid-> exit
logout
w4sd14pa:/#kill -9 8345
服务立刻重启。检查crsd.log日志,可以看到在极短时间内侦测到进程停机,crsd启动并且恢复完成
2013-01-19 13:45:52.711: [ CRSD][1] AuthLoc /oracle/grid/grid_home/auth/crs/w4sd14pa
2013-01-19 13:45:52.711: [ CRSD][1] PE active version: 11.2.0.3.0
2013-01-19 13:45:52.711: [ CRSD][1] PE Engine: NEW
2013-01-19 13:45:52.711: [ CRSD][1] Using OCR batch ops : ENABLED
2013-01-19 13:45:52.711: [ CRSMAIN][1] Creating RTI lock info…
2013-01-19 13:45:52.711: [ CRSMAIN][1] Initializing EVMMgr
2013-01-19 13:45:52.719: [ CRSMAIN][1] Getting local nodename…
[ CLWAL][1]clsw_Initialize: OLR initlevel [70000]
2013-01-19 13:45:53.081: [ CRSMAIN][1] CRSD listening on 10 style E2E port (ADDRESS=(PROTOCOL=tcp)(HOST=192.168.200.22)(PORT=65516))
2013-01-19 13:45:53.086: [ CRSMAIN][1] Starting Threads
2013-01-19 13:45:53.086: [ CRSMAIN][1] CRS Daemon Started.
2013-01-19 13:45:53.086: [ CRSD][1] Connecting to the CSS Daemon
2013-01-19 13:45:53.087: [ CRSD][1] Local CSS Node Number is: 2
2013-01-19 13:45:53.087: [ CRSD][1] Local Css Node Name is: w4sd14pa
2013-01-19 13:45:53.087: [ CRSD][1] Initializing OLR context
2013-01-19 13:45:53.090: [ CRSD][1][F-ALGO] getIpcPath returning (ADDRESS=(PROTOCOL=IPC)(KEY=CRSD_IPC_SOCKET_11))
2013-01-19 13:45:53.090: [CLSFRAME][1] Inited lsf context 600000000167b680
2013-01-19 13:45:53.091: [CLSFRAME][1] Initing CLS Framework messaging
2013-01-19 13:45:53.093: [ CRSD][1][F-ALGO] getIpcPath returning (ADDRESS=(PROTOCOL=IPC)(KEY=CRSD_IPC_SOCKET_11))
2013-01-19 13:45:53.095: [UiServer][1] UI Comms initalize() 1
2013-01-19 13:45:53.095: [CLSFRAME][1] New Framework state: 2
2013-01-19 13:45:53.095: [CLSFRAME][1] M2M is starting…
2013-01-19 13:45:53.096: [ CRSCCL][1]clsCclInit called by process 28836: groupname=CLSFRAME commOptions=8 clusterType=0
2013-01-19 13:45:53.096: [ CRSCCL][1]Software version: 11.2.0.3.0.
2013-01-19 13:45:53.096: [ CRSCCL][1]Active version: 11.2.0.3.0.
2013-01-19 13:45:53.097: [ CRSCCL][1]USING GIPC ============
2013-01-19 13:45:53.097: [ CRSCCL][1]clsCclGipcListen: Attempting to listen on gipcha://w4sd14pa:CLSFRAME_2.
- 测试效果总结
crsd进程一旦异常,数据库集群将会自动进行修复并且重新启动,用时在0-10秒钟之内。整个数据库系统对外提供服务不受影响。
SYS_13:拔所有私网线
- 模拟操作步骤
在RAC的一个节点上,移去该节点上私用网卡的网线,模拟内网中断。
- 预期测试结果
CRS应侦测到集群分裂,节点及数据库实例将会宕机,节点将会被集群逐出。
在两节点RAC集群中,具有最小实例号的节点将继续存活。
在多节点RAC集群中,具有最大子集群的集群将继续存活。
若出现的等大小子集群,则具有最小实例号的子集群将继续存活。在11.2.0.2以前版本,Oracle将直接重新启动另外一个节点。在11.2.0.2以上版本,Oracle将启动“Reboot less Restart”功能,即在被逐出的节点上,Clusterware尝试graceful方式的shutdown。具体过程如下:
- 所有I/O相关的客户进程将被终止,并且所有资源将进行清理。如果该过程没有顺利结束,则被逐出节点将重新启动。
- 如果上述过程顺利结束,并且私网被顺利恢复,则OHASD进程将尝试重新启动该节点的Clusterware和RAC。
即在11.2.0.2以上版本,被逐出的节点可能不会重新启动。
请检查如下日志,查看详细过程:
- $GI_HOME/log/<nodename>/alert<nodename>.log
- $GI_HOME/log/<nodename>/cssd/ocssd.log
- 测量过程记录
A.拔除第2节点1根内网网线,客户已经做了网卡冗余。
无问题
- 拔出第二节点2根网线。
ocssd 侦测到心跳网络断了。
| 2013-01-21 16:03:48.260: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 20049 ms, node 60000000019782c0 { host ‘w4sd14pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-2baaf57c, dstLuid 1dbd895e-2143957a numInf 0, contigSeq 946, lastAck 948, lastValidAck 946, sendSeq [949 : 988], createTime 674995, sentRegister 1, localMonitor 1, flags 0x2408 }
2013-01-21 16:03:51.440: [ CSSD][38]clssnmSendingThread: sending status msg to all nodes 2013-01-21 16:03:51.440: [ CSSD][38]clssnmSendingThread: sent 4 status msgs to all nodes 2013-01-21 16:03:53.270: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 25060 ms, node 6000000001968380 { host ‘w4sd13pa’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-5ae3e8c5, dstLuid 7e9f7ef5-789a1271 numInf 0, contigSeq 1051, lastAck 1059, lastValidAck 1051, sendSeq [1060 : 1109], createTime 674992, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:03:53.270: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 25060 ms, node 6000000001976a60 { host ‘w4sd13pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-1f7b3bea, dstLuid 3ce8135b-0646b272 numInf 0, contigSeq 956, lastAck 957, lastValidAck 956, sendSeq [958 : 1007], createTime 674993, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:03:53.270: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 25059 ms, node 60000000019782c0 { host ‘w4sd14pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-2baaf57c, dstLuid 1dbd895e-2143957a numInf 0, contigSeq 946, lastAck 948, lastValidAck 946, sendSeq [949 : 998], createTime 674995, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:03:55.480: [ CSSD][38]clssnmSendingThread: sending status msg to all nodes 2013-01-21 16:03:55.480: [ CSSD][38]clssnmSendingThread: sent 4 status msgs to all nodes 2013-01-21 16:03:58.280: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 30070 ms, node 6000000001968380 { host ‘w4sd13pa’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-5ae3e8c5, dstLuid 7e9f7ef5-789a1271 numInf 0, contigSeq 1051, lastAck 1059, lastValidAck 1051, sendSeq [1060 : 1119], createTime 674992, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:03:58.280: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 30070 ms, node 6000000001976a60 { host ‘w4sd13pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-1f7b3bea, dstLuid 3ce8135b-0646b272 numInf 0, contigSeq 956, lastAck 957, lastValidAck 956, sendSeq [958 : 1017], createTime 674993, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:03:58.280: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 30069 ms, node 60000000019782c0 { host ‘w4sd14pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-2baaf57c, dstLuid 1dbd895e-2143957a numInf 0, contigSeq 946, lastAck 948, lastValidAck 946, sendSeq [949 : 1008], createTime 674995, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:03:59.520: [ CSSD][38]clssnmSendingThread: sending status msg to all nodes 2013-01-21 16:03:59.520: [ CSSD][38]clssnmSendingThread: sent 4 status msgs to all nodes 2013-01-21 16:04:03.300: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 35090 ms, node 6000000001968380 { host ‘w4sd13pa’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-5ae3e8c5, dstLuid 7e9f7ef5-789a1271 numInf 0, contigSeq 1051, lastAck 1059, lastValidAck 1051, sendSeq [1060 : 1129], createTime 674992, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:04:03.300: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 35090 ms, node 6000000001976a60 { host ‘w4sd13pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-1f7b3bea, dstLuid 3ce8135b-0646b272 numInf 0, contigSeq 956, lastAck 957, lastValidAck 956, sendSeq [958 : 1027], createTime 674993, sentRegister 1, localMonitor 1, flags 0x2408 } 2013-01-21 16:04:03.300: [GIPCHALO][7] gipchaLowerProcessNode: no valid interfaces found to node for 35089 ms, node 60000000019782c0 { host ‘w4sd14pb’, haName ‘CSS_w4sd13p-cluster’, srcLuid 672ea5c7-2baaf57c, dstLuid 1dbd895e-2143957a numInf 0, contigSeq 946, lastAck 948, lastValidAck 946, sendSeq [949 : 1018], createTime 674995, sent
|
随后开始clean up 进程
| 2013-01-21 16:07:16.085: [ CSSD][5]clssgmDestroyProc: cleaning up proc(6000000000c51830) con(0000000000003809) skgpid 8970 ospid 8970 with 0 clients, refcount 0
2013-01-21 16:07:16.085: [ CSSD][5]clssgmDiscEndpcl: gipcDestroy 0000000000003809 2013-01-21 16:07:16.085: [ CSSD][35]clssgmFenceCompletion: (60000000022c22b0) process death fence completed for process 8970, object type 2 2013-01-21 16:07:16.085: [ CSSD][35]clssgmTermShare: (6000000000c519b0) global grock DBINTEG member 1 type 1 2013-01-21 16:07:16.085: [ CSSD][35]clssgmUnreferenceMember: global grock DBINTEG member 1 refcount is 5 2013-01-21 16:07:16.085: [ CSSD][35]clssgmFenceCompletion: (60000000022e60e0) process death fence completed for process 8970, object type 3 2013-01-21 16:07:16.085: [ CSSD][35]clssgmTermMember: Terminating member 2 (6000000000c11330) in grock IGINTEGSYS$BACKGROUND 2013-01-21 16:07:16.085: [ CSSD][35]clssgmUnreferenceMember: global grock IGINTEGSYS$BACKGROUND member 2 refcount is 0 2013-01-21 16:07:16.085: [ CSSD][35]clssgmAllocateRPCIndex: allocated rpc 73 (6000000000883008) 2013-01-21 16:07:16.086: [ CSSD][35]clssgmRPC: rpc 6000000000883008 (RPC#73) tag(49002a) sent to node 1 2013-01-21 16:07:16.086: [ CSSD][35]clssgmFenceCompletion: (600000000232bb40) process death fence completed for process 8970, object type 3 2013-01-21 16:07:16.086: [ CSSD][35]clssgmTermMember: Terminating member 2 (6000000000c11250) in grock IGINTEGSYS$USERS 2013-01-21 16:07:16.086: [ CSSD][35]clssgmUnreferenceMember: global grock IGINTEGSYS$USERS member 2 refcount is 0 2013-01-21 16:07:16.086: [ CSSD][35]clssgmAllocateRPCIndex: allocated rpc 74 (60000000008830b0) 2013-01-21 16:07:16.086: [ CSSD][35]clssgmRPC: rpc 60000000008830b0 (RPC#74) tag(4a002a) sent to node 1 2013-01-21 16:07:16.086: [ CSSD][35]clssgmFenceCompletion: (60000000022c2440) process death fence completed for process 8970, object type 3 2013-01-21 16:07:16.086: [ CSSD][35]clssgmTermMember: Terminating member 2 (6000000000c10c30) in grock IGINTEGALL 2013-01-21 16:07:16.086: [ CSSD][35]clssgmUnreferenceMember: global grock IGINTEGALL member 2 refcount is 0 2013-01-21 16:07:16.086: [ CSSD][35]clssgmAllocateRPCIndex: allocated rpc 75 (6000000000883158) 2013-01-21 16:07:16.086: [ CSSD][35]clssgmRPC: rpc 6000000000883158 (RPC#75) tag(4b002a) sent to node 1 2013-01-21 16:07:16.086: [ CSSD][35]clssgmFenceCompletion: (60000000022c2260) process death fence completed for process 8970, object type 3 2013-01-21 16:07:16.086: [ CSSD][35]clssgmTermMember: Terminating member 2 (6000000000c11410) in grock IGINTEGinteg 2013-01-21 16:07:16.086: [ CSSD][35]clssgmUnreferenceMember: global grock IGINTEGinteg member 2 refcount is 0 |
随后节点被驱逐,状态如下
| /home/grid-> crsctl stat res -t
——————————————————————————– NAME TARGET STATE SERVER STATE_DETAILS ——————————————————————————– Local Resources ——————————————————————————– ora.LISTENER.lsnr ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pb ora.asm ONLINE OFFLINE w4sd13pa Instance Shutdown ONLINE OFFLINE w4sd13pb Instance Shutdown OFFLINE OFFLINE w4sd14pb Instance Shutdown ora.gsd OFFLINE OFFLINE w4sd13pa OFFLINE OFFLINE w4sd13pb OFFLINE OFFLINE w4sd14pb ora.net1.network ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pb ora.ons ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pb ——————————————————————————– Cluster Resources ——————————————————————————– ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE w4sd13pa ora.cvu 1 ONLINE ONLINE w4sd13pa ora.integ.db 1 ONLINE ONLINE w4sd13pa Open 2 ONLINE OFFLINE 3 ONLINE ONLINE w4sd13pb Open 4 ONLINE ONLINE w4sd14pb Open ora.integ.srv14.svc 1 ONLINE ONLINE w4sd13pa ora.integ.srv24.svc 1 ONLINE ONLINE w4sd14pb ora.integ.srv34.svc 1 ONLINE ONLINE w4sd13pb ora.oc4j 1 OFFLINE OFFLINE ora.scan1.vip 1 ONLINE ONLINE w4sd13pa ora.w4sd13pa.vip 1 ONLINE ONLINE w4sd13pa ora.w4sd13pb.vip 1 ONLINE ONLINE w4sd13pb ora.w4sd14pa.vip 1 ONLINE INTERMEDIATE w4sd13pa FAILED OVER ora.w4sd14pb.vip 1 ONLINE ONLINE w4sd14pb |
相应的,根据日志显示已经进入graceful shutdown阶段。
| 2013-01-19 15:07:02.289: [ CSSD][39]clssnmDoSyncUpdate: Starting cluster reconfig with incarnation 250911949
2013-01-19 15:07:02.289: [ CSSD][39]clssnmSetupAckWait: Ack message type (11) 2013-01-19 15:07:02.289: [ CSSD][39]clssnmSetupAckWait: node(2) is ALIVE 2013-01-19 15:07:02.289: [ CSSD][39]clssnmSetupAckWait: node(3) is ALIVE 2013-01-19 15:07:02.289: [ CSSD][39]clssnmSetupAckWait: node(4) is ALIVE 2013-01-19 15:07:02.290: [ CSSD][40]clssnmDiscEndp: gipcDestroy 00000000000007a7 2013-01-19 15:07:02.290: [ CSSD][39]clssnmSendSync: syncSeqNo(250911949), indicating EXADATA fence initialization complete ? 2013-01-21 16:13:26.778: [ CSSD][29]clssnmvDiskKillCheck: not evicted, file /crsdata/votedisk3/11gR2_RAC_vote_3 flags 0x00000000, kill block unique 0, my unique 1358 754447 2013-01-21 16:13:26.778: [GIPCXCPT][37] gipcDissociateF [clssnmDiscHelper : clssnm.c : 3460]: EXCEPTION[ ret gipcretFail (1) ] failed to dissociate obj 60000000020e041 0 [00000000000007b0] { gipcEndpoint : localAddr ‘gipcha://w4sd14pa:9680-3a79-3a67-66c’, remoteAddr ‘gipcha://w4sd14pb:nm2_w4sd13p-cluster/83cc-2e02-c5ce-445’, numPend 1 00, numReady 0, numDone 0, numDead 0, numTransfer 0, objFlags 0x0, pidPeer 0, flags 0x38606, usrFlags 0x0 }, flags 0x0 2013-01-21 16:13:26.778: [ CSSD][39]clssnmSendSync: syncSeqNo(254073468), indicating EXADATA fence initialization complete 2013-01-21 16:13:26.778: [ CSSD][39]List of nodes that have ACKed my sync: 2 2013-01-21 16:13:26.778: [ CSSD][40]clssnmDiscEndp: gipcDestroy 00000000000007b0 2013-01-21 16:13:26.779: [GIPCHAUP][7] gipchaUpperDisconnect: initiated discconnect umsg 600000000292e630 { msg 6000000001563028, ret gipcretRequestPending (15), flags 0x2 }, msg 6000000001563028 { type gipchaMsgTypeDisconnect (5), srcCid 00000000-000007c7, dstCid 00000000-00e8c81f }, endp 6000000001bded80 [00000000000007c7] { gipchaE ndpoint : port ‘9680-3a79-3a67-66cf’, peer ‘w4sd14pb:nm2_w4sd13p-cluster/83cc-2e02-c5ce-4458’, srcCid 00000000-000007c7, dstCid 00000000-00e8c81f, numSend 596, maxSend 100, groupListType 2, hagroup 6000000000111870, usrFlags 0x4000, flags 0x21c } 2013-01-21 16:13:26.779: [GIPCXCPT][7] gipcObjectCheckF [gipcPostF : gipc.c : 2008]: object 60000000020e0410 is dying, ret gipcretInvalidObject (3) 2013-01-21 16:13:26.779: [GIPCXCPT][7] gipcPostF [gipcmodGipcCallback : gipcmodGipc.c : 1831]: EXCEPTION[ ret gipcretInvalidObject (3) ] failed to post obj 00000000000 007b0, flags 0x40004000 2013-01-21 16:13:26.779: [GIPCGMOD][7] gipcmodGipcCallback: EXCEPTION[ ret gipcretInvalidObject (3) ] failed during request completion for req 0000000000000000, endp 6 000000001b72c90 2013-01-21 16:13:26.779: [ CSSD][39]clssnmWaitForAcks: node(4) is expiring, msg type(11) 2013-01-21 16:13:27.038: [ CSSD][37]clssnmPollingThread: Removal started for node w4sd13pa (1), flags 0x22040e, state 3, wt4c 0 2013-01-21 16:13:27.038: [ CSSD][37]clssnmMarkNodeForRemoval: node 1, w4sd13pa marked for removal 2013-01-21 16:13:27.038: [ CSSD][37]clssnmDiscHelper: w4sd13pa, node(1) connection failed, endp (000000000000077d), probe(0000000000000000), ninf->endp 0000000000000 77d 2013-01-21 16:13:27.038: [ CSSD][37]clssnmDiscHelper: node 1 clean up, endp (000000000000077d), init state 5, cur state 5 2013-01-21 16:13:27.038: [GIPCXCPT][37] gipcInternalDissociate: obj 60000000020e0050 [000000000000077d] { gipcEndpoint : localAddr ‘gipcha://w4sd14pa:4c56-d55b-6f79-8d7 ‘, remoteAddr ‘gipcha://w4sd13pa:nm2_w4sd13p-cluster/618a-3491-86c1-045’, numPend 100, numReady 0, numDone 0, numDead 0, numTransfer 0, objFlags 0x0, pidPeer 0, flags 0 x38606, usrFlags 0x0 } not associated with any container, ret gipcretFail (1) 2013-01-21 16:13:27.038: [GIPCXCPT][37] gipcDissociateF [clssnmDiscHelper : clssnm.c : 3460]: EXCEPTION[ ret gipcretFail (1) ] failed to dissociate obj 60000000020e005 0 [000000000000077d] { gipcEndpoint : localAddr ‘gipcha://w4sd14pa:4c56-d55b-6f79-8d7’, remoteAddr ‘gipcha://w4sd13pa:nm2_w4sd13p-cluster/618a-3491-86c1-045’, numPend 1 00, numReady 0, numDone 0, numDead 0, numTransfer 0, objFlags 0x0, pidPeer 0, flags 0x38606, usrFlags 0x0 }, flags 0x0 2013-01-21 16:13:27.038: [ CSSD][39]clssnmSendSync: syncSeqNo(254073468), indicating EXADATA fence initialization complete 2013-01-21 16:13:27.038: [ CSSD][39]List of nodes that have ACKed my sync: 2 2013-01-21 16:13:27.038: [ CSSD][39]clssnmWaitForAcks: node(1) is expiring, msg type(11) 2013-01-21 16:13:27.038: [ CSSD][40]clssnmDiscEndp: gipcDestroy 000000000000077d 2013-01-21 16:13:27.038: [ CSSD][39]clssnmSendSync: syncSeqNo(254073468), indicating EXADATA fence initialization complete 2013-01-21 16:13:27.038: [ CSSD][39]List of nodes that have ACKed my sync: 2 2013-01-21 16:13:27.039: [ CSSD][39]clssnmWaitForAcks: done, syncseq(254073468), msg type(11) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmSetMinMaxVersion:node2 product/protocol (11.2/1.4) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmSetMinMaxVersion: properties common to all nodes: 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17 2013-01-21 16:13:27.039: [ CSSD][39]clssnmSetMinMaxVersion: min product/protocol (11.2/1.4) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmSetMinMaxVersion: max product/protocol (11.2/1.4) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmNeedConfReq: No configuration to change 2013-01-21 16:13:27.039: [ CSSD][39]clssnmDoSyncUpdate: Terminating node 1, w4sd13pa, misstime(600007) state(5) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmDoSyncUpdate: Terminating node 3, w4sd13pb, misstime(600323) state(5) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmDoSyncUpdate: Terminating node 4, w4sd14pb, misstime(600278) state(5) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmDoSyncUpdate: Wait for 0 vote ack(s) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmCheckDskInfo: Checking disk info… 2013-01-21 16:13:27.039: [ CSSD][39]clssnmCheckSplit: Node 1, w4sd13pa, is alive, DHB (1358756006, 2252975570) more than disk timeout of 597000 after the last NHB (1 358755407, 2252376120) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmCheckSplit: Node 3, w4sd13pb, is alive, DHB (1358756006, 2252790590) more than disk timeout of 597000 after the last NHB (1 358755406, 2252190580) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmCheckSplit: Node 4, w4sd14pb, is alive, DHB (1358756006, 2252776610) more than disk timeout of 597000 after the last NHB (1 358755406, 2252176770) 2013-01-21 16:13:27.039: [ CSSD][39]clssnmCheckDskInfo: My cohort: 2 2013-01-21 16:13:27.039: [ CSSD][39]clssnmCheckDskInfo: Surviving cohort: 1,3,4 2013-01-21 16:13:27.039: [ CSSD][39](:CSSNM00008:)clssnmCheckDskInfo: Aborting local node to avoid splitbrain. Cohort of 1 nodes with leader 2, w4sd14pa, is smaller than cohort of 3 nodes led by node 1, w4sd13pa, based on map type 2 2013-01-21 16:13:27.039: [ CSSD][39]################################### 2013-01-21 16:13:27.039: [ CSSD][39]clssscExit: CSSD aborting from thread clssnmRcfgMgrThread |
此时要求将内网网络恢复。
网络一旦恢复,ohasd 进程会侦测到并且立即进入恢复阶段。
最终恢复结果如下:
| /home/grid-> crsctl stat res -t
——————————————————————————– NAME TARGET STATE SERVER STATE_DETAILS ——————————————————————————– Local Resources ——————————————————————————– ora.LISTENER.lsnr ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pa ONLINE ONLINE w4sd14pb ora.asm ONLINE OFFLINE w4sd13pa Instance Shutdown ONLINE OFFLINE w4sd13pb Instance Shutdown ONLINE OFFLINE w4sd14pa Instance Shutdown OFFLINE OFFLINE w4sd14pb Instance Shutdown ora.gsd OFFLINE OFFLINE w4sd13pa OFFLINE OFFLINE w4sd13pb OFFLINE OFFLINE w4sd14pa OFFLINE OFFLINE w4sd14pb ora.net1.network ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pa ONLINE ONLINE w4sd14pb ora.ons ONLINE ONLINE w4sd13pa ONLINE ONLINE w4sd13pb ONLINE ONLINE w4sd14pa ONLINE ONLINE w4sd14pb ——————————————————————————– Cluster Resources ——————————————————————————– ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE w4sd13pa ora.cvu 1 ONLINE ONLINE w4sd13pa ora.integ.db 1 ONLINE ONLINE w4sd13pa Open 2 ONLINE ONLINE w4sd14pa Open 3 ONLINE ONLINE w4sd13pb Open 4 ONLINE ONLINE w4sd14pb Open ora.integ.srv14.svc 1 ONLINE ONLINE w4sd13pa ora.integ.srv24.svc 1 ONLINE ONLINE w4sd14pb ora.integ.srv34.svc 1 ONLINE ONLINE w4sd13pb ora.oc4j 1 OFFLINE OFFLINE ora.scan1.vip 1 ONLINE ONLINE w4sd13pa ora.w4sd13pa.vip 1 ONLINE ONLINE w4sd13pa ora.w4sd13pb.vip 1 ONLINE ONLINE w4sd13pb ora.w4sd14pa.vip 1 ONLINE ONLINE w4sd14pa ora.w4sd14pb.vip 1 ONLINE ONLINE w4sd14pb /home/grid-> |
- 测试效果总结
由于客户已经做了网卡冗余策略,1根网线故障不会对集群和数据库可用性造成影响。
内网网络中断的情况下,CRS将会侦测到集群分裂,由于集群发生脑裂故障,数据库无法使用,并且于300秒后故障集群被踢出,此时无故障节点恢复使用。300秒后,故障节点(2节点)被踢出集群,集群进入cleanup 和graceful shutdown 阶段。
只要在故障时间内将网线恢复,故障排除,集群将会自动侦测到并且重新加入集群,恢复所有的资源和数据库实例。
提请用户注意:网络故障恢复后查看是否数据库实例已经正常启动,如果没有恢复需要手动恢复数据库实例。
此时不仅需要用srvctl status database -d shzw 来确定数据库状态,而且需要在每个节点通过 sqlplus ps -fe |grep pmon 和查看alert log 来确定数据库的状态。
18.5 某项目的11g RAC实施内容
现状及需求
为充分提高数据库系统的高可用性、高性能、可扩展性,某公司准备逐步采纳并推广Oracle RAC集群技术。
一方面,该公司计划将实施由美国总部统一部署的第一套基于Oracle RAC的应用系统。另一方面,该公司准备在部署这套系统时,逐步掌握Oracle RAC基本原理和日常运维操作,同时能通过在测试环境专门部署一套RAC系统,并结合一定的应用系统,开展全面的RAC架构设计、高可用性测试、上线方案演练、运维管理、变更管理等工作,为该公司将来全面的RAC改造工作奠定基础。
Oracle服务建议
针对上述现状,我们提出如下的Oracle服务建议:
- 首先,我们将在第一套RAC实施过程中,对该公司的现有 RAC实施方案提供检查和咨询,以及上线期间的现场支持服务。
- 我们将依据Oracle 11g RAC实施解决方案,为该公司的RAC项目提供专项服务。
以下就是RAC专项服务的实施计划及实施内容:
| 阶段 | 主要任务 | 详细内容 |
| 系统设计 | 项目准备、详细计划的制定 | 项目准备、详细计划的制定 |
| RAC技术知识转移 | 开展RAC技术培训工作,包括 Clusterware、ASM、RAC的原理、日常操作、监控管理、 | |
| RAC架构总体方案设计 | 开展RAC的Clusterware、ASM、RAC的总体架构设计 | |
| RAC数据库物理设计和应用部署 | 针对RAC环境开展数据库物理设计和应用部署设计。例如,参数设置、分区方案改造、Service方案设计 | |
| RAC日常运维管理方案设计 | 提供Clusterware、ASM、RAC日常运维方案和操作手册。例如OCR的备份恢复,增加、删除和修复OCR等。 | |
| RAC变更管理方案设计 | 开展Clusterware、ASM、RAC等变更管理方案,例如如何进行公网、私网的变更,如何进行补丁实施,如何进行ASM磁盘的增加、删除等。 | |
| RAC高可用性方案设计 | 针对具体应用开展高可用性方案设计,例如负载均衡、TAF、Failover、Service等设计,同时开展各种软、硬件的故障模拟案例设计 | |
| RAC扩展性方案设计 | 开展RAC环境增加节点、删除节点的方案设计 | |
| RAC备份和恢复方案设计 | 开展RAC环境下的备份、恢复方案设计,包括备份策略、FIB技术运用,恢复案例设计等 | |
| RAC迁移方案设计 | 针对未来不同系统的RAC上线需求,开展原地单机改造成RAC、Data Guard等迁移方案的设计 | |
| 环境建立 | 硬件环境准备的技术支持和环境检查 | 提供硬件系统环境需求,例如操作系统补丁、包的需求,网络配置需求等,并进行环境检查和确认 |
| RAC数据库系统软件的安装、配置和调试 | 安装11g R2软件及相关补丁 | |
| 创建RAC数据库,加载数据 | 针对具体应用系统,创建RAC数据库,并加载相关数据 | |
| 系统备份环境搭建的技术支持 | 为物理备份环境的搭建提供技术支持,同时开展Catalog数据库创建、与磁盘或磁带库的连接等实施工作 | |
| 系统测试 | 应用功能测试的技术支持 | 为应用功能兼容性测试提供技术支持 |
| RAC日常运维管理测试 | 开展Clusterware、ASM、RAC等日常运维管理的测试工作。例如,OCR的备份恢复,增加、删除和修复OCR等测试工作 | |
| RAC变更管理测试 | 开展Clusterware、ASM、RAC等变更管理的测试工作,例如如何进行公网、私网的变更,如何进行补丁实施,如何进行ASM磁盘的增加、删除等。 | |
| RAC高可用性测试 | 开展各种软、硬件故障的模拟测试工作 | |
| RAC扩展性测试 | 开展RAC环境增加节点、删除节点的测试工作 | |
| RAC备份和恢复测试 | 开展RAC环境下的备份、恢复测试工作,包括备份策略、FIB技术运用,恢复案例测试等 | |
| RAC迁移测试 | 针对未来不同系统的RAC上线需求,开展原地单机改造成RAC、Data Guard等迁移方案的测试工作 |
可见,上述RAC专项服务涵盖RAC架构总体方案、RAC数据库物理设计和应用部署、RAC日常运维管理、RAC日常运维管理、RAC变更管理、RAC高可用性等诸多方面的方案设计和测试工作。以下我们挑选几个主要服务项目进行详细介绍。
OCR设备管理
OCR(Oracle Cluster Registry)设备是Oracle Clusterware及RAC环境的重要设备,如果OCR设备出现故障,将导致Clusterware出现宕机等严重故障。在RAC项目实施中,我们将在如下方面展开OCR的实施工作。
- OCR设备是如何自动备份的?
正因为OCR设备的如此重要,因此Oracle自动进行OCR设备的备份工作。作为DBA,我们应了解OCR设备的自动备份策略和备份位置等。
Oracle是采取如下三种自动备份策略:
- 每间隔4小时进行一次OCR设备备份,并保留最新的三个备份。
- Oracle每天对OCR设备备份一次,并保留最新的两个备份。
- Oracle每周对OCR设备备份一次,并保留最新的两个备份。
这样,Oracle最多可能有7个备份:1个4小时前的备份,1个8小时前的备份,1个12小时前的备份,1个24小时前的备份,1个48小时前的备份,1个7天前的备份,1个14天前的备份。
OCR自动备份数据位于<Grid Home>/cdata/<cluster name>目录。通过如下命令,可显示OCR自动备份结果:
$ ocrconfig -showbackup auto
host02 2009/07/28 12:20:42 /u01/app/…/cdata/cluster01/backup00.ocr
host02 2009/07/28 08:20:41 /u01/app/…/cdata/cluster01/backup01.ocr
host02 2009/07/28 04:20:40 /u01/app/…/cdata/cluster01/backup02.ocr
host02 2009/07/27 16:20:37 /u01/app/…/cdata/cluster01/day.ocr
host02 2009/07/28 00:20:39 /u01/app/…/cdata/cluster01/week.ocr
- 如何修改OCR自动备份位置?
缺省情况下,Oracle在RAC的主节点将OCR设备备份到本地的<Grid Home>/cdata/<cluster name>目录。为安全起见,Oracle建议将OCR设备备份目录设定到所有节点都能访问的共享目录,这样,一旦主节点出现故障,其它节点仍然可以进行OCR设备的备份工作。以下就是修改OCR设备备份目录的命令:
# ocrconfig –backuploc <path to shared CFS or NFS>
即OCR备份目录应是共享的CFS或NFS目录,但不能设置为ACFS文件系统。
- 如何进行OCR设备的手工备份?
相比Voting Disk设备, OCR设备保存的Clusterware配置信息更加动态。因此,当OCR设备内容发生比较大的变化时,除了Oracle的上述自动备份策略之外,建议及时进行OCR设备的手工备份。
如下命令进行OCR设备的手工备份:
# ocrconfig -manualbackup
即Oracle将自动在OCR备份目录产生一个格式为backup_<date>_<time>.ocr的OCR备份文件。
通过如下命令将显示手工备份的OCR备份文件清单:
$ ocrconfig –showbackup manual
host02 2009/07/28 16:59:17 /u01/app/…/cdata/cluster01/backup_20090728_165917.ocr
通过如下命令,还可对OCR设备进行手工的逻辑备份:
# ocrconfig -export /home/oracle/ocr.backup
上述OCR设备手工备份操作,并不影响Oracle的自动备份策略。
- 如何增加、替换、修复、删除OCR设备
在安装或升级Oracle Grid Infrastructure之后,可通过如下命令增加OCR设备:
# ocrconfig -add +DATA2
# ocrconfig -add /dev/sde1
第一条命令在+DATA2磁盘组中增加一个OCR设备,第二条命令将/dev/sde1 设备增加为OCR设备。Grid Infrastructure最多可支持5个OCR设备。
通过如下命令替换OCR设备:
# ocrconfig -replace /dev/sde1 -replacement +DATA2
上述命令将现有OCR设备/dev/sde1,替换为磁盘组+DATA2中的OCR设备。也就是删除OCR设备/dev/sde1,并在+DATA2中增加一个OCR设备。
在停止运行Clusterware的节点,可对OCR进行修复操作,包括增加、删除、替换OCR设备等操作。例如:
[root@host03]# ocrconfig -repair -add +DATA1
通过如下命令,可删除OCR设备:
# ocrconfig -delete +DATA2
# ocrconfig -delete /dev/sde1
第一条命令在+DATA2磁盘组中删除一个OCR设备,第二条命令将OCR 设备 /dev/sde1 设备删除。但是,Clusterware必须有至少一个OCR设备存在,否则上述删除操作将报错。
- 如何将OCR设备迁移到ASM?
Oracle从11g R2开始可以通过ASM进行OCR 设备的存储和管理,这样可进一步提高整个Clusterware设备的可管理性,例如通过EM可对数据库和Clusterware的存储设备进行集中的统一管理。如果将10g数据库升级到11g,则可以将OCR设备迁移到ASM之中。以下就是详细步骤:
- 通过如下命令,确认Oracle Clusterware已经升级到11g R2版本:
$ crsctl query crs activeversion
Oracle Clusterware active version on cluster is [11.2.0.1.0]
- 通过ASMCA工具配置,并在集群的所有节点启动ASM实例。同时创建一个至少为Normal冗余、大小至少为1GB的磁盘组。
- 通过如下命令,在上述磁盘组中增加一个OCR设备:
# ocrconfig -add +DATA2
上述命令执行一次,增加一个OCR设备。
- 通过如下命令,可删除以前存储在裸设备上的OCR设备:
# ocrconfig -delete /dev/raw/raw1
# ocrconfig -delete /dev/raw/raw2
- 如何通过物理备份进行OCR设备的恢复?
当OCR设备出现故障时,可通过如下步骤进行OCR设备的物理恢复:
- 确定OCR物理备份数据
通过如下命令可确定OCR物理备份数据:
$ ocrconfig –showbackup
包括自动(auto)和手工(manual)的OCR物理备份数据。
- 在所有节点停止Oracle Clusterware
通过如下命令可在所有节点停止Oracle Clusterware:
# crsctl stop cluster -all
- 在所有节点停止Oracle High Availability Services
通过如下命令可在所有节点停止Oracle High Availability Services:
# crsctl stop crs
- OCR设备的物理恢复
通过如下命令可进行OCR设备的物理恢复:
# ocrconfig –restore /u01/app/…/cdata/cluster01/day.ocr
- 在所有节点重启Oracle High Availability Services
通过如下命令,在所有节点重启Oracle High Availability Services:
# crsctl start crs
- 检查OCR设备的完整性
通过如下命令,可检查OCR设备的完整性:
$ cluvfy comp ocr -n all
- 如何通过逻辑备份进行OCR设备的恢复?
当OCR设备出现故障时,可通过如下步骤进行OCR设备的逻辑恢复:
- 确定OCR逻辑备份数据
通过逻辑备份命令“ocrconfig -export file_name”命令,可确定OCR逻辑备份数据。
- 在所有节点停止Oracle High Availability Services
通过如下命令可在所有节点停止Oracle High Availability Services:
# crsctl stop crs
- OCR设备的逻辑恢复
通过如下命令可进行OCR设备的逻辑恢复:
# ocrconfig –import /shared/export/ocrback.dmp
- 在所有节点重启Oracle High Availability Services
通过如下命令,在所有节点重启Oracle High Availability Services:
# crsctl start crs
- 检查OCR设备的完整性
通过如下命令,可检查OCR设备的完整性:
$ cluvfy comp ocr -n all
- 什么叫OLR?
在11g R2版本中,集群中的每个节点都有一个本地的注册信息文件,称之为Oracle Local Registry(OLR),Oracle在安装OCR设备时进行OLR的安装和配置。当Oracle通过ASM进行OCR和Voting Disk的管理时,OLR主要在Clusterware启动过程中进行一些协调操作,例如确定Voting Disk设备的位置等。
缺省情况下,OLR存储于grid_home/cdata/hostname.olr。通过如下命令,可检查OLR设备的状态:
$ ocrcheck -local
Status of Oracle Local Registry is as follows :
Version : 3
Total space (kbytes) : 262120
Used space (kbytes) : 2204
Available space(kbytes): 259916
ID : 1535380044
Device/File Name : /u01/app/11.2.0/grid/cdata/host01.olr
Device/File integrity check succeeded
Local registry integrity check succeeded
Logical corruption check succeeded
公网的变更
对数据库服务器IP地址进行调整,是客户一项比较正常的变更需求。RAC环境下的IP地址涉及公网、私网,而且都是被Clusterware管理的资源,因此与普通单机数据库不一样的是,需要通过专门的规范化流程来分别进行公网、私网的调整,否则,会导致系统出现严重问题。
- 如何确定当前网络设置?
- 确定当前集群可用的网络信息:
$ oifcfg iflist –p -n
- 确定当前集群的公网和私网配置:
$ oifcfg getif
eth0 192.0.2.0 global public
eth1 192.168.1.0 global cluster_interconnect
- 确定当前集群的VIP主机名、VIP地址、VIP子网掩码等信息:
$ srvctl config nodeapps -a
VIP exists.:host01
VIP exists.: /192.0.2.247/192.0.2.247/255.255.255.0/eth0
…
- 如何修改公网VIP地址?
- 在需要修改的公网VIP地址的所在节点,停止相关服务,例如:
$ srvctl stop service -d RDBA -s sales,oltp -n host01
- 通过如下命令,确认VIP地址的当前IP地址:
$ srvctl config vip -n host01
VIP exists.:host01
VIP exists.: /host01-vip/192.168.2.20/255.255.255.0/eth0
- 通过如下命令,停止VIP地址:
$ srvctl stop vip -n host01
- 通过ifconfig –a命令,确认VIP地址已经停止。
- 对所有节点的/etc/hosts文件或DNS服务器进行必要的修改,使得新IP地址与主机名关联。
- 通过如下命令,创建新的VIP地址:
# srvctl modify nodeapps -n host01 -A \ 192.168.2.125/255.255.255.0/eth0
- 重起VIP地址:
# srvctl start vip -n host01
- 在相关节点进行上述各步骤的操作,完成相关节点的VIP地址修改。由于srvctl是集群级工具,因此,可在一个节点完成其它节点的维护工作,而不需要登录到相关节点。
- 通过如下命令,对修改 VIP地址之后的集群环境进行连通性确认:
$ cluvfy comp nodecon -n all -verbose
私网的变更
欲修改私网地址,必须在所有节点同时进行,这是因为Oracle Clusterware目前不支持采用不同的私网Interface,例如不允许节点1为 eth1,而节点2为 eth2。
以下就是私网地址修改过程:
- 确保Oracle Clusterware在所有节点都启动并正常运行。
- 通过操作系统命令(例如ifconfig),确保新的私网 Interface已经正确配置,并正常启动。
- 在集群中的某个节点,通过如下命令,增加新的私网 Interface:
$ oifcfg setif -global eth2/192.0.2.0:cluster_interconnect
- 在集群中的某个节点,通过如下命令,确认新的私网 Interface已经存在,并停止整个集群的 Clusterware:
# oifcfg getif
# crsctl stop crs
- 通过如下命令,将新的私网 Interface分配给所有节点的私网网卡:
# ifconfig eth2 192.0.2.15 netmask 255.255.255.0 \
broadcast 192.0.2.255
- 通过oifcfg getif命令,确认修改成功。
- 通过如下命令删除老的私网Interface,并重新启动Clusterware:
$ oifcfg delif -global eth1/192.168.1.0
# crsctl start crs
18.6 11件加固RAC环境的事情
在本书坏块处理一章,本人曾说Oracle接客户求救电话中,最多的是如下两类:一类是数据库宕机或挂起,特别是RAC 数据库出现宕机,另外一类是数据库出现坏块。
RAC集群环境涉及主机、操作系统、网络、存储等各层面技术,由于这些环境因素和Oracle软件自身问题而导致的宕机、节点重启等故障,已经司空见惯。RAC本来是为客户数据库系统提供高可用性保障的,但“保障高可用性的东西,自己反而这么不稳定?”成了很多客户诟病和抱怨Oracle公司的典型话语。
如何提高RAC的健壮性?Oracle公司提供的《Top 11 Things to do NOW to Stabilize your RAC Cluster Environment [ID 1344678.1]》,叙述了如下11条RAC最佳实践经验,非常值得我们在 RAC实施中加以借鉴。
1. 安装最新的PSU补丁
在本书的“Oracle版本、Bug和补丁”一章,我们已经介绍了Oracle版本和多种补丁的概念,包括PSU补丁。PSU补丁是Oracle自10.2.0.4版本起,每个季度定期发布的补丁,并包括CPU补丁。PSU补丁包含了当前时间内全球最常见、最重要、对系统健壮性有重要影响的一些小补丁。因此,在RAC实施中,应尽量安装最新的PSU补丁。
需要注意的是,Windows平台没有PSU补丁概念,同期PSU补丁的内容包含在相应的Windows Bundle Patch中。
如下文章更详细介绍了PSU补丁:
《Document 854428.1 Intro to Patch Set Updates (PSU)》
《Document 1082394.1 11.2.0.X Grid Infrastructure PSU Known Issues》《Document 756671.1 Oracle Recommended Patches — Oracle Database》《Document 161549.1 Oracle Database, Networking and Grid Agent Patches for Microsoft Platforms》
2. 设置正确的UDP协议缓冲区参数
RAC集群环境的私网通信(Interconnect)是RAC的命脉,在UNIX和Linux平台,合理设置UDP协议的接受和发送缓冲区参数,将对私网通信效率至关重要。反之,不仅会影响RAC的私网通信效率,更可能导致RAC出现宕机等严重故障。
如下文章更详细介绍了如何合理设置UDP协议缓冲区参数:
《Document 181489.1 Tuning Inter-Instance Performance in RAC and OPS》
《Document 563566.1 gc lost blocks diagnostics》
需要注意的是,由于Windows平台采用TCP协议进行私网通信,因此无需设置UDP缓冲区参数。
3. 在10.2和11.1环境,将DIAGWAIT值设置为13
在10.2和11.1环境,OPROCD后台进程的缺省margin值设置为500毫秒(即5秒)。这样,当系统负载处于繁忙状态时,可能使得Oracle反应过于敏感,从而导致节点重启。将DIAGWAIT值设置为13,将OPROCD后台进程的缺省margin值设置为1000毫秒(即10秒),这样能避免不必要的节点重启,同时也使Oracle在发生节点重启故障时,有更多时间将相关信息写入trace文件,以便进行深入的诊断分析。
通过如下命令,可了解当前的DIAGWAIT配置:
# $CLUSTERWARE_HOME\bin\crsctl get css diagwait
该建议不适合于Windows环境,以及11.2以上版本。
如下文章更详细介绍了DIAGWAIT的含义及设置方法:
《Document 559365.1 Using Diagwait as a diagnostic to get more information for diagnosing Oracle Clusterware Node evictions》《Document 567730.1 Changes in Oracle Clusterware on Linux with the 10.2.0.4 Patchset》
4. 在LINUX环境下实施 HugePages
在Linux 64位平台,实施HugePages将极大地提高Linux核运行性能,特别是针对内存配置较大的系统。通常而言,超过12GB内存的系统,就应该考虑实施HugePages,内存越大,实施HugePages的效果越明显。其原理在于:当Linux在进行内存管理时,需要按页进行内存的映射和维护操作。若启动HugePages,将有效降低内存页的数量,从而提升系统性能。大量实践经验表明:当未实施HugePages时,由于Linux核内存管理负载较重,可能导致RAC节点被踢出,甚至节点重启。
但是,在Linux 64位平台,11g的自动内存管理技术(AMM)与HugePages技术不兼容。因此,欲采用HugePages技术,应关闭AMM技术。Document 749851.1描述了在Linux 平台AMM和HugePages技术的关联关系。
如下文章更详细介绍了HugePages含义及设置方法:
《Document 361323.1 HugePages on Linux: What It Is… and What It Is Not…》
《Document 401749.1 Shell Script to Calculate Values Recommended Linux HugePages / HugeTLB Configuration》
5. 实施OS Watcher及Cluster Health Monitor
尽管与RAC稳定性没有直接关系,但OS Watcher和Cluster Health Monitor工具的部署,将对节点或实例宕机等故障的诊断,特别是在操作系统层面的原因分析,起到非常关键的作用。通过这些工具的信息采集,不仅有利于故障的诊断分析,而且也可有效防止故障的再次发生。与很多第三方工具信息采集周期通常为5分钟不同的是,OS Watcher的采集周期缺省为30秒,因此能采集到更多的操作系统信息,从而有利于故障的定位。虽然Oracle没有在所有平台都提供Cluster Health Monitor工具,但该工具是对OS Watcher的有力补充,该工具可以更精细的粒度进行信息采集。因此,在RAC环境的所有节点部署这些工具,将有效提高故障诊断和处理效率。
如下文章更详细介绍了OS Watcher及Cluster Health Monitor工具:
《Document 301137.1 OS Watcher User Guide》
《Document 1328466.1 Cluster Health Monitor (CHM) FAQ》
6. 遵循AIX操作系统的最佳实践经验
为提高RAC在AIX平台的运行稳定性和效率,Oracle和 IBM公司一直在精诚合作。双方共同推出的《The Oracle Real Application Clusters on IBM AIX Best practices in memory tuning and configuring for system stability》白皮书,就是两个公司工程师们共同的结晶。根据此白皮书的经验总结进行实施,将解决大部分在AIX平台实施RAC的稳定性问题。AIX 6.1版甚至已经将这些经验值作为缺省值进行设置。
如下文章详细介绍了更多内容:
白皮书位于: http://www.oracle.com/technetwork/database/clusterware/overview/rac-aix-system-stability-131022.pdf
《Document 811293.1 RAC Assurance Support Team: RAC Starter Kit and Best Practices (AIX)》
7. 在AIX环境下正确实施APARS,避免过量的Paging/Swapping操作
经验表明,在AIX环境下如果没有正确实施APARS,例如在AIX 6.1版本,没有安装APAR IZ71987,可能导致大量的Paging/Swapping操作。这样在Oracle单机环境可能导致系统Hang,并需要人工干预加以解决。而在RAC环境,则可能导致一个节点被踢出。
如下文章详细介绍了更多内容:
《Document 1088076.1 Paging Space Growth May Occur Unexpectedly on AIX Systems With 64K (medium) Pages Enabled》
8. 实施NUMA补丁
所谓NUMA(Non Uniform Memory Access Achitecture),即非一致访问分布共享存储技术,它是由若干通过高速专用网络连接起来的独立节点构成的系统,各个节点可以是单个的CPU或是SMP系统。Oracle RAC支持NUMA技术。但在NUMA环境实施RAC,同样会有导致性能、甚至宕机的Bug存在。文档 Document 759565.1列出了在10.2.0.4和11.1.0.7版本下的与NUMA相关的问题。若版本为10.2.0.4和11.1.0.7,Oracle建议安装补丁8199533。
9. 在Windows环境下,扩大Nonineractive Desktop Heap值
经验表明,在Windows平台实施RAC,Nonineractive Desktop Heap的缺省值不够,可能导致应用连接问题,甚至导致系统Hang和宕机问题。因此,应主动将Nonineractive Desktop Heap值设置为1M,将有效避免上述问题的发生。
文档《Connections Fail with ORA-12640 or ORA-21561 (Doc ID 744125.1)》详细介绍了上述相关问题及解决办法。
10. 运行RACCheck工具
RACCheck工具全称叫做:RAC Configuration Audit tool,主要用于检查和审计RAC、Clusterware、ASM及GI环境的配置信息。检查和审计的领域包括:操作系统核心参数、操作系统Package、与RAC相关的操作系统其它配置信息、CRS/Grid Infrastructure、RDBMS、ASM、数据库参数、与RAC相关的数据库其它配置信息、11.2.0.3升级就绪评估。
通过RACCheck工具,能帮助客户确认RAC实施是否遵循了Oracle公司建议的一系列RAC最佳实践经验,有效发现存在的问题,并最终提高RAC运行的稳定性。
本书第十章的“10.3 数据库常见诊断工具”一节,详细介绍了RACCheck工具的使用。
11. 实施NTP Slewing Option
假设没有实施NTP回转选项(NTP Slewing Option),会导致系统时钟向前或向后调整。假设向后调整的时间量超出一定范围,会导致节点被踢出。因此,为防止此情况的发生,应设置NTP服务,确保整个集群节点时钟的同步。
假设没有配置NTP服务,11g中将自动配置Cluster Time Synchronization Service(CTSS),并在集群所有节点启动octssd.bin后台进程。
18.7本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 11g R2联机文档 | 《Oracle® Real Application Clusters Administration and Deployment Guide》 | 这是Oracle联机文档中有关RAC管理和实施的专门文档。 |
| 2. | Oracle 11g R2联机文档 | 《Oracle® Clusterware Administration and Deployment Guide》 | 这是Oracle联机文档中有关Clusterware管理和实施的专门文档。 |
| 3. | Oracle 11g R2联机文档 | 《Oracle® Automatic Storage Management Administrator’s Guide》 | 这是Oracle联机文档中有关ASM管理和实施的专门文档。 |
| 4. | My Oracle Support | 《Master Note for Real Application Clusters (RAC) Oracle Clusterware and Oracle Grid Infrastructure (Doc ID 1096952.1)》 | 欲全面了解RAC、GI的技术资料、最佳实践经验吗?这篇文档就是入口处。 |
| 5. | My Oracle Support | 《RAC and Oracle Clusterware Best Practices and Starter Kit (Platform Independent) (Doc ID 810394.1)》 | 该文档包括了RAC和Clusterware一些重要的、适合于所有平台的最佳实践经验,其中还包括了与平台相关的文档链接。 |
| 6. | My Oracle Support | 《RAC Frequently Asked Questions [ID 220970.1]》 | 为什么私网一定不能直连?Cache Fusion是什么?Cache Fusion对应用有什么影响?从单实例转换到RAC很难吗?……这些与RAC相关的常见问题,都能在这篇文档中找到答案。 |
| 7. | My Oracle Support | 《Top 11 Things to do NOW to Stabilize your RAC Cluster Environment [ID 1344678.1]》 | “11件加固RAC环境的事情”――――题目好诱人哦,也是本章相同标题小节的参考资料。 |

Comment