
SHOUG成员 – ORACLE ACS高级顾问罗敏
本文永久地址:https://www.askmac.cn/?p=16572
本人的第一本书《品悟性能优化》,“洋洋洒洒”近500页,按Oracle性能优化方法论从上往下,即从应用设计开发,到系统层面逐步展开叙述。性能优化的确是IT系统各方人士长期面临的艰难挑战,也是大家百谈不厌的话题。本书虽然没有对性能优化再浓墨重彩,但很多章节内容其实也是围绕性能优化而展开的。
本章我们先对《品悟性能优化》一些重要观点进行回顾,然后再通过若干案例,对这些观点进行总结。同时,由于受篇幅等因素限制,针对《品悟性能优化》书所没有包括的一些优化技术,例如适合于数据仓库的Bitmap索引、Bitmap Join索引等进行介绍。
众所周知,应用性能问题对系统整体性能影响最大,所以本章案例更多地侧重于应用性能问题的解剖。同时,性能问题也涉及IT系统的方方面面,本章最后一个案例就是分析数据库备份恢复中的性能问题。
重温《品悟性能优化》一些重要观点
回顾性能优化方法论
Oracle性能优化方法论主要分为如下两种:
- 自顶向下(Top-Bottom)
该方法论可以如下图表示:

即在项目设计、开发、上线的全程都展开性能优化工作,而且优化工作开始地越早,其效益也越高,同时付出的成本也最小。而优化工作开始地越晚,其效益也越低,并且付出的成本也最大。
之所以叫自顶向下,是因为一方面从软件生命周期角度而言,从头开始就关注性能优化工作。另一方面,最初我们在业务逻辑、架构设计等层面关注性能问题,然后再逐步深入到应用设计、开发和测试层面考虑优化,最后才到数据库系统、操作系统、硬件等层面考虑参数设置、存储配置等优化,即从IT系统架构层面而言,也是自顶向下的。
总之,自顶向下更适合于一个新项目的建设。
- 自底向上(Bottom -Top)
如果针对一个已经投产的系统发生的性能问题,则我们需要采用自底向上方法论了。以下就是自底向上方法论示意图:

即我们先从系统层面开始,了解硬件配置,检查系统的CPU、I/O利用率等,然后再逐步了解到数据库的各种等待事件,从而基本确定性能瓶颈所在,最后再重点分析应用问题。即从IT系统架构层面而言,是自底向上的。
另外,从上线后发现性能问题,到逐步分析出某个SQL语句、某个应用问题,最终可能回溯到数据库设计、数据库架构,甚至业务流程设计的问题,因此这种问题分析和解决方式从IT系统时间轴上分析,也是自底向上,自后往前的。
性能优化中的20/80规则
- 数据库体系结构设计和应用设计对系统性能的影响能占到80%,而硬件配置、参数调整、系统软件Bug等系统方面因素,只占到20%。
- 80%的性能问题是由20%的应用导致的。如少量大表的全表扫描导致的性能瓶颈。并不是应用一有问题,就一定要对现有数据库结构大卸八块,应用推倒重来。
- 80%的性能问题可以由20%的优化技术所解决。如简单的索引策略,执行路径分析等,能解决绝大部分性能问题。
应用开发指导思想
建议应用系统设计和开发人员在开发过程中,在开发指导思想上进行如下方面的加强:
- 不仅关注SQL语句功能,而且要关注性能。即用量化手段,进行SQL语句质量控制
- 开发队伍能有层次性和专业分工。不仅按照业务模块分工,而且有专门的质量控制,尤其是SQL质量控制人员
- 加强软件开发的规范管理
- 注重知识共享和传递,减少低级错误的重复性
- 强调实际测试的重要性。切忌想当然的主观推断,一切以实际应用在尽可能真实数据和环境下的测试数据为准
针对OLTP和OLAP系统,合理运用不同技术
IT系统总体上可以分为OLTP和OLAP系统,数据库系统优化的目标与应用系统的类型是紧密相关的。这两类系统无论在业务特征还是适用的技术方面都迥然不同。例如,针对生产系统,应以系统的响应速度作为首要的优化目标。而对查询统计系统而言,则应该以系统整体吞吐量作为优化目标。
以下是我们总结的两类系统在业务操作特征,以及技术运用方面的主要区别:
| 比较项目 | 联机业务 | 批处理业务 | |
| 业务特征 | 操作特点 | 日常业务操作,尤其是包含大量前台操作 | 后台操作,例如统计报表、大批量数据加载 |
| 响应速度 | 优先级最高,要求反应速度非常高 | 要求速度高、吞吐量大 | |
| 吞吐量 | 小 | 大 | |
| 并发访问量 | 非常高 | 不高 | |
| 单笔事务的资源消耗 | 小 | 大 | |
| SQL语句类型 | 主要是插入和修改操作(DML) | 主要是大量查询操作或批量DML操作 | |
| 技术运用 | 索引类型 | B*索引 | Bitmap、Bitmap Join索引 |
| 索引量 | 适量 | 多 | |
| 按索引访问 | 全表扫描 | ||
| 连接方式 | Nested_loop | Hash Join | |
| BIND变量 | 使用或强制使用 | 不使用 | |
| 并行技术 | 使用不多 | 大量使用 | |
| 分区技术 | 使用,但目标不同 | 使用,但目标不同 | |
| 物化视图使用 | 少量使用 | 大量使用 |
索引设计规范
无论在联机业务系统,还是在批处理业务系统中,简单的索引策略,能解决绝大部分性能问题。因此,索引设计是开发人员应首要关注的设计规范和策略。合理的索引设计将有效降低不必要的全表扫描,大大降低系统资源消耗,提高整个IT系统的生命周期。
下面将由简及繁,介绍索引设计规范和策略:
- B*树单字段索引设计规范和策略
- 分析SQL语句中的约束条件字段
- 如果约束条件字段不固定,建议创建针对单字段的普通B*树索引
- 选择可选性最高的字段建立索引
- 如果是多表连接SQL语句,注意被驱动表(drived table)的连接字段是否需要创建索引
- 通过多种SQL分析工具,分析执行计划并以量化形式评估效果
- B*树复合索引设计规范和建议
- 分析SQL语句中的约束条件字段
- 如果约束条件字段比较固定,则优先考虑创建针对多字段的普通B*树复合索引。
- 在复合索引设计中,需首先考虑复合索引第一个设计原则:复合索引的前缀性(prefixing)。即SQL语句中,只有复合索引的第一个字段作为约束条件,该复合索引才会启用。
- 在复合索引设计中,其次应考虑复合索引的可选性(Selectivity或Cardinality)。即按可选性高低,进行复合索引字段的排序。
- 如果是多表连接SQL语句,注意是否可以在被驱动表(drived table)的连接字段与该表的其它约束条件字段上,创建复合索引。
- 通过多种SQL分析工具,分析执行计划并以量化形式评估效果
- 如何避免索引被抑制问题
导致不必要的全表扫描的一个重要原因是:虽然在相关字段建立了索引,但因如下一些因素导致索引被抑制。
- 在字段前增加了函数
在字段前增加了函数,将导致索引无法使用,应尽量将字段前的函数进行转换。例如:
to_char(c.total_date) between :in_begin_time and :in_end_time
应修改为:
c.total_date between to_date(:in_begin_time,’YYYY.MM.DD’) and to_date(:in_end_time,’YYYY.MM.DD’)
- 字段类型设计问题
如果因字段类型设计不合理,将迫使应用程序使用函数,从而导致索引无法使用。例如日期数据以字符类型进行表达,将被迫导致SQL语句使用substr,trim等函数。错误地使用char字段,也将导致使用trim函数进行空格的截取。
- 将字段嵌入表达式之中
将字段嵌入表达式之中,也将导致索引无法使用,应尽量将字段从表达式中进行剥离。例如:
and (sysdate – to_date(a.efftt, ‘yyyymmddhh24miss’)) * 24 * 60 <= 15
应修改为:
and a.efftt >= to_char((sysdate – 1/96),’yyyymmddhh24miss’);
- 函数索引设计规范
如果可能,应尽量避免创建函数索引,因为函数索引将导致DML操作资源消耗增加。例如上述的的to_char字段,应调整为to_date。如果需要创建函数索引,则Oracle优化器要运行在CBO模式下,即应定期进行统计信息的采集和更新。
- Bitmap索引设计规范
Bitmap位图索引适合于统计分析应用。建议针对可选性(Selectivity或Cardinality)低的字段,创建Bitmap位图索引或Bitmap Join位图索引。Bitmap索引应运行在CBO模式下,即应定期进行统计信息的采集和更新。
交易系统中绑定变量使用规范
交易系统具有单笔查询的资源消耗小、并发量高等特征。在交易系统中,大量重复的SQL语句的Parse操作,不仅极大地消耗了CPU资源,而且长远来看,也是影响交易系统扩展性和系统生命周期的重要因素。
针对交易系统,应尽量通过如下两种策略,实现SQL语句的Bind化处理,减少SQL语句的Parse次数,提高SQL语句共享性。
- 应用级Bind化处理
尽量在SQL语句中使用绑定变量,例如:
- PL/SQL中使用USING短语
- JDBC中通过PrepareStatement、SetXXX()的调用,为SQL语句的?变量赋值
- 系统级Bind化处理
通过将Oracle初始化参数CURSOR_SHARING由缺省的EXACT修改为FORCE,实现系统级Bind化处理。
建议优先考虑应用级Bind化处理规范。
查询统计系统中绑定变量使用规范
查询统计系统具有单笔事务的资源消耗大、并发量不高等特点。这类应用SQL语句的资源消耗主要在Execute和Fetch阶段,而Parse量并不高。因此应该保证这类应用语句执行计划的最优化。
为此,无需通过SQL语句共享性来保证这类应用的性能,而通过保持查询条件的常量化,来保证执行计划的最优化。因此,不需要语句的Bind化处理,也不需要将EXACT修改为FORCE。
交易系统和数据仓库系统的不同表连接技术
在交易系统中,大部分表连接语句虽然访问的表可能很大,但其实只是查询少量数据,因此建议尽量采用Nested_Loop技术,并结合上述索引策略,特别注意被驱动表(drived table)的连接字段是否需要创建单字段索引和复合索引。
在数据仓库系统中,大部分表连接语句是查询大规模数据,建议尽量采用HASH_JOIN技术,并考虑并行处理技术。
4.2 深入剖析一个测试题
某次为某公司提供性能优化培训和服务过程中,该公司开发团队负责人提出:“罗老师,能不能增加一些实际操作的测试题,检验我们开发团队人员的实际技术能力和培训效果?”没问题,我在以往多次培训和技术交流中就经常进行这种测试。于是,这次针对该客户具体需求和时间安排,特意设计了理论与实际结合的10道题目。下面就深入剖析其中一个实际操作题。
题目
“针对如下语句:
select c.channel_desc, s.quantity_sold, s.amount_sold from kj_channels c, kj_sales s, kj_products p where c.channel_id = s.channel_id and p.prod_id = s.prod_id and c.channel_desc = 'Internet' and p.prod_name = 'Laptop carrying case';
请确定最佳索引方案,并进行执行计划和执行效率分析。”
该题目测试目的一方面为了检验大家对索引原理和设计规范的掌握程度,例如如何设计单字段索引和复合索引。另一方面,也是更重要的为了让大家能提升开发设计指导思想,例如不仅关注SQL语句功能,而且要关注性能。即用量化手段,进行SQL语句质量控制;加强软件开发的规范管理等等。
在本书此处介绍该测试题,也是对上述性能优化一些重要观点的验证。
答案
该题目的答案其实很简单,即应设计如下索引:
Create index idx_1 on kj_channels(channel_desc);
Create index idx_2 on kj_products(prod_name);
Create index idx_3 on kj_sales(prod_id,channel_id);
但为什么?能不能从量化角度给出设计依据?以下的测试结果表格是我希望看到大家解答这个题目的过程:
| 序号 | 索引方案 | 运行时间 | 执行计划 | Cost | Consistent Gets | physical reads |
| 1. | 无索引 | 00: 00: 01.04 | 三个表全表扫描 | 1241 | 4868 | 4668 |
| 2. | kj_channels(channel_desc) | 00: 00: 00.98 | kj_channels表按索引访问,kj_products、kj_sales表全表扫描 | 1239 | 4898 | 4681 |
| 3. | kj_channels(channel_desc)
kj_products(prod_name) |
00: 00: 01.15 | kj_channels、kj_products表按索引访问,kj_sales表全表扫描 | 1238 | 4918 | 4693 |
| 4. | kj_channels(channel_desc)
kj_products(prod_name) kj_sales(prod_id) kj_sales(channel_id) |
00: 00: 01.02 | 三个表全部按索引访问 | 172 | 713 | 451 |
| 5. | kj_channels(channel_desc)
kj_products(prod_name) kj_sales(channel_id ,prod_id) |
00: 00: 00.93 | 三个表全部按索引访问 | 94 | 658 | 409 |
| 6. | kj_channels(channel_desc)
kj_products(prod_name) kj_sales(prod_id, channel_id ) |
00: 00: 01.32 | 三个表全部按索引访问 | 94 | 657 | 406 |
- 方案1:三个表均没有设计索引,执行计划当然为全表扫描,各项指标仅作为基准指标。
- 方案2:只设计了kj_channels(channel_desc)索引,执行计划为对kj_channels表按索引访问,但kj_products、kj_sales表依然是全表扫描。各项指标没有明显优化。
- 方案3:在方案2基础上增加了kj_products(prod_name) 索引,执行计划为对kj_channels、kj_products表按索引访问,但kj_sales表依然是全表扫描。各项指标依然没有明显优化。
- 方案4:在方案3基础上增加了kj_sales(prod_id)、kj_sales(channel_id)两个单字段索引,执行计划为三个表全部按索引访问。各项指标相比前三个方案得到明显优化。
- 方案5:在方案3基础上增加了kj_sales(channel_id ,prod_id)一个复合索引,执行计划为三个表全部按索引访问。各项指标相比方案4又得到一定优化,说明复合索引对性能提升的重要性。
- 方案6:在方案3基础上增加了kj_sales(prod_id ,channel_id )一个复合索引,执行计划为三个表全部按索引访问。各项指标相比方案5又得到一定优化。这是因为prod_id不同记录值为72,而channel_id不同记录值为4,说明复合索引的可选性对性能提升的作用。即应将不同记录值最多的字段放在复合索引第一个字段,不同记录值次多的字段放在复合索引第二个字段,以此类推。
可见,上述方案6才是该SQL语句的最佳索引方案,以下就是该语句在方案6下的执行计划:
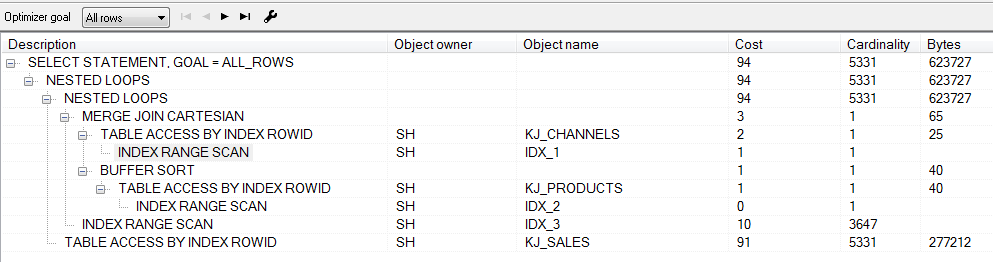
需要说明的是:由于该测试题采用的数据是Oracle 11g的 SH用户下的样本数据,数据量有限,有些测试结果仅仅作为参考,例如语句运行时间等。如果在更真实、更大数据量环境下进行测试,上述指标将更具有说服力。
又一次救火经历
先了解火情
某天正在东北某城市出差,突然接到了某客户的紧急救援电话:“罗工,能帮助分析一下吗?我们一个社会保险系统的性能很差,机器都满负荷跑了,都快撑不住了!”就象消防队员一样,先了解火情吧。由于还是9i系统,于是向客户提出请求:“能将该系统的statspack报告发过来一份吗?”因此,很快看到了该系统的主要情况:
- 总体负载指标
Load Profile ~~~~~~~~~~~~ Per Second Per Transaction --------------- --------------- Redo size: 3,550.96 7,048.70 Logical reads: 209,462.91 415,786.12 Block changes: 14.53 28.84 Physical reads: 47,085.54 93,465.31 Physical writes: 0.84 1.67 User calls: 69.18 137.33 Parses: 9.60 19.06 Hard parses: 0.08 0.16 Sorts: 2.75 5.45 Logons: 0.06 0.12 Executes: 10.54 20.93 Transactions: 0.50
其中:逻辑读(Logical reads):209,462.91*8K = 1636M/s,物理读(Physical reads:):47,085.54*8K = 367M/s。该系统运行在一台非常老的IBM服务器上,上述硬件指标的确让该设备不堪重负了。
- 实例有效性指标
Instance Efficiency Percentages (Target 100%) ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ Buffer Nowait %: 99.49 Redo NoWait %: 99.99 Buffer Hit %: 77.52 In-memory Sort %: 100.00 Library Hit %: 99.80 Soft Parse %: 99.16 Execute to Parse %: 8.94 Latch Hit %: 99.44 Parse CPU to Parse Elapsd %: 48.41 % Non-Parse CPU: 99.97
其中Buffer Hit仅为77.52%,说明数据访问量太大,Buffer Cache根本放不下了,尽管还未到现场,已经隐约感觉到应用的问题了,特别是大量不合理的全表扫描。
- 主要等待事件
Top 5 Timed Events ~~~~~~~~~~~~~~~~~~ % Total Event Waits Time (s) Ela Time -------------------------------------------- ------------ ----------- -------- CPU time 21,188 39.88 latch free 527,508 13,256 24.95 db file scattered read 15,503,335 8,292 15.61 buffer busy waits 2,996,271 5,342 10.06 db file sequential read 58,834,851 4,977 9.37 -------------------------------------------------------------
其中latch free、db file scattered read等待事件非常高,均与应用程序相关。尤其是db file scattered read等待事件直接表示全表扫描。
总之,上述各类指标均表明由于应用程序存在一定质量问题,导致系统负载非常严重。情况基本摸清楚了,但应用软件性能分析和优化一定要去现场。于是与客户商量,第二天即赶赴了现场。
应用典型问题
在现场分析应用之后,果然发现该系统应用问题较多,但无外乎缺少索引、复合索引次序不对、字段前错误使用函数等典型问题。以下典型语句就是字段前错误使用函数的分析和解决过程。
- 语句运行现状
语句现状:
select count(distinct sfzhm) from rsgl.qk61 where zglbbm = :1 and (mzfse <> 0 or tdze1 <> 0 or tdze2 <> 0 or tdze3 <> 0) and lxylfse = 0 and (to_char(sj, 'YYYY.MM') = to_char(:2, 'YYYY.MM')) and (scbj <> 'T' or scbj is null) and substr(dwbm, 1, length(:3)) = :4
执行计划如下:

可见,目前该语句对rsgl.qk61表进行不合理的全表扫描。
- 分析及优化建议
根据现场分析及与应用开发人员的沟通,该语句主要通过时间(SJ)、单位代码(DWDM)两个字段进行查询,而目前缺乏这两个字段的索引。同时该语句在SJ、DWDM字段前均有函数存在,并且substr(dwbm, 1, length(:3))还带有函数length。因此,优化建议如下:
- 创建如下复合索引
create index idx_ora_1 on RSGL.qk61(substr(dwbm, 1, 12), to_char(sj, ‘YYYY.MM’)) tablespace RSGL;
create index idx_ora_2 on RSGL.qk61(substr(dwbm, 1, 15), to_char(sj, ‘YYYY.MM’)) tablespace RSGL;
create index idx_ora_3 on RSGL.qk61(substr(dwbm, 1, 18), to_char(sj, ‘YYYY.MM’)) tablespace RSGL;
create index idx_ora_5 on RSGL.qk61(substr(dwbm, 1, 12), to_char(sj, ‘YYYY.MM.DD’)) tablespace RSGL;
create index idx_ora_6 on RSGL.qk61(substr(dwbm, 1, 15), to_char(sj, ‘YYYY.MM.DD’)) tablespace RSGL;
create index idx_ora_7 on RSGL.qk61(substr(dwbm, 1, 18), to_char(sj, ‘YYYY.MM.DD’)) tablespace RSGL;
- 应用语句进行一定改造
为顺利使用上述新建索引,应用语句需要进行一定改造。具体为去掉substr(dwbm, 1, length(:3))中的length函数,而修改为实际长度。例如:substr(dwbm, 1, 12),substr(dwbm, 1, 15),substr(dwbm, 1, 18)等。
通常而言,针对字段前错误使用函数问题的最有效解决方式是修改程序,但考虑该系统的应用软件开发太久远,甚至开发商都找不到了,现在是客户自己在维护程序。因此,只好采取这种创建函数索引,并请客户对应用程序进行一定修改的措施了。感谢客户,更感谢该客户领导,因为是位白发斑斑的领导亲自修改的程序。呵呵。
优化器和统计信息采集
目前,该系统没有采集统计信息,即优化器运行在RBO模式下。但是,上述优化建议的函数索引只能在CBO模式下启动。因此,需要进行统计信息采集,将优化器切换到CBO模式。
先感叹一下:很多客户都不知道优化器和统计信息采集的概念和重要性,CBO不仅能整体上更好地保证应用软件性能,而且也是基于函数索引、Bitmap索引、物化视图等高级技术使用的前提条件。
该系统数据量不大,另外时间紧张,先采取简单策略,基于整个数据库收集统计信息吧,脚本如下:
rq="start time":`date +"%Y-%m-%d %H:%M:%S"` echo $rq>>/DMCDBS01/oracle/script/stats.log sqlplus /nolog <<EOF connect / as sysdba; exec DBMS_STATS.GATHER_DATABASE_STATS (estimate_percent=>10, Degree=>8, Cascade=>TRUE, Granularity=>'ALL'); EOF rq="stop time":`date +"%Y-%m-%d %H:%M:%S"` echo $rq>>/DMCDBS01/oracle/script/stats.log
该系统业务不太复杂,数据量处于缓慢增长,因此暂时采取每月15日18:00自动收集一次吧。脚本如下:
# crontab –l
00 18 15 * * su – oracle -c /DMCDBS01/oracle/script/stats_ora9.sh > /tmp/stats_ora9.out 2>&1
优化效果对比
忙乎半天,一定要让客户,特别是客户领导看到优化效果。而且不仅要看到具体数字,还一定要图文并茂,让领导看到图表。—- 刚加入Oracle的时候,就被老员工教育道:在Oracle工作第一要Work Hard,第二还要Work Smartly。呵呵。
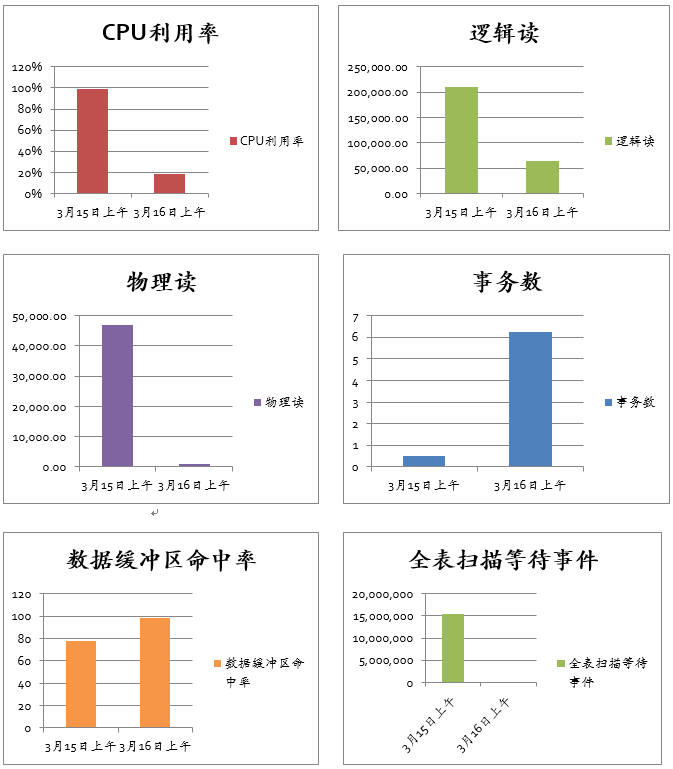
以下就是优化前(3月15日上午)与优化后(3月16日上午)的同期性能数据对比:
| 相关指标 | 3月15日上午 | 3月16日上午 |
| CPU利用率 | 99% | 19% |
| 逻辑读 | 209,462.91 | 64,309.52 |
| 物理读 | 47,085.54 | 849.51 |
| 事务数 | 0.50 | 6.24 |
| 数据缓冲区命中率 | 77.52 | 98.68 |
| 全表扫描等待事件 | 15,503,335 | 93,447 |
一定要给领导看如下的图,多么漂亮、醒目,领导别提多开心了,性能优化其实也是件痛并快乐着的事情。
该案例的启示
之所以描述这个技术上并不太复杂的案例,主要目的是试图诠释如下一些观点:
- 自底向上性能优化方法论的合理运用
如本章第一节所述,从Oracle公司而言,性能优化方法论主要分为自顶向下和自底向上两种。前者是指在项目设计、开发、测试、上线、运维等全方位展开性能方面工作的一种方法论,更适合于一个新系统的建设过程。而后者是当一个已经运行的生产系统出现严重的性能问题时,从IT系统层次而言,需要从硬件、系统软件、应用软件等方面去逐步分析和解决问题的过程。同时,从时间关系角度,是从生产环境定位关键问题,逐步回溯到开发乃至设计等阶段的问题的过程。
上述案例主要运用了自底向上方法论。即针对一个从未接触过的生产系统出现的性能问题,我们先了解系统硬件环境和配置,以及系统资源消耗情况等,进而分析Oracle层面的相关指标和等待事件,从而基本确定问题范围主要是应用问题。再进一步,我们在现场详细分析最消耗资源的SQL语句情况,从而找出具体原因和解决办法。
- 应用是影响性能问题的最重要因素
上述案例再次验证一个观点:应用是影响性能问题的最重要因素。实际上,该案例的直接原因还是最基础的索引策略问题,最有效的解决办法无外乎是创建了几个基于函数的索引而已。
国内有太多的系统由于在索引策略存在问题,而导致了太严重的性能问题。
- 性能问题涉及应用开发和运行维护多个层面
上述案例的直接解决办法是创建了几个基于函数的索引,但为了保证解决办法的有效实施,还必须通过统计信息的采集,将优化器从RBO转换成CBO,而这方面工作应该是DBA所为。可见,性能问题的确涉及应用开发和运行维护多个层面。
尽管Oracle公司从10g开始已经提供自动统计信息采集功能,从而尽量让应用程序运行在更先进的CBO模式下。但作为应用开发人员,特别是DBA,还是应该全面掌握技术原理,这样才能在整体上为应用软件性能最优化提供保证。
以本人的经验,国内大部分企业级客户在优化器和统计信息采集方面已经有了很强的意识,甚至很丰富的实施经验。但大部分中小型客户仍然缺乏这方面知识和经验,也是这些系统整体性能不佳的重要原因之一。
4.4 某综合报表平台的优化
系统运行现状
某银行的综合报表平台出现了严重的性能问题,其ETL过程经常运行长达数小时、甚至10余个小时。于是,作为原厂商服务售前人员,提前去客户现场踩点了。
- 系统环境
该系统的配置和数据库总体情况:
| 系统名称 | 数据库及版本 | OS | HA软件及版本 | 数据库架构 | 数据库服务器型号与配置 |
| 综合报表平台 | Oracle 10.2.0.4 | AIX 5.3 | HACMP | RAC | IBM P595
12Core(4.2GHz/Power6 CPU) 71680M 内存 |
| Oracle 10.2.0.4 | AIX 5.3 | HACMP | RAC | IBM P595
12Core(4.2GHz/Power6 CPU) 71680M 内存 |
- 采样分析周期
我们分别对如下时间段的AWR报告进行了分析:
- 2013年1月4 – 6日交易高峰时段
- 1月2日的2012年终批处理
- 1月12、13、15、16日的2013年日终批处理
经初步分析,无论交易高峰时段,还是年终批处理和日终批处理,该系统的性能问题都比较严重。以下我们仅以1月4日上午交易高峰时段的 AWR报告进行深入分析。
- 操作系统总体状况
| Statistic | Total | 利用率 |
| BUSY_TIME | 5,255,620 | 17% |
| IDLE_TIME | 20,665,708 | 68% |
| IOWAIT_TIME | 4,331,082 | 14% |
| SYS_TIME | 1,388,394 | 5% |
| USER_TIME | 3,867,226 | 12% |
可见,在此期间系统CPU空闲率为68%,使用率为17%,而IOWait达到14%。说明该系统存储系统效率不高,成为该系统一个重要瓶颈。难怪乎客户吵吵嚷嚷说存储系统有问题,要迁移到更高端存储去。也特别要谢谢我的同事前期给客户洗脑比较有成效,因为客户还要把数据从裸设备迁移到Oracle ASM中去,呵呵。
- 数据库总体负载指标
| Per Second | Per Transaction | |
| Redo size: | 529,584.40 | 45,824.07 |
| Logical reads: | 62,949.86 | 5,446.95 |
| Block changes: | 261.27 | 22.61 |
| Physical reads: | 3,608.92 | 312.27 |
| Physical writes: | 30.28 | 2.62 |
| User calls: | 6,318.57 | 546.74 |
| Parses: | 2,101.75 | 181.86 |
| Hard parses: | 61.70 | 5.34 |
| Sorts: | 131.34 | 11.36 |
| Logons: | 0.08 | 0.01 |
| Executes: | 2,697.05 | 233.37 |
| Transactions: | 11.56 |
- 逻辑读/秒非常高,达到62,949.86*32K = 1967M/秒
- I/O读也非常高,达到3,608.92*32K = 112M/秒
- 硬解析比较高,Hard Parses/秒= 61.70,该指标正常值应该低于10次/秒,目前指标说明应用软件存在没有合理使用绑定变量的情况。
- 命中率指标
| Buffer Nowait %: | 97.24 | Redo NoWait %: | 100.00 |
| Buffer Hit %: | 94.48 | In-memory Sort %: | 100.00 |
| Library Hit %: | 93.00 | Soft Parse %: | 97.06 |
| Execute to Parse %: | 22.07 | Latch Hit %: | 98.88 |
| Parse CPU to Parse Elapsd %: | 23.19 | % Non-Parse CPU: | 96.01 |
- Buffer Hit %:命中率不高,说明应用方面存在较为严重的问题,例如不合理的全表扫描。
- Library Hit %:和Execute to Parse %:命中率不高,再次说明应用软件没有合理使用绑定变量。
- 主要等待事件
| Event | Waits | Time(s) | Avg Wait(ms) | % Total Call Time | Wait Class |
| gc buffer busy | 18,021,5524 | 458,799 | 25 | 54.1 | Cluster |
| db file sequential read | 30,079,633 | 132,923 | 4 | 15.7 | User I/O |
| gc cr multi block request | 4,486,393 | 49,507 | 11 | 5.8 | Cluster |
| read by other session | 736,260 | 40,725 | 55 | 4.8 | User I/O |
| gc cr block lost | 93,394 | 39,559 | 424 | 4.7 | Cluster |
- gc buffer busy等待事件最高,说明RAC节点间访问冲突和流量比较大。
- db file sequential read等待事件比较高,表示系统存在大量因为索引而出现的等待事件。原因无外乎以下几种:
- 应用软件质量较高,大量SQL语句均采用了索引。
- 可能有一些索引没有用上,DML操作时,导致索引的维护工作量增加,即产生了大量不必要的索引I/O。
- 由于频繁的DML操作,可能导致很多索引碎片,增加了索引I/O开销。
- 部分索引设计不合理。虽然使用了索引,但实际是索引扫描,类似于全表扫描。
- RAC统计信息分析
| Per Second | Per Transaction | |
| Global Cache blocks received: | 949.99 | 82.20 |
| Global Cache blocks served: | 924.65 | 80.01 |
| GCS/GES messages received: | 6,476.55 | 560.41 |
| GCS/GES messages sent: | 6,309.31 | 545.93 |
| DBWR Fusion writes: | 3.53 | 0.31 |
| Estd Interconnect traffic (KB) | 62,485.76 |
RAC节点间流量达到62M/S,说明RAC节点间访问冲突和流量的确比较大。
- 时间模型指标
| Statistic Name | Time (s) | % of DB Time |
| sql execute elapsed time | 839,987.35 | 99.00 |
| DB CPU | 34,438.88 | 4.06 |
| parse time elapsed | 11,056.69 | 1.30 |
| hard parse elapsed time | 9,959.10 | 1.1 |
可见,该系统的sql execute elapsed time达到99%。而DB CPU只有4.06%,说明该系统大量时间消耗在等待I/O。不仅I/O量大,而且存储设备性能不佳。
- I/O指标
以下是各表空间的I/O性能指标:
| Tablespace | Reads | Av Reads/s | Av Rd(ms) | Av Blks/Rd | Writes | Av Writes/s | Buffer Waits | Av Buf Wt(ms) |
| TBS_ADBCDW | 31,857,511 | 2,953 | 8.77 | 1.18 | 478 | 0 | 18,680,562 | 27.20 |
| TBS_ADBCBI | 849,626 | 79 | 4.14 | 1.00 | 193,616 | 18 | 25,646 | 57.35 |
| TBS_ADBCIRPT | 128,476 | 12 | 21.72 | 1.16 | 63,766 | 6 | 2,086 | 54.27 |
| TBS_IDX_ADBCDW | 174,805 | 16 | 15.77 | 1.42 | 1,349 | 0 | 17,394 | 14.31 |
| TBS_BDS | 13,570 | 1 | 6.07 | 1.00 | 21,038 | 2 | 0 | 0.00 |
| SYSTEM | 17,246 | 2 | 16.71 | 1.94 | 3,548 | 0 | 560 | 44.21 |
| UNDOTBS1 | 3,386 | 0 | 14.02 | 1.00 | 5,796 | 1 | 259 | 0.00 |
| SYSAUX | 3,392 | 0 | 15.38 | 1.02 | 1,416 | 0 | 0 | 0.00 |
| TBS_ADBCTEMP | 1,461 | 0 | 7.30 | 3.43 | 1,159 | 0 | 0 | 0.00 |
| UNDOTBS2 | 97 | 0 | 29.38 | 1.00 | 32 | 0 | 680 | 47.18 |
| TEMP | 18 | 0 | 15.56 | 1.00 | 0 | 0 | 0 | 0.00 |
| USERS | 5 | 0 | 28.00 | 1.00 | 2 | 0 | 0 | 0.00 |
可见,多数表空间的平均读达到10ms以上,再次说明该系统的存储设备I/O读写性能不佳。
总之,通过对上述多方面指标分析,已经总结出该系统的典型问题了:第一,存储系统的确有问题,第二,应用一定有问题。但应用问题具体在哪儿呢?
典型应用问题分析
虽然该系统存储设备效率不高是一个重要问题,但我们认为数据库设计不合理和应用软件方面存在的问题,才是导致该系统性能不佳的最主要原因。
以下我们对该系统一个典型应用问题进行深入分析:
- 语句现状
以下语句是2013年1月4日上午最消耗资源的语句:
| Elapsed Time (s) | CPU Time (s) | Executions | Elap per Exec (s) | % Total DB Time | SQL Id | SQL Module | SQL Text |
| 19,578 | 658 | 3 | 6525.84 | 2.31 | 0w08q2c6s0dtx | select * from ( select row$_.*… |
可见该语句运行了6525.84秒,将近2个小时。该语句非常长,我们仅截取其中一小段核心语句进行深入分析:
select sum(nvl(a.LOAN_BAL, 0)) as O4,
a.DUE_BILL_ID as F4,
SUBSTR(a.ORG_CD, 1, 6) as D4,
SUBSTR(a.ORG_CD, 1, 4) as B4,
SUBSTR(a.ORG_CD, 1, 2) as A4
from ADBCDW.AC_HB_DUE_BILL_NPL_MONTH a
where (SUBSTR(a.RPT_END_DATE, 1, 6) = ‘201112’)
and (a.ORG_CD like ‘3599%’)
and ((1 > 2 OR a.ORG_CD like ‘3599%’) AND
(SUBSTR(a.NPL_FORM_DATE, 1, 4) < ‘2012’))
group by a.DUE_BILL_ID,
SUBSTR(a.ORG_CD, 1, 6),
SUBSTR(a.ORG_CD, 1, 4),
SUBSTR(a.ORG_CD, 1, 2)
PLAN_TABLE_OUTPUT
—————————————————————————————————————————————————————-
Plan hash value: 2416238426
—————————————————————————————————————–
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
—————————————————————————————————————–
| 0 | SELECT STATEMENT | | 3 | 192 | 69364 (2)| 00:20:49 | | |
| 1 | HASH GROUP BY | | 3 | 192 | 69364 (2)| 00:20:49 | | |
| 2 | PARTITION RANGE ALL| | 4 | 256 | 69363 (2)| 00:20:49 | 1 | 38 |
|* 3 | TABLE ACCESS FULL | AC_HB_DUE_BILL_NPL_MONTH | 4 | 256 | 69363 (2)| 00:20:49 | 1 | 38 |
—————————————————————————————————————–
Predicate Information (identified by operation id):
—————————————————
3 – filter(“A”.”ORG_CD” LIKE ‘3599%’ AND “A”.”ORG_CD” LIKE ‘3599%’ AND
SUBSTR(“A”.”RPT_END_DATE”,1,6)=’201112′ AND SUBSTR(“A”.”NPL_FORM_DATE”,1,4)<‘2012’)
可见,该语句对AC_HB_DUE_BILL_NPL_MONTH进行全表扫描,而该表记录达到7959560条,而满足上述语句条件的记录仅为17条,显然全表扫描非常不合理。这也是该系统I/O量大的重要原因。
- 原因分析
首先,我们分析该表按RPT_END_DATE字段进行了按月的范围分区,但RPT_END_DATE字段设计为VARCHAR2(8)。如按月查询,语句中将写成SUBSTR(a.RPT_END_DATE, 1, 6) = ‘201112’。这样,将导致Oracle无法采用分区裁剪功能,也无法使用建立在RPT_END_DATE字段之上的索引,最终导致全表扫描。
其次,我们分析该表的现有索引如下:
TABLE_OWNER INDEX_NAME COLUMN_NAME COLUMN_POSITION
—————————— —————————— —————————— —————
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 RPT_END_DATE 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 DUE_BILL_ID 2
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 ORG_CD 3
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 PROD_CD 4
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 CURR_CM_CD 5
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 INDUS_TYPE_CD 6
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 RISK_5_TYPE_CD 7
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 RISK_12_TYPE_CD 8
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_0 LOAN_INTO_CD 9
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_1 RISK_5_TYPE_CD 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_1 RPT_END_DATE 2
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_2 RISK_12_TYPE_CD 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_2 RPT_END_DATE 2
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_3 RISK_5_TYPE_CD 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_4 RISK_12_TYPE_CD 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_B1 ITEM_CBS_OUT_CD 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_B1 RPT_END_DATE 2
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_PK CUST_ID_CM 1
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_PK DUE_BILL_ID 2
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_PK ORG_CD 3
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_PK ORG_CD_CM 4
ADBCDW AC_HB_DUE_BILL_NPL_MONTH_PK RPT_END_DATE 5
可见,索引设计方面也存在复合索引设计原则性不明确、索引过多等问题。
- 优化建议
- 首先,需要将RPT_END_DATE字段修改为Oracle的Date类型。
- 其次,需要重新调整分区方案
- 应用软件需要进行必要的调整。例如将SUBSTR(RPT_END_DATE, 1, 6) = ‘201112’修改为RPT_END_DATE between to_date(‘2012.12’,’YYYY.MM’) and to_date(‘2013.01’,’YYYY.MM’)
- 重新设计和梳理索引。例如,根据上述语句设计(RPT_END_DATE, ORG_CD)索引等。
应用优化措施测试情况
为验证上述应用优化措施效果,我们于2月4日在现场进行了一定的测试工作。以下是相关细节:
- 优化前情况
SQL> /
COUNT(*)
———-
17
Elapsed: 00:04:08.24
Execution Plan
———————————————————-
Plan hash value: 2114726402
—————————————————————————————————————–
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
—————————————————————————————————————–
| 0 | SELECT STATEMENT | | 1 | 31 | 69363 (2)| 00:20:49 | | |
| 1 | SORT AGGREGATE | | 1 | 31 | | | | |
| 2 | PARTITION RANGE ALL| | 4 | 124 | 69363 (2)| 00:20:49 | 1 | 38 |
|* 3 | TABLE ACCESS FULL | AC_HB_DUE_BILL_NPL_MONTH | 4 | 124 | 69363 (2)| 00:20:49 | 1 | 38 |
—————————————————————————————————————–
Predicate Information (identified by operation id):
—————————————————
3 – filter(“A”.”ORG_CD” LIKE ‘3599%’ AND “A”.”ORG_CD” LIKE ‘3599%’ AND
SUBSTR(“A”.”RPT_END_DATE”,1,6)=’201112′ AND SUBSTR(“A”.”NPL_FORM_DATE”,1,4)<‘2012’)
Statistics
———————————————————-
0 recursive calls
0 db block gets
153017 consistent gets
109014 physical reads
0 redo size
515 bytes sent via SQL*Net to client
492 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
- 优化后情况
SQL> select sum(nvl(a.LOAN_BAL, 0)) as O4,
2 a.DUE_BILL_ID as F4,
3 SUBSTR(a.ORG_CD, 1, 6) as D4,
4 SUBSTR(a.ORG_CD, 1, 4) as B4,
5 SUBSTR(a.ORG_CD, 1, 2) as A4
6 from “ADBCDW”.”AC_HB_DUE_BILL_NPL_MONTH_ora” a
7 where RPT_END_DATE between to_date(‘2012.12′,’YYYY.MM’) and to_date(‘2013.01′,’YYYY.MM’)
8 and (a.ORG_CD like ‘3599%’)
9 and ((1 > 2 OR a.ORG_CD like ‘3599%’) AND
10 (SUBSTR(a.NPL_FORM_DATE, 1, 4) < ‘2012’))
11 group by a.DUE_BILL_ID,
12 SUBSTR(a.ORG_CD, 1, 6),
13 SUBSTR(a.ORG_CD, 1, 4),
14 SUBSTR(a.ORG_CD, 1, 2)
15 /
17 rows selected.
Elapsed: 00:00:00.97
Execution Plan
———————————————————-
Plan hash value: 1319675372
————————————————————————————————————————————
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
————————————————————————————————————————————
| 0 | SELECT STATEMENT | | 3 | 192 | 293 (1)| 00:00:06 | | |
| 1 | HASH GROUP BY | | 3 | 192 | 293 (1)| 00:00:06 | | |
| 2 | PARTITION RANGE ITERATOR | | 3 | 192 | 292 (1)| 00:00:06 | 37 | 38 |
|* 3 | TABLE ACCESS BY LOCAL INDEX ROWID| AC_HB_DUE_BILL_NPL_MONTH_ora | 3 | 192 | 292 (1)| 00:00:06 | 37 | 38 |
|* 4 | INDEX RANGE SCAN | ORA_IND_0 | 1731 | | 214 (1)| 00:00:04 | 37 | 38 |
————————————————————————————————————————————
Predicate Information (identified by operation id):
—————————————————
3 – filter(SUBSTR(“A”.”NPL_FORM_DATE”,1,4)<‘2012’)
4 – access(“RPT_END_DATE”>=TO_DATE(‘ 2012-12-01 00:00:00’, ‘syyyy-mm-dd hh24:mi:ss’) AND “A”.”ORG_CD” LIKE ‘3599%’ AND
“RPT_END_DATE”<=TO_DATE(‘ 2013-01-01 00:00:00’, ‘syyyy-mm-dd hh24:mi:ss’))
filter(“A”.”ORG_CD” LIKE ‘3599%’ AND “A”.”ORG_CD” LIKE ‘3599%’)
Note
—–
– dynamic sampling used for this statement
Statistics
———————————————————-
4 recursive calls
0 db block gets
370 consistent gets
242 physical reads
0 redo size
1685 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
17 rows processed
- 优化对比情况
| 优化前 | 优化后 | |
| 响应速度 | 00:04:08.24 | 00:00:00.97 |
| 内存消耗 | 153017 *32K = 4,781M | 370*32K=11.56M |
| I/O消耗 | 109014 *32K= 3,406M | 242*32K=7.56M |
可见优化效果非常明显,对比图就免了,不臭显摆了,呵呵。
该案例的感悟
读者已经看见,该案例的分析和优化过程同样采取了自底向上方法论,即首先通过分析硬件、操作系统、数据库系统层面指标,准确分析出了存储系统的确存在I/O效率不高的问题。但真正最影响系统处理能力的还是数据库设计和应用问题,包括字段类型设计问题、分区问题、索引设计策略问题等,而且相比存储系统的更新换代,以及从裸设备迁移到ASM,应用优化改造是投入少、见效快的捷径。甚至在该项目上,只要应用优化到位,也许现有存储设备都足以胜任,而不需要进行存储设备的更新换代和迁移到ASM了。
但是,现在该回到我作为服务售前人员的角色,考虑商务问题了。如果我以应用分析和优化为主去提Oracle服务内容,连该银行处长都说这样对你们Oracle公司绝对不利,因为他的领导觉得应用优化是开发商的份内工作,你们Oracle公司必须提开发商不擅长的工作。于是,我只好在服务方案里面大谈现有存储设备的缺陷,以及存储迁移和改造服务方案,诸如:存储迁移需求分析、ASM存储方案设计、存储迁移方案设计、存储迁移测试和正式实施服务… …。
应用性能分析和优化服务反而成了陪衬,一带而过了,真是本末倒置啊。这就是国内IT行业的生态环境,很多事情要拧把着来。而且我也成了国内IT行业动辄通过采购硬件,靠硬件来缓解系统压力的简单、粗暴建设方法的“助纣为虐”者了。为了给Oracle公司赚几个服务钱,良心谴责啊,呵呵。
4.5 适合于数据仓库的Bitmap索引
“冲着第11章,买了!”
《品悟性能优化》一书出版之后,本人一直比较关注广大网民和读者的评价。一天发现一名网友写下了这样的评语:“冲着第11章 数据仓库中的性能优化,买了!”该网友一定为数据仓库性能问题所困,但愿该章内容能为他提供一定的帮助,没有让他失望。
其实在《品悟》一书中,第11章已经是内容最丰富、篇幅最大的一章,以至于编辑想让我拆分成两章。但考虑书的整体布局和内容的平衡性,还是只写成了一章。于是,在内容方面只能有所取舍了。
Oracle数据仓库技术的确博大精深,不仅有《品悟》一书中描述的并行处理、外部表、MERGE语句、物化视图、表空间传输等技术,还有更多当时限于篇幅和整体结构没有叙述的技术,例如Bitmap索引、Bitmap Join索引、Star Join、Star Transformation等,只好寄希望于本书进行一定的弥补了。
位图(Bitmap)索引长什么样?
就象《品悟》一书所言,Oracle的索引技术非常丰富,想做个懂Oracle各种索引的专家其实非常不易。Oracle除最经典的B*树索引之外,另外一个典型索引就是位图(Bitmap)索引。
创建Bitmap索引的语法非常简单,例如:
SQL> CREATE BITMAP INDEX prod_supplier_id ON products (supplier_id);
普通B*树索引是采用一个平衡树来组织和存储被索引字段值,并通过该索引进行数据检索。与之不同的是,Bitmap索引是通过一个位图矩阵来表示被索引字段值与实际数据的关系,并进行数据检索。例如,上述语句假设Supplier_ID字段只有4个值:1,2,3,4,则该Bitmap索引的示意图如下:

即每个Supplier_ID字段值都有一个位图(Bitmap),Products表的每条记录根据Supplier_ID字段的具体值,在相应的位图中进行标记,1表示有,0表示无。例如上述第1条记录的Supplier_ID值为‘1’,则在Supplier_ID值为1的位图中标记为1;第2条记录的Supplier_ID值为‘2’,则在Supplier_ID值为2的位图中标记为1;第3条记录的Supplier_ID值为‘3’,则在Supplier_ID值为3的位图中标记为1;第4条记录的Supplier_ID值为‘4’,则在Supplier_ID值为4的位图中标记为1;第5条记录的Supplier_ID值为‘2’,则在Supplier_ID值为2的位图中标记为1…以此类推。
Oracle在每个位图头中保存了属于该位图记录的起始Start ROWID和End ROWID。基于这些ROWID值,Oracle再通过一个内部算法将该位图表示的记录映射成实际的ROWID值。简言之,大家知道Oracle能有效地将位图信息转换成指向实际记录的指针(ROWID),就OK了。
位图(Bitmap)索引的适应场景
- Bitmap索引适合于低可选性(Cardinality)的字段
如果某个字段的不同值占整个表记录的1%以下,则称之为低可选性(Cardinality)的字段。例如,上述Product表假设有1万条记录,而Supplier_ID只有4个不同的值,则Supplier_ID就是低可选性(Cardinality)的字段,适合于创建Bitmap索引。
- 运用Bitmap索引进行查询和统计
在很多情况下,运用Bitmap索引进行查询和统计,效率比B*树索引更高。例如上例中,假设客户查询Supplier_ID为‘3’的Products总数:
SQL> select count(*) from Products where supplier_ID=‘3’;
此时,Oracle根本不需要访问Products表,而只是需要在Supplier_ID位图索引的supplier_ID=‘3’的位图中,将标志位为1的记录汇总一遍即可,显然,查询效率将非常高。示意图如下:

- Bitmap索引适合于复杂逻辑条件
以如下语句为例:
SQL> SELECT * FROM products
2 WHERE supplier_id = 3
3 AND prod_pack_size = ‘card box’;
假设查询语句涉及多个字段的各种复杂逻辑,例如上述supplier_id和prod_pack_size两个条件进行与运算,假设两个字段均创建了位图索引,则Oracle可利用位图按位与运算,快速完成相关运算,搜索到相关记录。示意图如下:

正因为Bitmap索引的这种按位逻辑运算能力,使得越复杂的逻辑条件,Bitmap索引的性能优势更为明显。
位图(Bitmap)索引的优缺点
位图索引的优点非常明显。首先,位图索引是按Bit位表示索引,而且Oracle采用了压缩算法,因此相比普通B*树索引空间消耗更小。其次如上所述,位图(Bitmap)索引非常适合于一些统计运算和复杂逻辑运算的场景,包括各种即席(ad hoc)查询场景。因此,总体上位图索引主要适合于数据仓库或大型统计分析系统。
位图索引的缺点也非常明显。由于Oracle进行各种DML操作时,对位图索引加锁的最小单元不是Bit位,即不是行级锁,而是按位图段(Bitmap Segment)进行加锁,而一个位图段可能达到一个数据块的一半,因此,被锁住的记录可能更多。这样,在修改数据并发量较大的交易系统(OLTP)中,不太适合于设计位图索引。
某年在某国税系统,突然发生核心生产交易系统被挂起的现象,正好本人在现场工作。经分析后,发现是有人在最核心的交易表上创建了位图索引,当并发访问量增加之后,把该表锁住了。当删除这些不必要的位图索引之后,系统恢复了正常。之后本人听到了客户的轻声嘀咕:“是不是Oracle罗工建的这个索引啊?因为只有他可能才知道这种索引。”本人当时闻之报之以一笑:“正因为我知道位图索引的优缺点,才不会在生产系统创建这种索引。除非我想搞破坏。呵呵。”
4.6 半小时都没听懂的Bitmap Join索引
半小时没听懂一句
N年前与公司几位同事一同去某客户现场,介绍当年炙手可热的9i新技术。一位同事开始宣讲一个叫Bitmap Join索引的新特性,只见他又是PPT,又是在展板上写写画画,滔滔不绝了几乎半个小时,我居然一句也没听懂!
晚上回到酒店,非常沮丧、知耻后勇的我赶紧找出相关资料仔细研究起来。大约也是半个小时,特别是结合例子反复阅读了3遍之后,我终于搞懂了!待仔细回忆白天那位同事的厥词时,才猛然反应过来,他自己根本没搞懂,难怪他讲了半天,我依然如坠云雾之中。
世上就有这样的能人,自己都不知所云,但那个做派俨然象个大专家。Oracle公司也不乏这样挺能装的人。哈哈。
半小时之内让你搞懂Bitmap Join索引
下面我也希望在半小时之内,让你理解Bitmap Join索引,一定不是装的,呵呵。
欲快速、深入了解某个深奥的技术原理,还是从例子说起。假设有销售明细表(Sales)和客户资料表(Customers),二者形成1对多的主、外键关系。即一个客户可能有多个销售记录,一个销售记录只对应一个客户。

前面我们介绍的Bitmap索引是针对单表的,假设我们如上图右上角所示,通过sales表和customers表的连接操作,在Sales表上面创建基于customer表cust_city字段的Bitmap索引,则该索引叫做Bitmap Join索引。该索引如上图下部所示。假设customer表的cust_city字段有Rognes、Aix-en-Provence、Marseille等值,则每个值都创建了对应的位图(bitmap),而位图中的每个bit位表示Sales表的销售记录所对应客户所在的城市信息。例如,假设Sales表中第1条销售记录所对应客户位于Rognes,则在Rognes位图第1个bit位上标识为1;假设第2条销售记录所对应客户位于Marseille,则在Marseille位图第2个bit位上标识为1;以此类推。
这样,当出现如下语句时:
SELECT SUM(s.amount_sold)
FROM sales s, customers c
WHERE s.cust_id = c.cust_id
AND c.cust_city = ‘Marseille’;
Oracle只要访问该Bitmap Join索引的’Marseille’位图,就知道Sales表哪些销售记录是卖给位于Marseille的客户了,再访问Sales表,就可完成相应的汇总运算。因为根本没有访问customer表,所以执行效率大幅度提升。
事实上,Bitmap Join索引就是先进行两个表的预连接,在以后频繁进行这两个表连接和运算时,就避免了两个表非常消耗资源的连接操作了。
理解了吗?没理解,就象我当年一样,再看两遍。呵呵。
我们再深入研究一下语句的执行计划,帮助大家理解。以下是使用常规技术的执行计划:
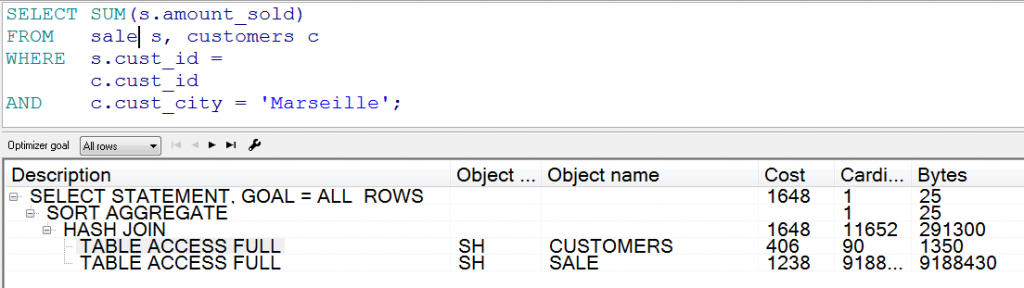
可见,执行计划是简单的两个表全表扫描和HASH_JOIN连接操作。
以下是采用Bitmap Join技术的执行计划:
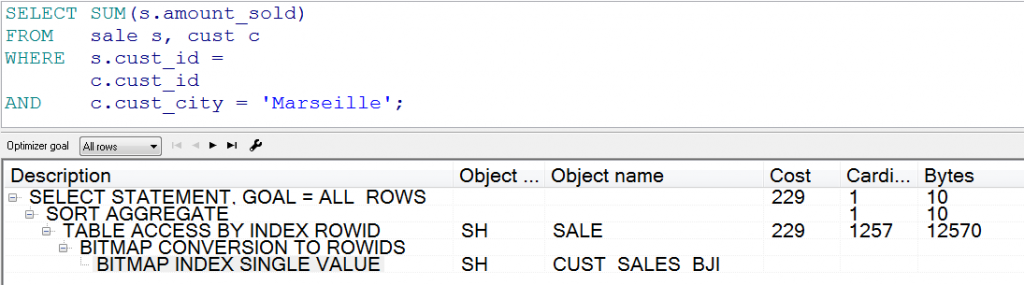
可见,Oracle现在通过Bitmap Join索引CUST_SALES_BJI访问SALE表,而根本没有访问CUST表,执行效率提升可想而知。例如上述测试例子中,原来语句的执行计划成本为1648,而新执行计划成本仅为229。
何时使用Bitmap Join索引?
任何一种技术的使用都应该充分考虑应用需求和技术本身特点,包括技术的局限性。针对Bitmap Join索引的使用,我们认为应考虑如下特点:
- 首先,从应用特点而言,应是多个大表的连接操作,例如上述 Sales和 Customers表都可能很大。
- 其次,应用是基于低可选性字段进行统计运算,例如上述Customers表的cust_city字段就是低可选性字段,并且对该字段进行条件运算。
- 第三,与普通Bitmap索引相似,对这些表的DML操作的并发度应该较低,否则会导致大量记录被锁住,影响系统正常的DML操作。
什么叫精通Oracle?
写完上述Bitmap Join索引,突然想起10多年前的一件往事。作为休闲之作,权当大家在辛苦研究Bitmap Join索引之后的片刻小憩。
话说10多年前在某网站从事专职DBA时,由于业务高速发展需要,网站CTO决定再扩招一名DBA。于是,我接过一大叠简历进行筛选,其中大部分是刚毕业的大学生求职简历。让我惊讶的是,怎么现在的大学生们都是“精通Oracle、DB2、Informix、Sybase”四大数据库的全才啊?当时我心想,我都干了10多年Oracle开发工作了,才刚学会看SQL语句执行计划,现在大学的数据库课程是不是四大数据库都教啊?或者现在的大学生是不是大把时间在外面公司实习啊?
于是,我抽取了两份最“靓丽”的简历,并联系他们来面试了。待我与他们一交流才知道,原来大学生们其实就只懂Select、Insert、Update、Delete四条最基本的语句,由于四大数据库厂商都有这四条基本命令,因此大家都成了精通四大数据库的专家了,真让我啼笑皆非,呵呵。给刚毕业的大学生们一个忠告:千万别把自己包装成什么都精通的通才,如果有这样的人,他肯定来自于另一个星球。你这样写,有经验的面试官其实知道你只懂Select、Insert、Update、Delete四条语句,因为这几大数据库厂商可能只有这四条基本命令是一样的。
事实上,很多开发人员就凭这四条语句在包打天下。本书的很多内容,就是想告诉开发人员,Oracle不仅有这四条经典的SQL语句,还有exchange、merge、multi-insert、direct-path insert等多种适合于企业级数据处理的语句。千万别在Oracle里面只使用这四条语句,这样就相当于把Oracle用成了DB2,呵呵。
一次典型故障引发的思考
故障的初步了解
2013年夏天的某天,我和服务销售同事一同去某移动公司准备进行数据库云计算和数据库整合的专题技术交流。待我们早晨见面时,发现销售同事眼睛布满血丝。
“老罗啊,昨晚XX移动一个重要系统出现宕机了,害得我一晚都没睡,忙着到处调度资源来现场解决问题”。他苦言道。
“什么原因?解决了吗?”我急切地问道。
“听说是交换机坏了,把数据库写坏了,还没有解决,但工程师已经到现场了,我们也去现场看看吧。”他仍然是语调沉重。
“这故障可能来的太不是时候了,万一数据库都整合了,这一宕机,可是影响一大片业务啊。我们来交流数据库整合,有点火上浇油的味道啊。” 我们一边往客户现场走,我一边与他调侃一下,意在舒缓一下有点紧张的气氛。
待我们赶到现场,发现我们的工程师正在进行紧张的数据库物理备份恢复工作,也才知道问题的初步原因:因为存储交换机故障,导致数据库出现大面积坏块。由于客户系统没有部署容灾系统,于是通过RMAN进行恢复成了主要的恢复手段。
由于仍然需要按照日程安排与客户进行技术交流,于是我和销售也匆匆离开了现场。尽管这次故障的确对这次交流不利,但客户还是对Oracle最新的云计算和数据库整合技术抱以浓厚兴趣,这些内容将在本书后面章节进行介绍。
故障的进一步了解
日后我们在再次拜访该客户时,才知道原来这次故障远不止上述的硬件故障这个天祸那么简单,其实更多的原因还在于人祸,甚至是错上加错、雪上加霜。在问题描述过程中,系统开发和运维人员一直是欲言又止、非常谨慎,不希望我们知道得更多,更担心领导层知道问题的原委而追究相关人员的责任。本人在本章中描述该案例,本意也是在提高数据库备份恢复性能方面。但为了让读者们了解到更真实的故障,并提高相应的防范能力和积累更多经验,本人还是决意在此对该故障进行更全面的描述:
存储交换机硬件故障导致数据库文件被写坏,是该次故障的一个重要原因。但事实上,运维人员的操作失误才是更重要原因:运维人员错误地将一块已经被操作系统使用的盘直接加入到ASM磁盘组中,使得操作系统和Oracle数据库同时对该盘进行操作,从而导致大面积数据库坏块的出现。
为此,建议大家记住ASM的一条最佳实践经验:在添加盘到ASM磁盘组之前,一定要确认该盘是没有被使用的空盘。例如,在AIX平台通过如下命令确认该盘是否为空盘:
# lquery –h /dev/rhdisk2
如果是空盘,上述命令应该返回该盘所有字节为0。
该故障更为雪上加霜的是:运维人员在进行数据库恢复操作时,又对多个设计为nologging方式的表进行了recover操作,进一步导致了大量逻辑坏块的出现,即系统显示大量ORA-1578错误。本书的数据库坏块处理一章,详细描述了该问题的深层次原因。
又一条关于RMAN恢复的最佳实践经验:在进行recover操作之前,一定要检查一下数据库表中是否有设计为nologging方式的表,例如:
SQL> SELECT DISTINCT OWNER , table_name
FROM DBA_TABLES
WHERE LOGGING=’NO’;
请记住,一定不能对设计为nologging方式的表进行recover操作!否则,将导致大量逻辑坏块。
于是,Oracle工程师和客户开发、运维人员一同对这些天灾人祸造成的坏块进行各种手段的恢复:RMAN、DBMS_REPAIR包、设置10231事件、DUL…。在本书数据库坏块处理一章可见相关技术细节。
为什么RMAN恢复那么慢?
在本次故障恢复中,数据库在进行正常recover操作时,出现了恢复效率非常低下的情况,例如为恢复4天数据居然花费了将近2天时间!这才是本节要详细描述的主要内容,即RMAN中的优化策略。
虽然客户强调存储系统为RAID5,I/O处理能力不强,磁带库只有4个Driver等硬件环境因素,但我们认为该系统RMAN方案本身存在的问题,才是导致recover操作效率极低的重要因素。这也是国内大部分Oracle数据库系统的RMAN实施中普遍存在的问题。
- 备份恢复方案现状及问题
该系统目前采用的RMAN备份策略是:每个月进行一次0级全备份,而每天进行归档日志的备份。这也是国内大多数Oracle系统普遍采取的备份方案。该方案在此次事故中的弊端显露无遗。如下图所示:
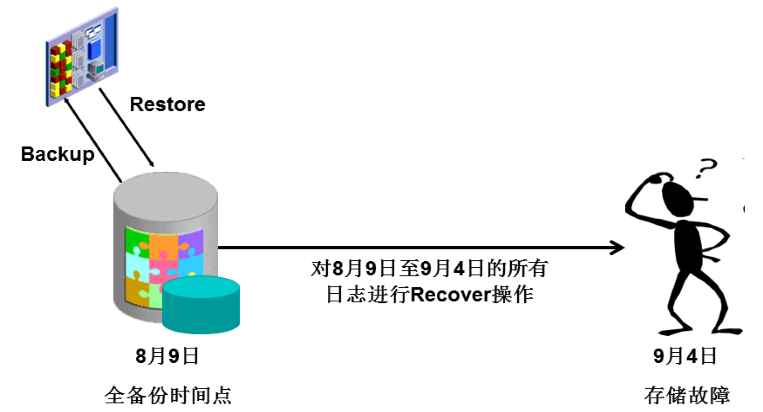
即该系统在8月9日进行了一次0级全备份(Full Backup),在9月4日发生存储故障时,RMAN恢复操作应该是首先将8月9日的全备份数据加载(Restore)回数据库,该库已经达到将近20TB,由于存储设备和磁带库硬件能力有限,据介绍大约花费了10多个小时。而更可怕的是,接下来的动作是需要对8月9日至9月4日的所有归档日志和联机日志进行恢复(Recover)操作,而该系统每天的日志就达到数百GB,为恢复4天日志数据,居然运行了将近2天时间!如果按照这个恢复速度计算,假设恢复到9月4日的最新数据,可能需要10余天!
事实上,后来因为该系统备份操作也出现了问题,8月中旬之后的归档日志没有备份成功。因此,整个RMAN恢复操作被迫中断了,该系统的恢复后来是采取应用层为主的方式进行的。
- 为什么不采取“全量 + 增量”结合的备份策略?
虽然硬件能力有限是导致RMAN恢复操作如此之长的一个重要因素,但更重要的原因在于大量日志文件的Recover操作。尽管Recover操作是Oracle在数据块级进行的物理恢复,但毕竟是逐个DML、DLL的恢复操作,相当于把8月9日至9月4日的全部操作再重复执行一遍。
假设采取如下图所示的“全量+增量”结合的备份策略呢?

即依然假设8月9日进行了一次0级全备份(Full Backup),而在其它日子则每天进行一次1级或2级增量备份,并删除过期归档日志。这样,在9月4日发生故障时,首先需要将8月9日的全备份数据加载(Restore)回数据库;然后,如果是1级增量备份,则需要将8月9日至9月3日每天的增量备份数据也加载回数据库。如果是2级增量备份,则只需要将9月3日的累计增量备份数据加载回数据库;最后,只需要将9月4日的归档日志和联机日志进行恢复(Recover)操作即可。
由于restore操作是将数据库操作结果直接加载回数据库,而日志recover操作是重复执行DML、DDL等操作,该方案的恢复操作效率将显著提高。但是为什么客户不采取这种“全量+增量”结合的备份策略呢?一个重要原因在于Oracle 10g之前提供的增量备份中,尽管增量备份集会小于全库备份集,但备份时间却几乎相等。这是因为即便在增量备份情况下,Oracle仍然需要扫描所有数据文件的所有数据块,逐个判断各个数据块是否发生变化,是否需要进行增量备份。因此,会导致几乎同样的物理读操作和备份时间,也最终导致客户放弃了这种费力不讨好的备份方案。
10g的快速增量备份技术
- 真正的增量备份技术
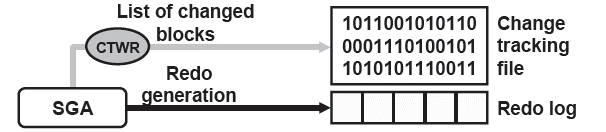
Oracle 10g开始终于提供了真正的增量备份技术。即快速增量备份技术(Fast Incremnental Backup,简称FIB),将有效提高传统增量备份效率。10g在日常运行时,通过新的CTWR后台进程记录变化数据块,并存储在一个专门的变化跟踪位图文件(Change tracking file,CTF)中。RMAN备份时通过扫描该位图文件,而不是扫描整个数据文件,就可获取变化数据块,因此能大幅度提高增量备份效率。以下就是FIB技术的原理图:
- 启动FIB技术
数据库缺省情况下,没有启动FIB技术。通过如下命令可启动FIB技术:
SQL> alter database enable block change tracking using file ‘ +DG_GROUP1’;
上述命令是假设将CTF文件建立在ASM磁盘组中,事实上,Oracle的CTF文件支持普通文件、集群文件、裸设备和ASM文件。启动之后,Oracle将启动新的后台进程CTWR。
- CTF文件大小的估算
CTF文件仅记录发生改变的数据块信息,因此该文件非常小。对于一个数据库系统,可近似推算CTF文件为数据块容量的三十万分之一。例如对于一个450GB的系统,可近似估算需要450GB × 1/300000 = 15MB。然而有两个因素影响CTF文件的大小:
- CTF文件默认起始大小为10MB,当需求超过10MB时,将以10MB为增量增长。因此对于300GB以上的系统,建议CTF文件应为20MB,对于600GB以上的系统,建议CTF文件应为30MB,以此类推。
- 对于每一个数据文件,需要在CTF文件中320K的存储空间。因此,如果系统有很多的小数据文件,例如200个数据文件,则需要200 × 320K = 64MB
总之,一般有个几百兆的CTF文件,就足够管理容量达几十TB的数据库了。
- FIB技术的确认
执行如下命令可确认FIB技术是否启动:
SQL> select * from V$BLOCK_CHANGE_TRACKING
STATUS FILENAME BYTES
ENABLED +DG_GROUP1/cnc/changetracking/ctf.486.684753413 116457472
- 备份恢复脚本的透明
FIB技术对现有备份恢复脚本完全透明,不需要任何修改。
- FIB使用的监控
通过如下命令可分析FIB的使用情况:
SQL> select file#,avg(datafile_blocks),avg(blocks_read),
avg(blocks_read/datafile_blocks) AS PCT_READ_FOR_BACKUP,
avg(blocks)
from v$backup_datafile
where used_change_tracking = ‘YES’
and incremental_level > 0
group by file#;
- FIB使用效果
下面是在某银行一个10TB系统实施 FIB之后的效果对比:
| 备份时间 | 备份方式 | 数据备份时间 | 日志备份时间 | 备份管理工作 | 总时间 |
| 4月21日 | 传统增量 | 01:38:59 | 00:00:50 | 00:00:10 | 01:39:59 |
| 4月22日 | FIB增量 | 00:08:59 | 00:00:47 | 00:00:10 | 00:09:56 |
可见使用FIB技术之后,增量备份时间由1小时40分钟下降为10分钟左右。
小结
XX移动的这次事故虽然涉及硬件、软件、人为操作失误等多个方面,但在本章主要叙述的提高RMAN备份恢复性能方面,值得总结的技术要点如下:
- “全量+增量”结合的备份恢复方案是保证RMAN快速恢复的重要技术保障。
- 为确保增量备份的高效,快速增量备份技术(FIB)是重要的技术手段。
最后再感叹一下,Oracle有那么多好技术,FIB就是一个典型的好技术,可是我们DBA们怎么都不去深入研究并加以合理运用呢?
为什么我们一遇到性能问题,包括备份恢复性能问题,怎么总是想到带库应该扩容到多个Driver,存储应该更新换代到更高档设备这样简单粗暴的办法,而不是全面考虑技术方案本身的缺陷呢?
国内那么多重要的海量数据库系统都采用简单的“全量+每天备份归档日志”策略,如果哪天不幸像该移动客户一样出现一次严重故障,您尝试过RMAN恢复吗?需要多长时间,能满足系统高可用性要求吗?我们平时做过演练吗?在国内很多客户那里,数据库备份的确每天都在做,但却从未进行过恢复操作。备份数据几乎成了束之高阁的供物,呵呵。
人是生于忧患,死于安逸的。
4.9本章参考资料及进一步读物
本章的参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 11g R2联机文档 | 《Oracle® Database Performance Tuning Guide》 | 这是Oracle联机文档中,有关性能优化最权威的书籍,也是从事Oracle数据库设计、开发、运维各方面人士的必读物。 |
| 2. | Oracle大学教材 | 《Oracle9i: SQL Tuning Workshop》 | 该教材的第11章介绍了Bitmap、Bitmap-Join等高级索引技术。读者可去《Oracle® Database Data Warehousing Guide》等联机文档查询相关资料。 |
| 3. | My Oracle Support | 《Master Note: Database Performance Overview (Doc ID 402983.1)》 | 数据库性能问题涉及方方面面。从这篇文章入手,可以进入到性能优化的多个领域:性能优化方法、性能问题的诊断、SQL优化问题、数据库挂起… … |
| 4. | My Oracle Support | 《Master Note: SQL Query Performance Overview (Doc ID 199083.1)》 | 以SQL优化为重点的资料汇集:SQL性能差的常见原因、缺乏索引、不必要的排序、缺乏统计信息或不准确的统计信息…… |
| 5. | My Oracle Support | 《Best Practices: Proactively Avoiding Database and Query Performance Issues (Doc ID 1482811.1)》 | 性能优化的最有效措施是主动预防。该文章介绍了AWR、SQL Plan Management、采集统计信息、升级、打补丁、ADDM、实时SQL监控等多种主动性预防技术的运用。 |
| 6. | My Oracle Support | 《Information Center: Sql Performance Tuning: Troubleshoot (Doc ID 1516522.2)》 | 对性能影响最大的还是SQL语句。这篇文章是有关SQL性能优化的又一个资料集散地! |
| 7. | My Oracle Support | 《Document 1542678.2 Troubleshooting Assistant: SQL Performance Issues》 | 出了性能问题怎么办?请尝试一下访问这篇文章提供的诊断方法,帮助你定位问题,并参考Oracle提供的各种解决方案。 |

Comment