
If you cannot recover the data by yourself, ask Parnassusdata, the professional ORACLE database recovery team for help.
Parnassusdata Software Database Recovery Team
Service Hotline: +86 13764045638 E-mail: service@parnassusdata.com
ORACLE PRM-DUL Download: http://zcdn.parnassusdata.com/DUL5108.zip
Oracle DUL Data Unloader data recovery tool information summary

Oracle DUL is the internal database recovery tool of Oracle, developed by Dutch Oracle Support, Bernard van Duijnen:
- DUL is not a product of Oracle
- DUL is not supported by Oracle
- DUL is strictly limited to Oracle Support after-sales support department for internal use
- Using DUL abroad should go through Oracle’s internal approval, before using you need to purchase Oracle’s standard services PS first, otherwise it is not even eligible to use DUL
- One reason DUL is strictly controlled is its use of the Oracle source code
Start from DUL 9, Bernard van Duijnen set a software time lock for DUL to prevent the external use of DUL. He compiled DUL compiled on different platforms (DUL base on the C language) and uploaded to ORACLE internal DUL workspace (base on stbeehive space) periodically, and then Oracle Support downloaded it by using the internal VPN login. For example, Bernard.van.duijnen released a version on October 1. The date lock is 30 days. This version basically will become invalid by the time of November 1. And DUL does not read OS time, so changing OS time is useless. In fact, it reads a current time recorded by Oracle’s data file. And normal users won’t change the time to use DUL.

Note that Bernard van Duijnen does not provide DUL on HP-UX, so no DUL version can be applied to HP-UX.
Also note that earlier versions of DUL cannot be used in the current version 10g, 11g, 12c database, because it’s too old. Using DUL in the United States is restricted. In China, basically only the Oracle ACS customer service department provides external use, and the price of ORACLE ACS field services is fairly expensive.
The attached document introduces DUL service provided by Oracle ACS (of course the original field service is relatively expensive, and provided that the user has purchased the PS standards each year, otherwise you cannot even buy ACS Advanced Field Service):
DUL – DATA RECOVERY UNLOADER DataSheet
https://www.askmac.cn/wp-content/uploads/2014/01/DUL.pdf
DUL 10 English version of user manual:
DUL User’s and Configuration Guide V10.2.4.27
https://www.askmac.cn/wp-content/uploads/2014/01/DUL-Users-and-Configuration-Guide-V10.2.4.27.pdf
The following is the download link DUL 10, but because of the lock, it will fail regularly.
DUL FOR LINUX platform (updated to PRM-DUL)
DUL FOR Windows platform (updated to PRM-DUL)
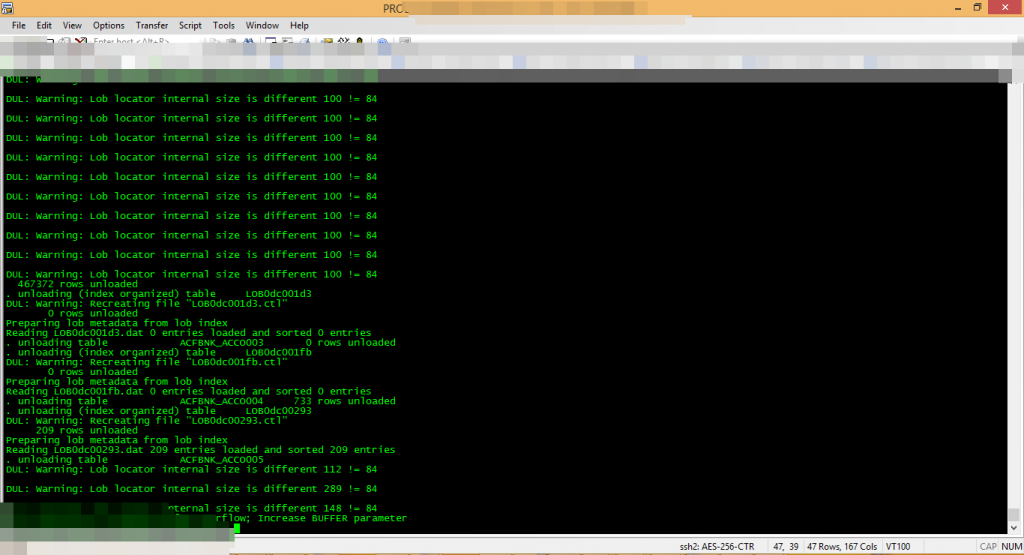
DUL can extracted data from a severely damaged database. DUL can directly scan Oracle Datafile, and identifies the header block segment header, have access to Extent information, and read data from the actual row. Then, it can generate import file in SQLLDR or DMP file in EXP.
If SYSTEM tablespace data files exist, DUL reads Oracle data dictionary. Otherwise DUL uses the form of actual read rows, and determines the field type and length depends on the internal algorithm.
DUL can basically process all of the common row types, including conventional row, migration row, chain row, multi Extents and clustered tables without additional manual intervention. Cross-platform extraction is also supported. DUL extract data directly from Oracle Datafile, without the need for Oracle database instance. It implements dirty reads , assuming that each transaction have already submitted. DUL does not detect whether to do media recovery, even damaged data block can also be read out. Support DMT and LMT table space. Because of its dirty reads, it is generally recommended to verify data by the application after DUL’s data recovery.
In terms of compatibility, DUL can process data filed copied from different operating systems. It supported most of the databases structure: chain row, migrate row, hash / index cluster, LONG, RAW, ROWID, DATE, Number, multi FreeList, high water level, NULL, and so on. DUL is compatible with ORACLE 6,7,8 and 9 and 10g 11g 12c.
Parnassusdata Software (where Maclean is) has developed similar products, PRM-DUL. The product is built on DUL and introduces graphical user interface GUI and DataBridge (data doesn’t need to be SQLLDR files, it can be directly transferred to the target database as DBLINK) and other functions on the basis of DUL; and because the PRM-DUL is written in JAVA, it can cover all platforms, including HP-UX.
PRM-DUL free version download:
http://parnassusdata.com/sites/default/files/ParnassusData_PRMForOracle_3206.zip
PRM-DUL’s manual
http://www.parnassusdata.com/sites/default/files/ParnassusData%20Recovery%20Manager%20For%20Oracle%20Database%E7%94%A8%E6%88%B7%E6%89% 8B% E5% 86% 8C% 20v0.3.pdf
The free version of PRM-DUL, by default, can only extracts a million rows of data from each table. If your database is no more than ten thousand rows of data table, you can directly use the free PRM-DUL. If your database is large and contains important data, then you can consider buying the Enterprise Edition of PRM-DUL, PRM-DUL Enterprise provides a license for a set of databases. Each License costs 7500 yuan (including 17 %VAT).
Meanwhile PRM-DUL also provide some free License:
Free open several PRM-DUL Enterprise Edition License Key
If your Oracle database recovery case still fails after using DUL, you may consider the service recovery:
Parnassusdata Software now offers almost all Oracle recovery cases, including database does not open, the table was mistakenly DROP, TRUNCATE, DELETE, etc. ASM Diskgroup cannot MOUNT etc.
PRM-DUL is developed based on JAVA, which ensures that PRM can run directly on any platform, whether it is on AIX, Solaris, HPUX and other Unix platforms, Redhat, Oracle Linux, SUSE and other Linux platforms, or Windows platforms.
Supported OS platform:
| Platform Name | Supported |
| AIX POWER | Yes |
| Solaris Sparc | Yes |
| Solaris X86 | Yes |
| Linux X86 | Yes |
| Linux X86-64 | Yes |
| HPUX | Yes |
| MacOS | Yes |
Currently supported database version:
| ORACLE DATABASE VERSION | Supported |
| Oracle 7 | Yes |
| Oracle 8 | Yes |
| Oracle 8i | Yes |
| Oracle 9i | Yes |
| Oracle 10g | Yes |
| Oracle 11g | Yes |
| Oracle 12c | Yes |
Currently supported languages:
| Languages | Character set | Corresponding code |
| Chinese Simplified / Traditional | ZHS16GBK | GBK |
| Chinese Simplified / Traditional | ZHS16DBCS | CP935 |
| Chinese Simplified / Traditional | ZHT16BIG5 | BIG5 |
| Chinese Simplified / Traditional | ZHT16DBCS | CP937 |
| Chinese Simplified / Traditional | ZHT16HKSCS | CP950 |
| Chinese Simplified / Traditional | ZHS16CGB231280 | GB2312 |
| Chinese Simplified / Traditional | ZHS32GB18030 | GB18030 |
| Japanese | JA16SJIS | SJIS |
| Japanese | JA16EUC | EUC_JP |
| Japanese | JA16DBCS | CP939 |
| Korean | KO16MSWIN949 | MS649 |
| Korean | KO16KSC5601 | EUC_KR |
| Korean | KO16DBCS | CP933 |
| French | WE8MSWIN1252 | CP1252 |
| French | WE8ISO8859P15 | ISO8859_15 |
| French | WE8PC850 | CP850 |
| French | WE8EBCDIC1148 | CP1148 |
| French | WE8ISO8859P1 | ISO8859_1 |
| French | WE8PC863 | CP863 |
| French | WE8EBCDIC1047 | CP1047 |
| French | WE8EBCDIC1147 | CP1147 |
| German | WE8MSWIN1252 | CP1252 |
| German | WE8ISO8859P15 | ISO8859_15 |
| German | WE8PC850 | CP850 |
| German | WE8EBCDIC1141 | CP1141 |
| German | WE8ISO8859P1 | ISO8859_1 |
| German | WE8EBCDIC1148 | CP1148 |
| Italian | WE8MSWIN1252 | CP1252 |
| Italian | WE8ISO8859P15 | ISO8859_15 |
| Italian | WE8PC850 | CP850 |
| Italian | WE8EBCDIC1144 | CP1144 |
| Thai | TH8TISASCII | CP874 |
| Thai | TH8TISEBCDIC | TIS620 |
| Arabic | AR8MSWIN1256 | CP1256 |
| Arabic | AR8ISO8859P6 | ISO8859_6 |
| Arabic | AR8ADOS720 | CP864 |
| Spanish | WE8MSWIN1252 | CP1252 |
| Spanish | WE8ISO8859P1 | ISO8859_1 |
| Spanish | WE8PC850 | CP850 |
| Spanish | WE8EBCDIC1047 | CP1047 |
| Portuguese | WE8MSWIN1252 | CP1252 |
| Portuguese | WE8ISO8859P1 | ISO8859_1 |
| Portuguese | WE8PC850 | CP850 |
| Portuguese | WE8EBCDIC1047 | CP1047 |
| Portuguese | WE8ISO8859P15 | ISO8859_15 |
| Portuguese | WE8PC860 | CP860 |
PRM-DUL supported table storage type:
| Table Storage Type | Supported |
| Cluster Tables | YES |
| Index Organized Tables, partition or non-partitioned | YES |
| Index Organized Tables, partition or non-partitioned | YES |
| Common Heap Tables enable basic compression | YES(Future) |
| Common Heap Tables enable advanced compression | NO |
| Common Heap Tables enable Hybrid Columnar Compression | NO |
| Common Heap Tables enable encryption | NO |
| Tables with virtual colum | NO |
| Tables with chained rows, migrated rows | YES |
Considerations:In terms of virtual column and 11g optimized default column, data extracting is ok, but you may lose the corresponding field. These two are new features of 11g and above, there’re fewer users.
PRM-DUL supported data type:
| Data Type | Supported |
| BFILE | No |
| Binary XML | No |
| BINARY_DOUBLE | Yes |
| BINARY_FLOAT | Yes |
| BLOB | Yes |
| CHAR | Yes |
| CLOB and NCLOB | Yes |
| Collections (including VARRAYS and nested tables) | No |
| Date | Yes |
| INTERVAL DAY TO SECOND | Yes |
| INTERVAL YEAR TO MONTH | Yes |
| LOBs stored as SecureFiles | Future |
| LONG | Yes |
| LONG RAW | Yes |
| Multimedia data types (including Spatial, Image, and Oracle Text) | No |
| NCHAR | Yes |
| Number | Yes |
| NVARCHAR2 | Yes |
| RAW | Yes |
| ROWID, UROWID | Yes |
| TIMESTAMP | Yes |
| TIMESTAMP WITH LOCAL TIMEZONE | Yes |
| TIMESTAMP WITH TIMEZONE | Yes |
| User-defined types | No |
| VARCHAR2 and VARCHAR | Yes |
| XMLType stored as CLOB | No |
| XMLType stored as Object Relational | No |
PRM-DUL supports for ASM:
| Features | Supported |
| Directly extract data from ASM, saving the process of copying to file system | YES |
| Copy data files from ASM | YES |
| Restore ASM metadata | YES |
| Graphically display ASM black box | Future |
ORACLE DUL tools manual:
DUL’s PRINCIPLES and FEATURE LIST
STANDALONE C-PROGRAM
DUL is a standalone C program that directly retrieves rows from tables in data files. The Oracle RDBMS software is NOT used at all. DUL does dirty reads, it assumes that every transaction is committed. Nor does it check/require that media recovery has been done.
LAST RESORT
DUL is intended to retrieve data that cannot be retrieved otherwise. It is NOT an alternative for EXP, SQL*Plus etc. It is meant to be a last resort, not for normal production usage.
Before you use DUL you must be aware that the rdbms has many hidden features to force a bad database open. Undocumented init.ora parameters and events can be used to skip roll forward, to disable rollback, disable certain SMON actions, advance the database scn and more.
DATABASE CORRUPT – BLOCKS OK
The database can be corrupted, but an individual data block used must be 100% correct. During all unloading checks are made to make sure that blocks are not corrupted and belong to the correct segment. If during a scan a bad block is encountered, an error message is printed in the loader file and to standard output. Unloading will continue with the next row or block.
ROWS in CLUSTERS/TABLES/INDEXES
DUL can and will only unload index/table/cluster data. It will NOT dump triggers, stored procedures nor create sql scripts for tables or views. (But the data dictionary tables describing them can be unloaded). The data will be unloaded in a format suitable for SQL*Loader or IMP. A matching control file for SQL*Loader is generated as well.
DUL can unload indices and index organized tables. Index unload is usefull to determine how many rows a table should have or to identify the missing rows.
CROSS PLATFORM UNLOADING
Cross-platform unloading is supported. The database can be copied from a different operating system than the DUL-host. (Databases/systems done so far: Sequent/ptx, Vax Vms, Alpha Vms, MVS, HP9000/8xx, IBM AIX, SCO Unix, Alpha OSF/1, Intel Windows NT).
The configuration parameters within “init.dul” will have to be modified to match those of the original platform and O/S rather than the platform from which the unload is being done.
ROBUST
DUL will not dump, spin or hang no matter how badly corrupted the database is.
(NEARLY) ALL ORACLE FEATURES SUPPORTED
Full support for all database constructs: row chaining, row migration, hash/index clusters, longs, raws, rowids, dates, numbers, multiple free list groups, segment high water mark, NULLS, trailing NULL columns, and unlimited extents, new block layout of Oracle8, partitioned tables.
Later additions are lobs, compressed indexes, 9ir2 compressed tables. Varrays and ADTs (user defined objects) are partly supported in sql*loader mode.
ASM is fully supported, files can be extracted from an asm disk group. No mounted ASM instance is used, the disks are accessed directly. Non default asm allocation unit sizes are supported.
Data can be recovered from export dump files with the unexp command suite. Some initial work has been done for unpump to support data pump files.
SUPPORTED RDBMS VERSIONS
DUL should work with all versions starting oracle 6. DUL has been tested with versions from 6.0.26 up to 10.2. Even the old block header layout (pre 6.0.27.2) is supported.
MULTI BYTE SUPPORT
DUL itself is essentially a single byte application. The command parser does not understand multi byte characters, but it is possible to unload any multi byte database. For all possible caveats there is a work around.
DUL can optionally convert to UTF8. This is for NCLOBS that are stored in UTF16.
RESTRICTIONS
MLSLABELS
Multi Level Security Lables of trusted oracle are not supported.
(LONG) RAW
DUL can unload (long) raws. Nowadays there is suitable format in SQL*Loader to preserve all long raws. So Long raws and blobs can be unloaded in both modes.
ORACLE8 OBJECT OPTION AND LOBS
Nested tables are not yet supported, if they are needed let me know and it will be added. Varrays and ADTs are supported, also those that are stored as a kernel lob. CLOBS, NCLOBS are supported both in SQL*Loader mode and in exp mode. BLOBS are best handled in exp mode, the generated hex format in SQL*Loader mode is not loaded correctly currently.
PORTABLE
DUL can be ported to any operating system with an ANSI-C compiler. DUL has been ported to many UNIX variants, VMS and WindowsNT. Currently all builds are done using gcc and a cross compiler environment on Linux
RDBMS INTERNALS
A good knowledge of the Oracle RDBMS internals is a pre requisite to be able to use DUL successfully. For instance the Data Server Internals (DSI) courses give a good foundation. There is even a module dedicated to DUL
SETTING UP and USING DUL
CONFIGURATION FILES
There are two configuration files for DUL. “init.dul” contains all configuration parameters. (size of caches, details of header layout, oracle block size, output file format) In the control file, “control.dul”, the database data file names and the asm disks can be specified.
DATA DICTIONARY AVAILABLE
The Oracle data dictionary is available if the data files which made up the SYSTEM TableSpace are available and useable. The number which Oracle assigned to these files and the name you have given them, which does not have to be the original name which Oracle knew, must be included in the “control.dul” file. You also need to eventually include the file numbers and names of any files from other TableSpaces for which you wish to eventually unload TABLES and their data. The lack of inclusion of these files will not affect the data dictionary unload step but it will affect later TABLE unloading.
USING DUL WHEN USER$, OBJ$, TAB$ and COL$ CAN BE UNLOADED
Steps to follow:
- configure DUL for the target database. This means creating a correct init.dul and control.dul. The SYSTEM TableSpace’s data file numbers and names must be included within the control.dul file along with any data files for TableSpaces from which you wish to unload TABLEs and their data. For Oracle8 and higher the tablespace number and the relative file number must be specified for each datafile.
- Use the ” BOOTSTRAP; ” command to prepare for unloading. The bootstrap process will find a compatibility segment, find the bootstrap$ table unload The old ” dul dictv7.ddl”re no longer needed.

- Unload the tables for which data files have been included within the “control.dul” file. Use one of the following commands:
- “UNLOAD TABLE [ owner>.]table ; (do not forget the semicolon)
- This will unload the one table definition and the table’s data.
- “UNLOAD USER user name ;
- This unloads all tables and data for the specified user.
- “UNLOAD DATABASE ;
- This unloads all of the database tables available. (except the user SYS).
- “UNLOAD TABLE [ owner>.]table ; (do not forget the semicolon)


unload user SCOTT;

NO DATA DICTIONARY AVAILABLE
If data files are not available for the SYSTEM TableSpace the unload can still continue but USER, TABLE and COLUM names will not be known. Identifying the tables can be an overwhelming task. But it can be (and has been) done. You need in depth knowledge about your application and the application tables. Column types can be guessed by DUL, but table and column names are lost. Any old SYSTEM tablespace from the same database but weeks old can be of great help!. Most of the information that DUL uses does not change. (only the dataobj# is during truncate or index rebuild)
USING DUL WITHOUT SYSTEM TABLESPACE
Steps to follow:
- configure DUL for the target database. This means creating a correct init.dul and control.dul. (See Port specific parameters ). In this case control.dul file will need the numbers and names of datafiles from which TABLEs and data will be unloaded but it does not require the SYSTEM TableSpace’s information.
- SCAN DATABASE; : scan the database, build extent and segment map
- SCAN TABLES; or SCAN EXTENTS; : gather row statistics
- Identify the lost tables from the output of step 3.
- UNLOAD the identified tables.
AUTOMATED SEARCH
To ease the hunt for the lost tables: the scanned statistical information in seen_tab.dat and seen_col.dat can be loaded into a fresh database. If you recreate the tables ( Hopefully the create table scripts are still available) then structure information of a “lost” table can be matched to the “seen” tables scanned information with two SQL*Plus scripts. (fill.sql and getlost.sql).
HINTS AND PITFALLS
- Names are not really relevant for DUL, only for the person who must load the data. But the unloaded data does not have any value, if you do not know from which table it came.
- The guessed column types can be wrong. Even though the algorithm is conservative and decides UNKNOWN if not sure.
- Trailing NULL columns are not stored in the database. So if the last columns only contain NULL’s than the scanner will NOT find them. (During unload trailing NULL columns are handled correctly).
- When a table is dropped, the description is removed from the data dictionary only. The data blocks are not overwritten unless they are reused for a new segment. So the scanner software can see a table that has been dropped.
- Tables without rows will go unnoticed.
- Newer objects have a higher object id than older objects. If an table is recreated, or if there is a test and a production version of the same table the object id can be used to decide.
DDL (DUL Description Language) UNLOAD STATEMENT OVERVIEW
DUL uses an SQL like command interface. There are DDL statements to unload extents, tables, users or the entire database. Data dictionary information required can be specified in the ddl statements or taken from the previously unloaded data dictionary. The following three statements will unload the DEPT table. The most common form is if the data dictionary and the extent map are available:
UNLOAD TABLE scott.dept;
All relevant information can be specified in the statement as well:
REM Columns with type in the correct order
REM The segment header loaction in the storage clause
UNLOAD TABLE dept( deptno NUMBER, dname CHAR, loc CHAR)
STORAGE( EXTENTS ( FILE 1 BLOCK 1205 ));
Oracle version 6:
REM version 6 data blocks have segment header location in each block
ALTER SESSION SET USE_SCANNED_EXTENT_MAP = TRUE;
UNLOAD TABLE dept( deptno NUMBER, dname CHAR, loc CHAR)
STORAGE( EXTENTS ( FILE 1 BLOCK 1205 ));
Oracle7:
REM Oracle7 data blocks have object id in each block
ALTER SESSION SET USE_SCANNED_EXTENT_MAP = TRUE;
UNLOAD TABLE dept( deptno NUMBER, dname CHAR, loc CHAR)
STORAGE( OBJNO 1501 );
DUL’S OUTPUT FORMAT.
Only complete good rows are written to the output file. For this each row is buffered. The size of the buffer can changed with the init.dul parameter BUFFER. There is no speed gained with a high BUFFER parameter, it should just be big enough to hold a complete row. Incomplete or bad rows are not written out. The FILE_SIZE_IN_MB init.dul parameter can be used to split the output (at a proper boundary) into multiple files, each file can be loaded individually.
There are three different modes of output format.
- Export mode
- SQL*Loader mode: stream data files
- SQL*Loader mode: Fixed physical record data files
EXPORT MODE
The generated file is completely different from a table mode export generated by EXP! The file is the minimal format that IMP can load. For each table a separate IMP loadable file will be generated. It is a single table dump file. It contains a header an insert table statement and the table data. Table grants, storage clauses, or triggers will not be included. An minimal create table statement is included (no storage clause just column names and types without precision). The character set indication in the file in the generated header is V6 style. It is set to mean ASCII based characterset.
To enable export mode, set the init.dul parameter EXPORT_MODE to TRUE.
As the generated pseudo dump file does not contain character set information set NLS_LANG to match that of the original database. In export mode no character set conversion is done.
SQL*LOADER MODES
The data in the is either not converted at all, or everthing is converted to UTF8 if LDR_OUTPUT_IN_UTF8 is set. This setting is required in mixed character set environments as the contents of a data file must have a single character set.<\P>
When loading the data you probably need to set NLS_LANG to match that of the original database to prevent unwanted character set conversion.
For both SQL*Loader output formats the columns will be space separated and enclosed in double quotes. Any double quote in the data will be doubled. SQL*Loader recognizes this and will load only one. The character used to enclose the columns can be changed from double quote to any character you like with the init.dul parameter LDR_ENCLOSE_CHAR.
There are two styles of physical record organization:
Stream Mode
Nothing special is done in stream mode, a newline is printed after each record. This is a compact format and can be used if the data does not contain newline characters. To enable stream mode set LDR_PHYS_REC_SIZE = 0 in init.dul.
Fixed Physical Records
This mode is essential if the data can contain newlines. One logical record, one comlete row, can be composed of multiple physical records. The default is record length is 81, this fits nicely on the screen of a VT220. The physical record size can be specified with LDR_PHYS_REC_SIZE in init.dul.
OUTPUT FILE NAMES
The file names generated are: owner name_table name.ext. The extension is “.dmp” for IMP loadable files. “.dat” and “.ctl” are used for the SQL*Loader datafile and the control file. To prevent variable substitution and other unwanted side effects, strange characters are stripped.(Only alpha numeric and ‘_’ are allowed).
If the FILE parameter is set the generated names will be FILEnnn.ext. This possibility is a work around if the file system does not support long enough file names. (Old windows with 6.3 filename format)
SOME DUL INTERNALS
REQUIRED INFORMATION
To unload table data from a database block the following information must be known:
- Column/Cluster Information: The number and type of the columns. For char or varchar columns the maximum length as well. The number of cluster columns and the table number in the cluster. This information can be supplied in the unload statement or it can be taken from the previously unloaded USER$, OBJ$, TAB$ and COL$.
- Segment/Extent information: When unloading a table the extent table in the data segment header block is used to locate all data blocks. The location of this segment header block (file number and block number) is taken from the data dictionary or can be specified in the unload statement. If the segment header is not correct/available then another method must be used. DUL can build its own extent map by scanning the whole database. (in a separate run of DUL with the scan database statement.)
BINARY HEADERS
C-Structs in block headers are not copied directly, they are retrieved with specialized functions. All offsets of structure members are programmed into DUL. This approach makes it possible to cross-unload. (Unload an MVS created data file on an HP) Apart from byte order only four layout types have been found so far.
- Vax VMS and Netware : No alignment padding between structure members.
- Korean Ticom Unix machines : 16 bit alignment of structure members.
- MS/DOS 16 bit alignment and 16 bit wordsize.
- Rest of the world (Including Alpha VMS) structure member alignment on member size.
MACHINE DEPENDENCIES
Machine dependencies (of the database) are configurable with parameters:
- Order of bytes in a word (big/little endian).
- Number of bits for the low part of the FILE# in a DBA (Block Address).
- Alignment of members in a C-struct.
- Number of blocks or bytes before the oracle file header block.
- Size of a word used in the segment header structure.
UNLOADING THE DATA DICTIONARY
DUL can use the data dictionary of the database to be unloaded if the files for it exist and are uncorrupted. For the data dictionary to be used, internal tables must be unloaded first to external files: (USER$, OBJ$, TAB$ and COL$). The bootstrap command will find and unload the required tables.
DDL ( DUL DESCRIPTION LANGUAGE ) SPECIFICATION
[ ALTER SESSION ] SET init.dul parameter = value ;
Most parameters can be changed on the fly.
BOOTSTRAP [LOCATE | GENERATE | COMPLETE
| UNLOAD Bootstrap$ segment header block address ];
Bootstraps the data dictionary. Default is COMPLETE.
LOCATE finds and unloads the bootstrap$ table.
GENERATE builds a ddl file based on inforation in the cache.
COMPLETE is in fact LOCATE, followed by GENERATE (two times)
COMMIT;
Writes the changed block to the data file.
CREATE BLOCK INDEX index_name ON device ;
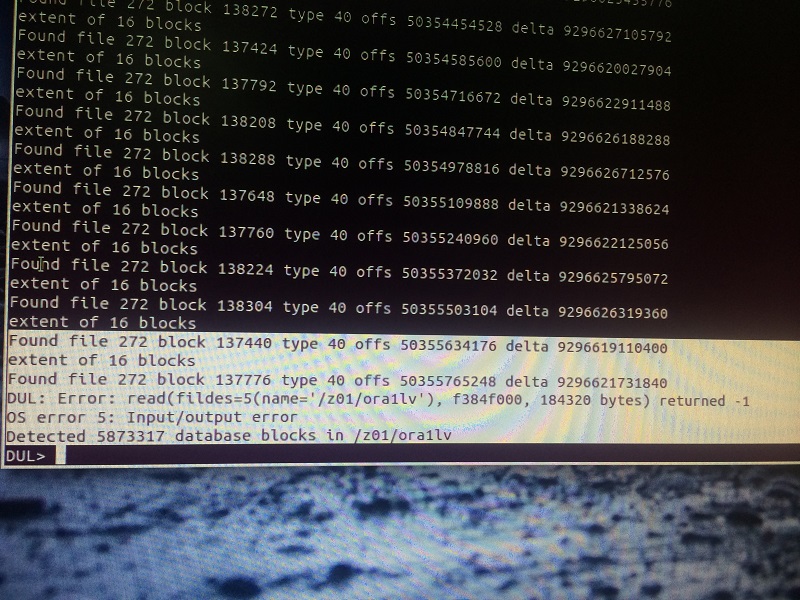
A block index contains address of valid oracle blocks found in a corrupt file system. Useful to merge multiple disk images or to unload from corrupted file systems. This is only useful in extreme file system corruption scenarios.
DESCRIBE owner_name . table_name ;
DUMP [ TABLESPACE tablespace_no ]
[ FILE file_no ]
[ BLOCK block_no ]
[ LEVEL level_no ] ;
Not a complete blockdump, mainly used for debugging.
The block address is remembered.
EXTRACT asm file name to output file name ;
Copies any ASM file from a disk group to the file system.
(there was a problem with online redologs this needs more testing)
MERGE block_index INTO [ segment ];

The merge command uses the information in the index file to locate possible data blocks it looks for a combination of file numbers and object id, each candidate block is compared to the current block in the datafile. If the current block is bad, or has an older scn the candidate will will be written into the datafile. This is only useful in extreme file system corruption scenarios.
REM any_text_you_like_till_End_Of_Line : comment
REM NOT allowed inside ddl statements. ( To avoid a two layer lexical scan).
ROLLBACK; # Cancels the UPDATE statements.
SHOW DBA dba ; # dba -> file_no block_no calculator
| DBA rfile_no block_no ; # file_no block_no -> dba calculator
| SIZES ; # show some size of important structs
| PARAMETER; # shows the values of all parameters
| LOBINFO; # lob indexes found with SCAN DATABASE
| DATAFILES; # summary of configured datafiles
| ASM DISKS; # summary of configured asm disks
| ASM FILES; # summary of configured datafiles on asm
| ASM FILE cid # extent information for asm file
UNEXP [TABLE] [ owner . ] table name
( column list ) [ DIRECT ]
DUMP FILE dump file name
FROM begin offset [ UNTIL end offset ]
[ MINIMUM minimal number of columns COLUMNS ] ;
To unload data from a corrupted exp dump file. No special setup
or configuration is required, just the compatible parameter.
The start offset should be where a row actually begins.
UNPUMP
To unload data from a corrupted expdp (datapump) dump file.
This is still work in progress, the basic commands work
but rather complex to use. Contact me if this is needed.
UNLOAD DATABASE;
UNLOAD USER user_name;
UNLOAD [TABLE] [ schema_name . ] table_name
[ PARTITION( partition_name ) ]
[ SUBPARTITION( sub_partition_name ) ]
[ ( column_definitions ) ]
[ cluster_clause ]
[ storage_clause ] ;
UNLOAD EXTENT table_name
[ ( column_definitions ) ]
[ TABLESPACE tablespace_no ]
FILE extent_start_file_number
BLOCK extent_start_block_number
BLOCKS extent_size_in oracle_blocks ;
UNLOAD LOB SEGMENT FOR [ schema_name . ] table_name [ ( column name ) ] ;
UNLOAD LOB SEGMENT STORAGE ( SEGOBJNO data obj#) ;
UPDATE [ block_address ] SET UB1|UB2|UB4 @ offset_in_block = new_value ;
UPDATE [ block_address ] SET block element name = new_value ;
Now and then we can repair something.
Patches the current block and dumps it.
You can issue multiple UPDATE commands.
Block is not written yet, use COMMIT to write.
storage_clause ::=
STORAGE ( storage_specification [ more_storage_specs ] )
storage_specification ::=
OBJNO object_id_number
| TABNO cluster_table_number
| SEGOBJNO cluster/data_object_number /* v7/v8 style data block id */
| FILE data_segment_header_file_number /* v6 style data block id */
BLOCK data_segment_header_block_number )
| any_normal_storage_specification_but_silently_ignored
SCAN DATABASE;
Scans all blocks of all data files. Two or three files are generated:
- SEG.dat information of found segment headers (index/cluster/table): (object id, file number, and block number).
- EXT.dat information of contiguous table/cluster data blocks. (object id(V7), file and block number of segment header (V6), file number and block number of first block, number of blocks, number of tables)
- SCANNEDLOBPAGE.dat information for each lob datablock, this file (optional, only if init.dul:SCAN_DATABASE_SCANS_LOB_SEGMENTS=TRUE) can possibly be huge. Also the required memory size can be problematic. The purpose is twofold: 1: to possibly work around corrupt lob indexes during unload table. 2: unload lob segments (for deleted lobs or lob segments without lob index or parent table) Meaning of the fields in SCANNEDLOBPAGE.dat: (segobj#, lobid, fat_page_no, version( wrap, base), ts#, file#, block#)

SCAN DUMP FILE dump file name
[ FROM begin offset ]
[ UNTIL end offset ];
Scans an export dump file to produce to provide the
create/insert statements and the offsets in the dump file.
SCAN LOB SEGMENT storage clause ;
SCAN LOB SEGMENT FOR table name [. column name] ;
Scans the lob segment to produce LOBPAGE.dat information,
but then for this segment only. Probably quicker and
smaller. For partitioned objects use scan database.
SCAN TABLES;
Uses SEG.dat and EXT.dat as input.
Scans all tables in all data segments (a header block and at least one
matching extent with at least 1 table).
SCAN EXTENTS;
Uses SEG.dat and EXT.dat as input.
All extents for which no corresponding segment header has been found.
(Only useful if a tablespace is not complete, or a segment header
is corrupt).
EXIT QUIT and EOF all cause DUL to terminate.
DDL ( DUL DESCRIPTION LANGUAGE ) DESCRIPTION
Rules for UNLOAD EXTENT and UNLOAD TABLE:
Extent Map
UNLOAD TABLE requires an extent map. In 99.99% of the cases the extent map in the segment header is available. In the rare 0.01% that the segment header is lost an extent map can be build with the scan database command. The self build extent map will ONLY be used during an unload if the parameter USE_SCANNED_EXTENT_MAP is set to TRUE.
All data blocks have some ID of the segment they belong to. But there is a fundamental difference between V6 and V7. Data blocks created by Oracle version 6 have the address of the segment header block. Data blocks created by Oracle7 have the segment object id in the header.
Column Specification
The column definitions must be specified in the order the columns are stored in the segment, that is ordered by col$.segcol#. This is not necessarily the same order as the columns where specified in the create table statement. Cluster columns are moved to the front, longs to the end. Columns added to the table with alter table command, are always stored last.
Unloading a single extent
UNLOAD EXTENT can be used to unload 1 or more adjacent blocks. The extent to be unloaded must be specified with the STORAGE clause: To specify a single extent use: STORAGE ( EXTENTS( FILE fno BLOCK bno BLOCKS #blocks) ) (FILE and BLOCK specify the first block, BLOCKS the size of the extent)
DUL specific column types
There are two extra DUL specific data types:
- IGNORE: the column will be skipped as if it was not there at all.
- UNKNOWN: a heuristic guess will be made for each column.
In SQL*Loader mode there are even more DUL specific data types:
- HEXRAW: column is HEX dumped.
- LOBINFO: show some information from LOB locators .
- BINARY NUMBER: Machine word as used in a LOB index.
Identifying USER$, OBJ$, TAB$ and COL$
DUL uses the same bootstrap procedure as the rdbms. That is it uses the root dba from the system datafile header to locate the bootstrap$ table. Depending on the version this root dba is either the location of the compatibility segment containing the bootstrap$ address or for the newer versions the address of the bootstrap$ table itself. The bootstrap$ table is unloaded and its contents is parsed to find the first four tables (USER$, OBJ$, TAB$ and COL$). The other tables are unloaded based on information in these first four.
DESCRIPTION OF SCAN COMMANDS
SCAN TABLES and SCAN EXTENTS scan for the same information and produce similar output. ALL columns of ALL rows are inspected. For each column the following statistics are gathered:
- How often the column is seen in a data block.
- The maximum internal column length.
- How often the column IS NULL.
- How often the column consists of at least 75% printable ascii.
- How often the column consists of 100% printable ascii.
- How often the column is a valid oracle number.
- How often the column is a nice number. (not many leading or trailing zero’s)
- How often the column is a valid date.
- How often the column is a possible valid rowid.
These statistics are combined and a column type is suggested. Using this suggestion five rows are unloaded to show the result. These statistics are dumped to two files (seen_tab.dat and seen_col.dat). There are SQL*Loader and SQL*Plus scripts available to automate a part of the identification process. (Currently known as the getlost option).
DESCRIBE
There is a describe command. It will show the dictionary information for the table, available in DUL’s dictionary cache.
DUL STARTUP SEQUENCE
During startup DUL goes through the following steps:
- the parameter file “init.dul” is processed.
- the DUL control file (default “control.dul”) is scanned.
- Try to load dumps of the USER$, OBJ$, TAB$ and COL$ if available into DUL’s data dictionary cache.
- Try to load seg.dat and col.dat.
- Accept DDL-statements or run the DDL script specified as first arg.
DUL parameters to be specified in init.dul:
- ALLOW_TRAILER_MISMATCH
- BOOLEAN
- Strongly discouraged to use, will seldom produce more rows. Use only if you fully understand what it means and why you want it. skips the check for correct block trailer. The blocks failing this test are split of corrupt. But it saves you the trouble to patch some blocks.
- ALLOW_DBA_MISMATCH
- BOOLEAN
- Strongly discouraged to use, will seldom produce more rows. Use only if you fully understand what it means and why you want it. Skips the check for correct block address. The blocks failing this test are probably corrupt. But it saves you the trouble to patch some blocks.
- ALLOW_OTHER_OBJNO
- BOOLEAN
- If your dictionary is older than your datafiles then the data object id’s can differ for truncated tables. With this parameter set to true it will issue a warning but use the value from segment header. All other blocks are fully checked. This is for special cases only.
- ASCII2EBCDIC
- BOOLEAN
- Must (var)char fields be translated from EBCDIC to ASCII. (For unloading MVS database on a ASCII host)
- BUFFER
- NUMBER (bytes)
- row output buffer size used in both export and SQL*Loader mode. In each row is first stored in this buffer. Only complete rows without errors are written to the output file.
- COMPATIBLE
- NUMBER
- Database version , valid values are 6, 7, 8 or 9. This parameter must be specified
- CONTROL_FILE
- TEXT
- Name of the DUL control file (default: “control.dul”).
- DB_BLOCK_SIZE
- NUMBER
- Oracle block size in bytes (Maximum 32 K)
- DC_COLUMNS
- NUMBER
- DC_OBJECTS
- NUMBER
- DC_TABLES
- NUMBER
- DC_USERS
- NUMBER
- Sizes of dul dictionary caches. If one of these is too low the cache will be automatically resized.
- EXPORT_MODE
- BOOLEAN
- EXPort like output mode or SQL*Loader format
- FILE
- TEXT
- Base for (dump or data) file name generation. Use this on 8.3 DOS like file systems
- FILE_SIZE_IN_MB
- NUMBER (Megabytes)
- Maximum dump file size. Dump files are split into multiple parts. Each file has a complete header and can be loaded individually.
- LDR_ENCLOSE_CHAR
- TEXT
- The character to enclose fields in SQL*Loader mode.
- LDR_PHYS_REC_SIZE
- NUMBER
- Physical record size for the generated loader datafile.
- LDR_PHYS_REC_SIZE = 0 No fixed records, each record is terminated with a newline.
- LDR_PHYS_REC_SIZE > 2: Fixed record size.
- MAX_OPEN_FILES
- Maximum # of database files that are concurrently kept open at the OS level.
- OSD_BIG_ENDIAN_FLAG
- Byte order in machine word. Big Endian is also known as MSB first. DUL sets the default according to the machine it is running on. For an explanation why this is called Big Endian, you should read Gullivers Travels.
- OSD_DBA_FILE_BITS
- File Number Size in DBA in bits. Or to be more precise the size of the low order part of the file number.
- OSD_FILE_LEADER_SIZE
- bytes/blocks added before the real oracle file header block
- OSD_C_STRUCT_ALIGNMENT
- C Structure member alignment (0,16 or 32). The default of 32 is correct for most ports.
- OSD_WORD_SIZE
- Size of a machine word always 32, except for MS/DOS(16)
- PARSE_HEX_ESCAPES
- Boolean default FALSE
- Use \\xhh hex escape sequences in strings while parsing. If set to true then strange characters can be specified using escape sequences. This feature is also for specifying multi-byte characters.
- USE_SCANNED_EXTENT_MAP
- BOOLEAN
- Use the scanned extent map in ext.dat when unloading a table. The normal algorithme uses the extent map in the segment header. This parameter is only useful if some segment headers are missing or incorrect.
- WARN_RECREATE_FILES
- BOOLEAN (TRUE)
- Set to FALSE to suppress the warning message if an existing file is overwritten.
- WRITABLE_DATAFILES
- BOOLEAN (FALSE)
- Normal use of DUL will only read the database files. However the UPDATE and the SCAN RAW DEVICE will write as well. The parameter is there to prevent accidental damage.
SAMPLE init.dul :
# sample init.dul configuration parameters # these must be big enough for the database in question # the cache must hold all entries from the dollar tables. dc_columns = 200000 dc_tables = 10000 dc_objects = 10000 dc_users = 40 # OS specific parameters osd_big_endian_flag = false osd_dba_file_bits = 10 osd_c_struct_alignment = 32 osd_file_leader_size = 1 # database parameters db_block_size = 8k # loader format definitions LDR_ENCLOSE_CHAR = " LDR_PHYS_REC_SIZE = 81
Configuring the port dependent parameters
Starting from rdbms version 10G osd parameters are easy to configure. Typically all parameters can be used at their defaults. The only one that might need attention is osd_big_endian_flag, when doing a cross platform unload, where the original database platform is different from the current machine. If osd_big_endian_flag is set incorrectly, it is detected at startup, when doing file header inspection.
Collection of known Parameters
For pre 10G databases there is a list of known parameters in the osd wiki page list of osd (Operating System Dependend) parameters for almost every platform. If your platform is not in the list you can use the suggestions below to determine the parameters. (And then please inform me so I can add them to the list.)
osd_big_endian_flag
big endian or little endian (byte order in machine words): HP, SUN and mainframes are generally big endian: OSD_BIG_ENDIAN_FLAG = TRUE. DEC and Intel platforms are little endian: OSD_BIG_ENDIAN_FLAG = FALSE. The default is correct for the platform where DUL is running on.
There is no standard trick for this, the following might work on a unix system:
echo dul | od -x
If the output is like:
0000000 6475 6c0a
0000004
You are on a big endian machine (OSD_BIG_ENDIAN_FLAG=TRUE).
If you see:
0000000 7564 0a6c
0000004
This is a little endian machine (OSD_BIG_ENDIAN_FLAG=FALSE).
osd_dba_file_bits
The number of bits in a dba used for the low order part of file number. Perform the following query:
SQL> select dump(chartorowid('0.0.1')) from dual;
Typ=69 Len=6: 8,0,0,0,0,0 -> osd_dba_file_bits = 5 (SCO)
Typ=69 Len=6: 4,0,0,0,0,0 -> osd_dba_file_bits = 6 (Sequent , HP)
Typ=69 Len=6: 1,0,0,0,0,0 -> osd_dba_file_bits = 8 (NCR,AIX)
Typ=69 Len=6: 0,16,0,0,0,0 -> osd_dba_file_bits = 12 (MVS)
Typ=69 Len=10: 0,0,0,0,0,64,0,0,0,0 osd_dba_file_bits = 10 (Oracle8)
OSD_C_STRUCT_ALIGNMENT
Structure layout in data file headers. 0: No padding between members in a C-struct (VAX/VMS only) 16: Some korean ticom machines and MS/DOS 32: Structure members are member size aligned. (All others including ALPHA/VMS) Check the following query:
SELECT * FROM v$type_size
WHERE type IN ( 'KCBH', 'KTNO', 'KCBH', 'KTBBH', 'KTBIT', 'KDBH'
, 'KTECT', 'KTETB', 'KTSHC') ;
In general osd_c_struct_alignment = 32 and the following output is expected:
K KTNO TABLE NUMBER IN CLUSTER 1 KCB KCBH BLOCK COMMON HEADER 20 KTB KTBIT TRANSACTION VARIABLE HEADER 24 KTB KTBBH TRANSACTION FIXED HEADER 48 KDB KDBH DATA HEADER 14 KTE KTECT EXTENT CONTROL 44 KTE KTETB EXTENT TABLE 8 KTS KTSHC SEGMENT HEADER 8 8 rows selected.
For VAX/VMS and Netware ONLY osd_c_struct_alignment = 0 and this output is expected:
COMPONEN TYPE DESCRIPTION SIZE -------- -------- -------------------------------- ---------- K KTNO TABLE NUMBER IN CLUSTER 1 KCB KCBH BLOCK COMMON HEADER 20 KTB KTBIT TRANSACTION VARIABLE HEADER 23 KTB KTBBH TRANSACTION FIXED HEADER 42 KDB KDBH DATA HEADER 14 KTE KTECT EXTENT CONTROL 39 KTE KTETB EXTENT TABLE 8 KTS KTSHC SEGMENT HEADER 7 8 rows selected.
If there is a different list this will require some major hacking and sniffing and possibly a major change to DUL. (Email Bernard.van.Duijnen@oracle.com)
osd_file_leader_size
Number of blocks/bytes before the oracle file header. Unix datafiles have an extra leading block ( file size, block size magic number) A large number ( > 100) is seen as a byte offset, a small number is seen as a number of oracle blocks.
Unix : osd_file_leader_size = 1
Vms : osd_file_leader_size = 0
Desktop : osd_file_leader_size = 1 (or 512 for old personal oracle)
Others : Unknown ( Use Andre Bakker's famous PATCH utility to find out)
An Oracle7 file header block starts with the pattern 0X0B010000.
You can add an additional byte offset in control.dul in the optional third field (for instance for AIX or DEC UNIX data files on raw device)
Control file syntax specification
A control file (default name “control.dul”) is used to specify asm disks, block indexes and the data file names. The format of the control has been extended
Currently there are three types of specifications in the DUL control file. Each entry on a separate line. The asm disks must precede the asm files.
control_file_line ::= asm_disk_spec | file_piece_spec | block_index_spec
If COMPATIBLE is 10 or higher you can also specify asm disks. Its generally sufficent to specify the device name. All properties are automatically retrieved by header inspection. The full syntax is only needed when header inspection is impossible, that is for disks with corrupt headers. The syntax is:
DISK device name [ disk group options ]
disk group option ::= GROUP disk group name
| DISK_NO disk number in group
| F1B1 File1 Block1 location
A block index is a way to access oracle blocks on corrupt file systems. In general a corrupt file system is not wiped out, its not empty. Due to the specific layout of oracle blocks it is possible to datablocks an store their location in the block index. See also the create block index command . A block_index_name is a normal identifier, it is used to construct an unique file name.
BLOCK INDEX block_index_name
Each entry can contain a part of a datafile. The smallest unit is a single data block. This way it is possible to split datafiles that are too big for DUL in parts where each part is smaller than 2GB.
In general it is sufficient to specify the file name. Even for a single block. If compatible is 10 or higher the file numbers and the tablespace numbers will be read from the file header.
If the specified details are different from the file header DUL will give a warning but use your specification. This is to be able to unload files with a corrupted header block. For debugging it is possible to dump the file header.
The optional extra leader offset is an extra byte offset, that will be added to all lseek() operations for that datafile. This makes it possible to skip over the extra 4k block for some AIX raw devices, or the extra 64K on Tru64 on raw devices
file_piece_spec ::=
[ [ tablespace_no ] relative_file_number]data_file_name
[ optional extra leader offset ]
[ startblock block_no ]
[ endblock block_no ]
Examples
# AIX version 7 example with one file on raw device 1 /usr/oracle/dbs/system.dbf 8 /dev/rdsk/data.dbf 4096
# Oracle8 example with a datafile split in multiple parts, each part smaller than 2GB 0 1 /fs1/oradata/PMS/system.dbf 1 2 /tmp/huge_file_part1 startblock 1 endblock 1000000 1 2 /tmp/huge_file_part2 startblock 1000001 endblock 2000000 1 2 /mnt3/huge_file_part3 startblock 2000001 endblock 2550000
# ASM disks for two disk groups disk /media/maxtor/asm/dgn1 disk /media/maxtor/asm/dgn2 disk /media/maxtor/asm/dgn3 disk /media/maxtor/asm/dgn4 disk /media/maxtor/asm/dgodd # system datafile in the first asm disk group +DGN/db102/datafile/system.257.621616979 # users datafile in a different disk group +DGODD/db102/datafile/users.257.621616683 # a so called big file tablespace, use 1024 for the file# 8 1024 /home/oracle/v102/dbs/bigfilets # Or let DUL find out itself from the header /home/oracle/v102/dbs/bigfilets # one tablespace with a different block size /home/oracle/v102/dbs/ts16k.dbf block_size 16k # or let DUL find out by header inspection /home/oracle/v102/dbs/ts16k.dbf
Sample unload session: data dictionary usable for DUL
- create a suitable “init.dul”
- create a control.dul
sqlplus /nolog
connect / as sysdba
startup mount
set trimspool on pagesize 0 linesize 256 feedback off
column name format a200
spool control.dul
select ts#, rfile#, name from v$datafile;
exit
edit the result
For Oracle8 a different query must be used: select ts#, rfile#, name from v$datafile;
- start DUL and bootstrap;
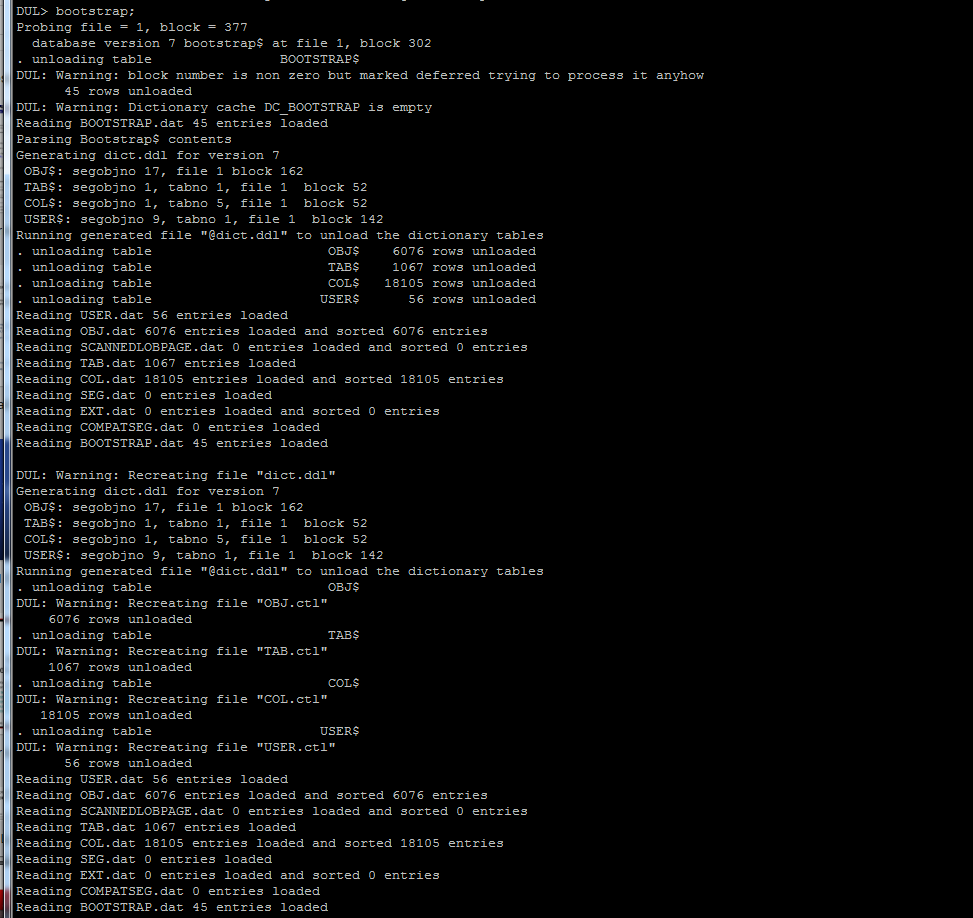
$ dul Data UnLoader 10.2.1.16 - Oracle Internal Only - on Thu Jun 28 11:37:24 2007 with 64-bit io functions Copyright (c) 1994 2007 Bernard van Duijnen All rights reserved. Strictly Oracle Internal use Only DUL> bootstrap; Probing file = 1, block = 377 . unloading table BOOTSTRAP$ 57 rows unloaded DUL: Warning: Dictionary cache DC_BOOTSTRAP is empty Reading BOOTSTRAP.dat 57 entries loaded Parsing Bootstrap$ contents DUL: Warning: Recreating file "dict.ddl" Generating dict.ddl for version 10 OBJ$: segobjno 18, file 1 TAB$: segobjno 2, tabno 1, file 1 COL$: segobjno 2, tabno 5, file 1 USER$: segobjno 10, tabno 1, file 1 Running generated file "@dict.ddl" to unload the dictionary tables . unloading table OBJ$ 52275 rows unloaded . unloading table TAB$ 1943 rows unloaded . unloading table COL$ 59310 rows unloaded . unloading table USER$ 70 rows unloaded Reading USER.dat 70 entries loaded Reading OBJ.dat 52275 entries loaded and sorted 52275 entries Reading TAB.dat 1943 entries loaded Reading COL.dat 59310 entries loaded and sorted 59310 entries Reading BOOTSTRAP.dat 57 entries loaded ... Some more messages for all the other TABLES ... Database character set is WE8ISO8859P1 Database national character set is AL16UTF16 DUL> unload user SCOTT; About to unload SCOTT's tables ... . unloading table EMP 14 rows unloaded
Example unload session: data dictionary UNUSABLE for DUL
- create a suitable “init.dul” (See config guide)
- create a control.dul See above
- scan the database for segment headers and extents:
$ dul UnLoader: Version 2.0.0.0 - Very Restricted on Tue May 16 11:10:16 1995 Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved. DUL> scan database; data file 1 20480 blocks scanned data file 4 7680 blocks scanned data file 5 512 blocks scanned DUL>quit
- Restart DUL and scan the found tables for column statistics this creates a huge amount of output:
echo scan tables \; | dul > scan.out&
[ many lines here]
Object id 1601 table number 0
UNLOAD TABLE T1601_0 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN, C4 NUMBER, C5 DATE
, C6 NUMBER, C7 NUMBER, C8 NUMBER )
STORAGE ( TABNO 0 EXTENTS( FILE 1 BLOCK 10530));
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 14 3 0% 0% 0% 100% 100% 0% 0%
2 14 6 0% 100% 100% 100% 14% 0% 21%
3 14 9 0% 100% 100% 100% 14% 0% 0%
4 14 3 7% 0% 0% 100% 100% 0% 0%
5 14 7 0% 0% 0% 0% 0% 100% 0%
6 14 3 0% 0% 0% 100% 100% 0% 0%
7 14 2 71% 0% 0% 100% 100% 0% 0%
8 14 2 0% 0% 0% 100% 100% 0% 0%
"7369" "SMITH" "CLERK" "7902" "17-DEC-1980 AD 00:00:00" "800" "" "20"
"7499" "-0.000025253223" "SALESMAN" "7698" "20-FEB-1981 AD 00:00:00" "1600" "30+
0" "30"
"7521" "WARD" "SALESMAN" "7698" "22-FEB-1981 AD 00:00:00" "1250" "500" "30"
"7566" "JONES" "MANAGER" "7839" "02-APR-1981 AD 00:00:00" "2975" "" "20"
"7654" "MARTIN" "SALESMAN" "7698" "28-SEP-1981 AD 00:00:00" "1250" "1400" "30"
[ many more lines here ]
This looks familiar, use the above information and your knowledge of the emp table to compose:
UNLOAD TABLE emp ( empno number, ename char, job char, mgr number,
hiredate date, sal number, comm number deptno number)
STORAGE ( TABNO 0 EXTENTS( FILE 1 BLOCK 10530));
- use this statement to unload emp:
$ dul UnLoader: Version 2.0.0.0 - Very Restricted on Tue May 16 11:46:33 1995 Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved. Loaded 350 segments Loaded 204 extents Extent map sorted DUL> UNLOAD TABLE emp ( empno number, ename char, job char, mgr number, DUL 2> hiredate date, sal number, comm number deptno number) DUL 3> STORAGE ( TABNO 0 EXTENTS( FILE 1 BLOCK 10530)); . unloading table EMP 14 rows unloaded DUL>quit
Example unload session: Incorrect init.dul Parameters
WRONG osd_dba_file_bits size
This can generate output similar to below. Normally this should not happen since you should create a demo database and check this via the DUL documented (in html page) query.
The mismatch in DBA’s is only in the file number (first number in brackets) part. The second number, the block number, is correct.
Data UnLoader: Release 3.2.0.1 - Internal Use Only - on Wed Sep 3 10:40:33 1997 Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved. Session altered. Session altered. Session altered. Session altered. Session altered. DUL: Warning: Block[1][2] DBA in block mismatch [4][2] DUL: Warning: Bad cache layer header file#=1, block#=2 DUL: Warning: Block[1][3] DBA in block mismatch [4][3] DUL: Warning: Bad cache layer header file#=1, block#=3 ...........and etc..........
WRONG osd_file_leader_size
This may create output similar to below, but many other flavours are possible. In this case we are a fixed number of blocks off. The file number is correct. The difference in the block numbers is constant.:
Data UnLoader: Release 3.2.0.1 - Internal Use Only - on Wed Sep 3 10:44:23 1997 Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved. Session altered. Session altered. Session altered. Session altered. Session altered. DUL: Warning: Block[1][2] DBA in block mismatch [1][3] DUL: Warning: Bad cache layer header file#=1, block#=2 DUL: Warning: Block[1][3] DBA in block mismatch [1][4] DUL: Warning: Bad cache layer header file#=1, block#=3 ...........and etc..........
WRONG osd_c_struct_alignment
This may generate output similar to the following:
Data UnLoader: Release 3.2.0.1 - Internal Use Only - on Wed Sep 3 10:46:10 1997 Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved. Session altered. Session altered. Session altered. Session altered. Session altered. . unloading table OBJ$ DUL: Warning: file# 0 is out of range DUL: Warning: Cannot read data block file#=0, block# = 262145 OS error 2: No such file or directory DUL: Warning: file# 0 is out of range DUL: Warning: Cannot read data block file#=0, block# = 262146 OS error 2: No such file or directory ...........and etc..........
WRONG db_block_size
The following output was generated when the db_block_size was set too small. The correct value was 4096 and it was set to 2048. Normally, the value for this parameter should be taken from the Oracle instances’s init.ora file and will not be correctly set.
Data UnLoader: Release 3.2.0.1 - Internal Use Only - on Thu Sep 4 12:38:25 1997 Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved. Session altered. Session altered. Session altered. Session altered. Session altered. DUL: Warning: Block[1][2] DBA in block mismatch [513][1159680] DUL: Warning: File=1, block 2: illegal block version 2 DUL: Warning: Block[1][2] Illegal block type[0] DUL: Warning: Bad cache layer header file#=1, block#=2 DUL: Warning: Block[1][4] DBA in block mismatch [1][2] DUL: Warning: File[1]Block[4]INCSEQ mismatch[90268!=0] DUL: Warning: Bad cache layer header file#=1, block#=4 DUL: Warning: Block[1][6] DBA in block mismatch [1][3] DUL: Warning: File[1]Block[6]INCSEQ mismatch[139591710!=86360346] DUL: Warning: Bad cache layer header file#=1, block#=6 ...........and etc..........
QUOTE MISSING
If you get the following error it is caused by the data dictionary tables “USER$, OBJ$, TAB$ and COL$” not being correctly generated. To fix this error simply delete all dictv6.ddl or dictv7.ddl created .dat and .ctl files and restart.
Data UnLoader: Release 3.2.0.1 - Internal Use Only - on Wed Sep 3 10:49:30 1997
Copyright (c) 1994/95 Oracle Corporation, The Netherlands. All rights reserved.
DUL: Error: Quote missing
Salvaging data from corrupt EXP dump files – UNEXP Tutorial
If you do not know anything about the structure of a EXP dump file this can be difficult. Here is a quick explanation. Apart from the file header a dump file has MARKERS that identify the various sections. In each table section there will be SQL statements. The most interrsesting part is the create table statement, followed by the insert into table statement. The insert statement is directly followed by the bind information, (number of columns, and for each column its type and bind length and a small bit more). Then it is followed by the actual columns. Each column is preceded by a two byte length, followed by the actual column data. There are several tricks for longer columns possible. The end of the column data is marked by the special length marker OXFFFF. There is no marker for the beginning of a row. Resynching after a corruption is trial and error. Corruption are generally not immediate detectable. The format is slightly different for DIRECT export, so you will have to use the DIRECT option for DIRECT exports. The offset to be specified is the beginning of a row. In general the first one directly behind the bind array, but for optimal flexibility you can start anywhere in the row data.
The first step is to scan the dump file to find the offsets and the sql statements. Each output line starts with the offset where the item is found.

DUL> scan dump file expdat.dmp;
0: CSET: 1 (US7ASCII) # Character set info from the header
3: SEAL EXPORT:V10.02.01 # the Seal - the exp version tag
20: DBA SYSTEM # exp done as SYSTEM
8461: CONNECT SCOTT # section for user SCOTT
8475: TABLE "EMP"
# complete create table staement
8487: CREATE TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2),
"COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0)) PCTFREE 10 PCTUSED 40
INITRANS 1 MAXTRANS 255 STORAGE(INITIAL 65536 FREELISTS 1
FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "USERS" LOGGING NOCOMPRESS
# Insert statement
8829: INSERT INTO "EMP" ("EMPNO", "ENAME", "JOB", "MGR", "HIREDATE",
"SAL", "COMM", "DEPTNO") VALUES (:1, :2, :3, :4, :5, :6, :7, :8)
# BIND information
8957: BIND information for 8 columns
col[ 1] type 2 max length 22
col[ 2] type 1 max length 10 cset 31 (WE8ISO8859P1) form 1
col[ 3] type 1 max length 9 cset 31 (WE8ISO8859P1) form 1
col[ 4] type 2 max length 22
col[ 5] type 12 max length 7
col[ 6] type 2 max length 22
col[ 7] type 2 max length 22
col[ 8] type 2 max length 22
Conventional export # Conventional means NOT DIRECT
9003: start of table data # Here begins the first row
Now build an unexp statement from the create table statement and the direct/conventional information and the start of the column data.
UNEXP TABLE "EMP" ("EMPNO" NUMBER(4, 0), "ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9), "MGR" NUMBER(4, 0), "HIREDATE" DATE, "SAL" NUMBER(7, 2),
"COMM" NUMBER(7, 2), "DEPTNO" NUMBER(2, 0))
dump file expdat.dmp from 9003;
Unloaded 14 rows, end of table marker at 9670 # so we have our famous 14 rows
This builds the normal SQL*Loader file and a matching control file. In the output file one extra column is added, this is related to the status of the row. A P means the row is Partial, (some columns missing) R means Resynch, it is the first row after a resynchronisation. O means Overlap, the previous row had errors, but the new row partly overlaps the other one.
Table Of Contents
~~~~~~~~~~~~~~~~~
1. Introduction
2. Using DUL
2.1 Create an appropriate init.dul file
2.2 Create the control.dul file
2.3 Unload the object information
2.4 Invoke DUL
2.5 Rebuild the database
3. How to rebuild object definitions that are stored in the data dictionary ?
4. How to unload data when the segment header block is corrupted ?
5. How to unload data when the file header block is corrupted ?
6. How to unload data without the system tablespace ?
7. Appendix A : Where to find the executables ?
8. References
1. Introduction
~~~~~~~~~~~~~~~
This document is to explain how to use DUL rather than to give a full
explanation of Bernard’s Data UnLoader capabilities.
This document is for internal use only and should not be given to customers at
any time, Dul should always be used by or under the supervision of a support
analyst.
DUL (Data UnLoader) is intended to retrieve data from the Oracle Database that
cannot be retrieved otherwise. This is not an alternative for the export
utility or SQL*Loader. The database may be corrupted but an individual data
block used must be 100% correct. During all unloading checks are made to make
sure that blocks are not corrupted and belong to the correct segment. If a
corrupted block is detected by DUL, an error message is printed in the loader
file and to the standard output, but this will not terminate the unloading of
the next row or block.
2. Using DUL
~~~~~~~~~~~~
First you must retrieve the necessary information about the objects that exists
in the database, these statistics will be loaded into the DUL dictionary to
unload the database objects.
This information is retrieved from the USER$, OBJ$, TAB$ and COL$ tables that
were created at database creation time, they can be unloaded based on the fact
that object numbers are fixed for these tables due to the rigid nature of sql.
bsq. DUL can find the information in the system tablespace, therefor the system
tablespace datafile(s) must be included in the control file, if this datafile(s)
is not present see chapter 6.
2.1 Create an appropriate “init.dul” file
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
REM Platform specific parameters (NT)
REM A List of parameters for the most common platforms can be obtained from
REM
osd_big_endian_flag=false
osd_dba_file_bits=10
osd_c_struct_alignment=32
osd_file_leader_size=1
osd_word_size = 32
REM Sizes of dul dictionary caches. If one of these is too low startup will
REM fail.
dc_columns=2000000
dc_tables=10000
dc_objects=1000000
dc_users=400
dc_segments=100000
REM Location and filename of the control file, default value is control.dul
REM in the current directory
control_file = D:\Dul\control_orcl.dul
REM Database blocksize, can be found in the init<SID>.ora file or can be
REM retrieved by doing “show parameter %db_block_size%” in server manager
REM (svrmgr23/30/l) changes this parameter to whatever the block size is of
REM the crashed database.
db_block_size=4096
REM Can/must be specified when data is needed into export/import format.
REM this will create a file suitable to use by the oracle import utility,
REM although the generated file is completely different from a table mode
REM export generated by the EXP utility. It is a single table dump file
REM with only a create table structure statement and the table data.
REM Grants, storage clauses, triggers are not included into this dump file !
export_mode=true
REM Compatible parameter must be specified an can be either 6, 7 or 8
compatible=8
REM This parameter is optional and can be specified on platforms that do
REM not support long file names (e.g. 8.3 DOS) or when the file format that
REM DUL uses “owner_name.table_name.ext” is not acceptable. The dump files
REM will be something like dump001.ext, dump002.ext, etc in this case.
file = dump
A complete list can be obtained at
html section “DUL Parameters” although this init.dul file will work in most
cases and contains all accurate parameters to succesfully complete the
unloading.
2.2 Create the “control.dul” file
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A good knowledge about the logical tablespace and physical datafile
structure is needed or you can do the following queries when the database
is mounted :
Oracle 6, 7
———–
> connect internal
> spool control.DUL
> select * from v$dbfile;
> spool off
Oracle 8
——–
> connect internal
> spool control.DUL
> select ts#, rfile#, name from v$datafile;
> spool off
Edit the spool file and change, if needed, the datafile location and stripe
out unnecessary information like table headers, feedback line, etc…
A sample control file looks something like this :
REM Oracle7 control file
1 D:\DUL\DATAFILE\SYS1ORCL.DBF
3 D:\DUL\DATAFILE\DAT1ORCL.DBF
7 D:\DUL\DATAFILE\USR1ORCL.DBF
REM Oracle8 control file
0 1 D:\DUL\DATAFILE\SYS1ORCL.DBF
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF
1 3 D:\DUL\DATAFILE\USR2ORCL.DBF
2 4 D:\DUL\DATAFILE\DAT1ORCL.DBF
Note : Each entry can contain a part of a datafile, this can be useful when
you need to split datafiles that are too big for DUL, so that each
part is smaller than for example 2GB. For example :
REM Oracle8 with a datafile split into multiple parts, each part is
REM smaller than 1GB !
0 1 D:\DUL\DATAFILE\SYS1ORCL.DBF
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 1 endblock 1000000
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 1000001 endblock 2000000
1 2 D:\DUL\DATAFILE\USR1ORCL.DBF startblock 2000001 endblock 2550000
2.3 Unload the object information
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Start the DUL utility with the appropriate ddl (Dul Description Language)
script. There are 3 scripts available to unload the USER$, OBJ$, TAB$ and
COL$ tables according to the database version.
Oracle6 :> dul8.exe dictv6.ddl
Oracle7 :> dul8.exe dictv7.ddl
Oracle8 :> dul8.exe dictv8.ddl
Data UnLoader: Release 8.0.5.3.0 – Internal Use Only – on Tue Jun 22 22:19:
Copyright (c) 1994/1999 Bernard van Duijnen All rights reserved.
Parameter altered
Session altered.
Parameter altered
Session altered.
Parameter altered
Session altered.
Parameter altered
Session altered.
. unloading table OBJ$ 2271 rows unloaded
. unloading table TAB$ 245 rows unloaded
. unloading table COL$ 10489 rows unloaded
. unloading table USER$ 22 rows unloaded
. unloading table TABPART$ 0 rows unloaded
. unloading table IND$ 274 rows unloaded
. unloading table ICOL$ 514 rows unloaded
. unloading table LOB$ 13 rows unloaded
Life is DUL without it
This will unload the data of the USER$, OBJ$, TAB$ and COl$ data dictionary
tables into SQL*Loader files , this can not be manipulated into dump files
of the import format. The parameter export_mode = false is hardcoded into
the ddl scripts and can not be changed to the value “true” since this will
cause DUL to fail with the error:
. unloading table OBJ$
DUL: Error: Column “DATAOBJ#” actual size(2) greater than length in column
definition(1)
………….etc……………
2.4 Invoke DUL
~~~~~~~~~~~~~~
Start DUL in interactive mode or you can prepare a scripts that contains all
the ddl commands to unload the necessary data from the database. I will
describe in this document the most used commands, this is not a complete list
of possible parameters that can be specified. A complete list can be found at
section “DDL Description”.
DUL> unload database;
=> this will unload the entire database tables(includes sys’tables as well)
DUL> unload user <username>;
=> this will unload all the tables owned by that particullarly user.
DUL> unload table <username.table_name>;
=> this will unload the specified table owned by that username
DUL> describe <owner_name.table_name>;
=> will represent the table columns with there relative pointers to the
datafile(s) owned by the specified user.
DUL> scan database;
=> Scans all blocks of all data files.
Two files are generated:
1: seg.dat information of found segment headers (index/cluster/table)
(object id, file number, and block number).
2: ext.dat information of contiguous table/cluster data blocks.
(object id(V7), file and block number of segment header (V6),
file number and block number of first block,
number of blocks, number of tables)
DUL> scan tables;
=> Uses seg.dat and ext.dat as input.
Scans all tables in all data segments (a header block and at least one
matching extent with at least 1 table).
2.5 Rebuild the database
~~~~~~~~~~~~~~~~~~~~~~~~
Create the new database and use import or SQL*Loader to restore the data
retrieved by DUL. Note that when you only unloaded the data that table
structures, indexation, grants, PL/SQL and triggers will no longer exist in
the new database. To obtain an exactly same copy of the database as before
you will need to rerun your creation scripts for the tables, indexes, PL/SQL,
etc.
If you don’t have these scripts then you will need to perform the steps
described in section 3 of this document.
3. How to rebuild object definitions that are stored in the data dictionary
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
You want to rebuild PL/SQL(packages, procedures, functions or triggers), grants,
indexes, constraints or storage clauses(old table structure) with DUL. This can
be done but is a little bit tricky. You need to unload the relevant data
dictionary tables using DUL and then load these tables into a healthy database,
be sure to use a different user than sys or (system). Loading the data
dictionary tables of the crashed database into the healthy database dictionary
could corrupt the healthy database as well.
Detailed explanation to retrieve for example pl/sql packages / procedures /
functions from a corrupted database :
1) Follow the steps explained in the “Using DUL” section and unload the data
dictionary table “source$”
2) Create a new user into a healthy database and specify the desired default
and temporary tablespace.
3) Grant connect, resource, imp_full_database to the new user.
4) Import/load the table “source$” into the new created schema:
e.g.: imp80 userid=newuser/passw file=d:\dul\scott_emp.dmp
log=d:\dul\impemp.txt full=y
5) You can now query from the table <newuser.source$> to rebuild the pl/sql
procedures/functions from the corrupted database. Scripts can be found on
WebIv to generate such PL/SQL creation scripts.
The same steps can be followed to recreate indexes, constraints, and storage
parameters or to regrant privileges to the appropiate users. Please notice that
you always need to use a script of some kind that can recreate the objects and
include all the features of the crashed database version. For example : when
the crashed database is of version 7.3.4 and you have several bitmap indexes,
if you would use a script that supports version 7.3.2 or prior, then you won’t
be able to recreate the bitmap indexes succesful !
4. How to unload data when the segment header block is corrupted
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
When DUL can’t retrieve data block information on the normal way, it can scan
the database to create its own segment/extent map. The procedure of scanning
the database is necessary to unload the data from the datafiles.
(to illustrate this example I copied an empty block ontop of the segment header
block)
1) Create an appropiate “init.dul” (see 2.1) and “control.dul” (see 2.2) file.
2) Unload the table. This will fail and indicate that there is a corruption in
the segment header block:
DUL> unload table scott.emp;
. unloading table EMP
DUL: Warning: Block is never used, block type is zero
DUL: Error: While checking tablespace 6 file 10 block 2
DUL: Error: While processing block ts#=6, file#=10, block#=2
DUL: Error: Could not read/parse segment header
0 rows unloaded
3) run the scan database command :
DUL> scan database;
tablespace 0, data file 1: 10239 blocks scanned
tablespace 6, data file 10: 2559 blocks scanned
4) Indicate to DUL that it should use its own generated extent map rather than
the segment header information.
DUL> alter session set use_scanned_extent_map = true;
Parameter altered
Session altered.
DUL> unload table scott.emp;
. unloading table EMP 14 rows unloaded
5. How to unload data when the datafile header block is corrupted
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
A corruption in the datafile header block is always listed at the moment you
open the database this is not like a header segment block corruption (see point
4) where the database can be succesfully openend and the corruption is listed
at the moment you do a query of a table. Dul has no problems with recovering
from such situations although there are other alternatives of recovering from
this situation like patching the datafile header block.
The error you will receive looks something like :
ORACLE instance started.
Total System Global Area 11739136 bytes
Fixed Size 49152 bytes
Variable Size 7421952 bytes
Database Buffers 4194304 bytes
Redo Buffers 73728 bytes
Database mounted.
ORA-01122: database file 10 failed verification check
ORA-01110: data file 10: ‘D:\DATA\TRGT\DATAFILES\JUR1TRGT.DBF’
ORA-01251: Unknown File Header Version read for file number 10
6. How to unload data without the system tablespace
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
If datafiles are not available for the system tablespace the unload can still
continue but the object information can’t be retrieved from the data dictionary
tables USER$, OBJ$, TAB$ and COL$. So ownername, tablename and columnnames will
not be loaded into the DUL dictionary. Identifying the tables can be an
overwhelming task and a good knowledge of the RDBMS internals are needed here.
First of all you need a good knowledge of your application and it’s tables.
Column types can be guessed by DUL, but table and column names will be lost.
Any old system tablespace from the same database (may be weeks old) can be a
great help !
1) Create the “init.dul” file and the “control.dul” file as explained in above
steps 1 and 2. In this case the control file will contain all the datafiles
from which you want to restore but it doesn’t require the system tablespace
information.
2) Then You invoke dul and type the following command :
DUL> scan database;
data file 6 1280 blocks scanned
This will build the extent and segment map. Probably the dul command
interpreter will be terminated as well.
3) reinvoke the dul command interpreter and do the following :
Data UnLoader: Release 8.0.5.3.0 – Internal Use Only – on Tue Aug 03 13:33:
Copyright (c) 1994/1999 Oracle Corporation, The Netherlands. All rights res
Loaded 4 segments
Loaded 2 extents
Extent map sorted
DUL> alter session set use_scanned_extent_map = true;
DUL> scan tables; (or scan extents;)
Scanning tables with segment header
Oid 1078 fno 6 bno 2 table number 0
UNLOAD TABLE T_O1078 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN )
STORAGE ( TABNO 0 EXTENTS( FILE 6 BLOCK 2));
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 4 2 0% 0% 0% 100% 100% 0% 0%
2 4 10 0% 100% 100% 100% 0% 0% 0%
3 4 8 0% 100% 100% 100% 0% 0% 50%
“10” “ACCOUNTING” “NEW YORK”
“20” “RESEARCH” “DALLAS”
“30” “SALES” “CHICAGO”
“40” “OPERATIONS” “BOSTON”
Oid 1080 fno 6 bno 12 table number 0
UNLOAD TABLE T_O1080 ( C1 NUMBER, C2 UNKNOWN, C3 UNKNOWN, C4 NUMBER,
C5 DATE, C6 NUMBER, C7 NUMBER, C8 NUMBER )
STORAGE ( TABNO 0 EXTENTS( FILE 6 BLOCK 12));
Colno Seen MaxIntSz Null% C75% C100 Num% NiNu% Dat% Rid%
1 14 3 0% 0% 0% 100% 100% 0% 0%
2 14 6 0% 100% 100% 100% 0% 0% 21%
3 14 9 0% 100% 100% 100% 0% 0% 0%
4 14 3 7% 0% 0% 100% 100% 0% 0%
5 14 7 0% 0% 0% 0% 0% 100% 0%
6 14 3 0% 0% 0% 100% 100% 0% 0%
7 14 2 71% 0% 0% 100% 100% 0% 0%
8 14 2 0% 0% 0% 100% 100% 0% 0%
“7369” “SMITH” “CLERK” “7902” “17-DEC-1980 AD 00:00:00″ “800” “” “20”
“7499” “ALLEN” “SALESMAN” “7698” “20-FEB-1981 AD 00:00:00″ “1600” “300” “30”
“7521” “WARD” “SALESMAN” “7698” “22-FEB-1981 AD 00:00:00″ “1250” “500” “30”
“7566” “JONES” “MANAGER” “7839” “02-APR-1981 AD 00:00:00″ “2975” “” “20”
“7654” “MARTIN” “SALESMAN” “7698” “28-SEP-1981 AD 00:00:00″ “1250” “1400” “30”
Note : it might be best that you redirect the output to a logfile since
commands like the “scan tables” can produce a lot of output.
On Windows NT you can do the following command :
C:\> dul8 > c:\temp\scan_tables.txt
scan tables;
exit;
4) Identify the lost tables from the output of step 3; if you look carefully to
the output above then you will notice that the unload syntax is already given
but that the table name will be of the format t_0<objectno> and the column
names will be of the format C<no>; datatypes will not be an exact match of
the datatype as it was before.
Look especially for strings like “Oid 1078 fno 6 bno 2 table number 0″ where:
oid = object id, will be used to unload the object
fno = (data)file number
bno = block number
5) Unload the identified tables with the “unload table” command :
DUL> unload table dept (deptno number(2), dname varchar2(14),
loc varchar2(13)) storage (OBJNO 1078)
Unloading extent(s) of table DEPT 4 rows.
We have a very critical situation that requires DUL to extract data from a production down database.
– The database is in NOARCHIVELOG mode / Windows 64 bit platform.
– There is no backup available of the database since go life
– The database size is almost small but critical.
– There was a media failure since morning that corrupted all database data files except the datafile of real customer data.
– System tablespace is 100% corrupted as per db verify utility output.
– There is no backup for the system tablespace any where, even the test system is created as a new database, thus object IDs, rfile numbers are not the same.
We tried the following:
1. Unload data using system datafile from production (Failed to bootstrap as system datafile is corrupted)
2. Unload data using system datafile from TEST (Succeeded to bootstrap but failed to unload as miss match in rfile#,ts#, and object IDs .. expected result but worth trying)
3. Unload data using only the Datafile of actual data, succeed to generate the scaned_tables and we’ve requested from customer to provide the list of tables to be able to map, but i doubt they can provide clear information.
Appreciate suggesting any alternatives if any, something like:
– Is there any way to fix the corrupted system tablespace datafile and use it for data unload.
– Or, Is there any way to use system datafile from TEST (different database as new installation) where there is a miss match in rfile#, ts#, and object IDs.
I’m working with a client on a data salvage job. The DUL tool downloaded from DUL website is not working!!!
dul4x86-linux.tar.gz is giving me error: version ‘GLIBC_2.11’ not found
dul4i386-linux.as3.tar.gz is giving me error: You need a more recent DUL version for this os.
Client linux version: 2.6.32-400.33.2.el5uek
Please help!!!
There are two versions for linux and it is the second one below that is starting correctly. Because of the built-in copy protection, you must be sure to download the most recent version from Bernard’s website. If you do actually have the most recent download, then only Bernard can recompile and redistribute a new executable version. DUL expires approximately every 45 day
DUL unload scanned lobs
The idea is to unload lobs just from the lob segment.
We need to find out:
1. Is it a clob or a blob
2. for clobs the character set, single byte or UCS16, byte size
3. the chunk size, lob page# in the header is a fat page number
4. missing pages should be emitted as all zeroes
5. size is unknown, simply strip off trailing zeroes (but respect byte size)?
Changes implemented:
1. Add lob segment id to scanned lob page info as most properties apply to the segment. that is the layout of
the scanned lob pages cache is now: segid, lobid, fatpageno (chunk#), version wrap, vsn base, ts#, file#,
block#
Things to do:
1. Command to unload all lobs a lob segment provide all common properties in the command
2. Command to unload a single lob from lob segment specifying lobid, optional size, and optional dba list
3. Analyze command to produce command to unload lob segment
4. Analyze command to produce commands to unload each lob from segment
Things to consider:
1. change file#, block# to a single dba? pro no calculations, contra more difficult to read?
DUL disk header copy
disk header copy
Disk header copy
Lately there is an extra copy of the asm disk header. This copy can be used to fix the real header using kfed with the
repair option.
Location
This copy is stored as the last block of the PST. That means it is in the last block of allocation unit 1 (the original is
block 0 of au 0). The default sizes for an allocation unit is 1M and for the meta data block size is 4K, meaning 256
blocks in each au. So typically the copy is in au 1 block 254. (ASM counts from zero, the original is in allocation unit 0
block 0)
kfed repair
Provided you established that the only problem is with the lost/corrupt disk header, the fix is as simple as:
$ kfed repair
If the AU size is non-standard, the above will fail with something like:
KFED-00320: Invalid block num1 = ![[3]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/78/three_org.gif "[3]") , num2 =
, num2 = ![[1]](http://img.t.sinajs.cn/t35/style/images/common/face/ext/normal/82/one_org.gif "[1]") , error = [type_kfbh]
, error = [type_kfbh]
But that is expected and no harm is done. All you need to do is specify the correct AU size. E.g. for 4MB AU the
command would be:
$ kfed repair ausz=4194304
DUL
DUL will check/use the header copy (always? or only if the main header is bad?) Warn to use kfed if the header is
bad but the copy is good?
References
Bug 5061821 OS UTILITIES CAN DESTROY ASM DISK HEADER fixed 11.2.0.1, 11.1.0.7, 10.2.0.5 and higher.
Note 417687.1 Creating a New ASM Disk Header After Existing One Is Corrupted
rdbms/src/client/tools/kfed/kfed.c

create block index bak1 on ‘/dev/vg02/lvol1’;
UL version 10.2.0.5.13 with 64-bits i/o
Init.dul parameter settings:
_SLPE_DEBUG = FALSE
ALLOW_CHECKSUM_MISMATCH = TRUE
ALLOW_DBA_MISMATCH = FALSE
ALLOW_OTHER_OBJNO = FALSE
ALLOW_TRAILER_MISMATCH = TRUE
ASM_DO_HARD_CHECKS = TRUE
AUTO_UPDATE_CHECKSUM = TRUE
AUTO_UPDATE_TRAILER = TRUE
BUFFER = 1048576
CF_FILES = 1022
CF_TABLESPACES = 64
COMPATIBLE = 9
CONTROL_FILE = control.dul
DB_BLOCK_SIZE = 8k
DB_NAME =
DB_ID = 0
DC_COLUMNS = 100000
DC_OBJECTS = 128k
DC_TABLES = 10000
DC_USERS = 1000
DC_SEGMENTS = 10000
DC_EXTENTS = 10000
DEFAULT_CHARACTER_SET =
DEFAULT_NATIONAL_CHARACTER_SET =
EXPORT_MODE = FALSE
FEEDBACK = 0
FILE =
FILE_SIZE_IN_MB = 0
LDR_ENCLOSE_CHAR = ”
LDR_OUTPUT_IN_UTF8 = FALSE
LDR_PHYS_REC_SIZE = 0
LOGFILE = dul.log
MAX_OPEN_FILES = 8
OSD_MAX_THREADS = 1055
OSD_BIG_ENDIAN_FLAG = TRUE
OSD_DBA_FILE_BITS = 10
OSD_FILE_LEADER_SIZE = 1
OSD_C_STRUCT_ALIGNMENT =
OSD_WORD_SIZE = 32
PARSE_HEX_ESCAPES = FALSE
RESET_LOGFILE = TRUE
SCAN_DATABASE_SCANS_LOB_SEGMENTS = TRUE
SCAN_STEP_SIZE = 512
TRACE_FLAGS = 0
UNEXP_MAX_ERRORS = 1000
UNEXP_VERBOSE = FALSE
USE_LOB_FILES = FALSE
USE_SCANNED_EXTENT_MAP = FALSE
VERIFY_NUMBER_PRECISION = TRUE
WARN_RECREATE_FILES = TRUE
WRITABLE_DATAFILES = FALSE
DUL: Warning: ulimit data segment is only 4294967296
DUL: Warning: ulimit process stack size is only 268435456
Entries from control file control.dul:
DUL> create block index bak1 on ‘/dev/vg02/lvol1’;
DUL: Warning: Recreating file “IDX_BAK1.dat”
Scanning file /dev/vg02/lvol1 step size is 512
Found file 21 block 1 type 11 offs 16883712 delta 721537630208
db_name = EMIS, db_id = 800276271 tablespace rfile 21
extent of 9 blocks
Found file 21 block 137 type 16 offs 18227200 delta 721537400832