
- Unbreakable Enterprise Kernel 相关公开主页
- Fast, Modern, Reliable: Oracle Linux
- September 2011
- http://www.oracle.com/us/technologies/linux/uek-for-linux-177034.pdf
UEK R1(2.6.32base)的改良点(WP开始)
| 功能 | 内容 | 从执行这次的Oracle Database 的性能测试的角度来考虑 |
| Latest Infiniband Stack(OEFD) 1.5.1 | Infiniband的改善 | 不考虑(Infiniband无法准备) |
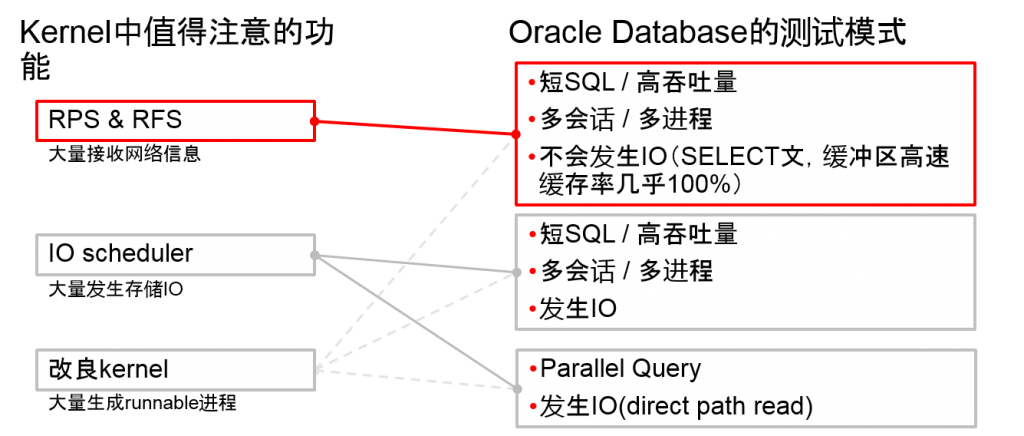
| Receive Packet Steering and Receive Flow Steering | 可以在多个CPU中分散网络接收信息的软分割处理 | 大量发生网络接收信息的操作
UEK R1的默认的CPU mask中,1个NICdevice的softirq处理为偏向1个CPU |
| Advanced support for large NUMA system | irqbalance处理为同一NUMA节点内
通过改善semaphore可以减少runqueue锁定竞争 |
进程较多 时的性能 |
| IO affinity | IO需求完成,在执行需求的CPU中执行 | 默认on/device的设定
large NUMA system中效果较好 |
| Improved asynchronous writeback performance | 改善kernel page cache的写回处理 | 是否与使用Direct IO的Oracle Database有关 |
| SSD detection | 如果检测到是SSD的话,就变更IO Scheduling | 作为Database Smart Flash Cache来使用SSD |
| Task Control Group | 可以制成用户定义的进程的group | 不考虑 |
| Hardware fault management | AER kernel driver可以记录PCIe的错误
MCE可以记录CPU/Memory的错误 |
不考虑 (无法再现HW的故障) |
| Power management features | UEK变成了tickless kernel
SATA的low-power mode |
不考虑 |
| Data integrity features | T10 Protection Information(T10-PI) | 不考虑 (无法准备对应存储) |
| Oracle Cluster File System 2 | OCFS2 v1.6 功能扩展 | 不考虑 (使用ASM) |
| Latencytop | 可以观测到怎样的信息 | |
| New fallocate() system call | 文件系统上的区域予約 | 不考虑 |
| 功能 | 内容 | 以执行这次的Oracle Database 的性能测试的角度来看的话 |
| IO scheduler | UEK的默认变更为deadline | 2.6.32默认为cfq(RHEL5兼容内核也是cfq)
是否影响IO性能 |
| Process Scheduler等 | 从2.6.18到2.6.32的upstream kernel的改良 | 多CPU核心/线程,多进程中的操作 |
UEK R1中值得注意的功能以及Oracle Database的测试模式
Oracle Linux 6 性能测试
- Oracle Linux 6 上的 Oracle Database 的操作在2012年3月23日时被certify了
- 仅限UEK R1,Redhat Compatible Kernel(RHEL兼容内核)
- UEK R2在2012年5月21日被certify
- Oracle Linux 6.2 (x86-64)
- Unbreakable Enterprise Kernel R1 (Linux 2.6.32base)
- Unbreakable Enterprise Kernel R2 (Linux 3.0.16base)
- uname 2.6.29
- Redhat Compatible Kernel(Linux 2.6.32base)
- Oracle Database 11g Release 2 (R 11.2.0.3)
- Oracle Linux 6中被 certify的仅限R 11.2.0.3以后
Oracle Linux 6 性能测试
- 网络接收信息的改良
- Ethernet device的接接收信息息的队列
- 单一队列以及多队列
- Receive Packet Steering 以及 Receive Flow Steering
- 软件模拟多队列
- Linux 2.6.35 开始Back port
- Ethernet device的接接收信息息的队列
- Flash Memory 的活用
- Oracle Database Smart Flash Cache
- (Oracle Linux 6 中的 Flash Cache的有效化)
- Fusion-io 制 Flash Memory的device驱动
- Oracle Linux 6 用 Smart Flash Cache 补丁
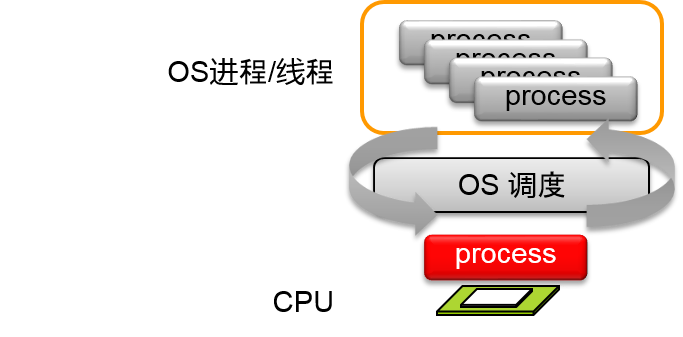
OS进程/线程(一般情况)
- 程序就是以进程/线程为単位进行抽象化
- OS进程/线程的总量即使CPU核心非常多的时候也可以操作
- OS的进程/线程日程表可以决定用那些进程/线程,以几个CPU核心来执行
- 程序就是以进程/线程为単位进行抽象化
- OS进程/线程的总量即使CPU核心非常多的时候也可以操作
- OS的进程/线程日程表可以决定用那些进程/线程,以几个CPU核心来执行
- CPU核心增加的话,当即也会使得CPU上可以执行的进程,线程也增加
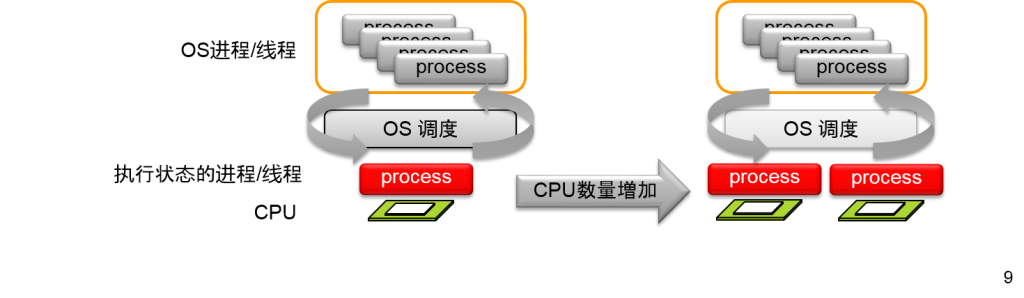
增加CPU核心(一般情况)
- 增加可以同时操作的OS进程/线程
- 增加响应的吞吐量上限
- 将响应时间保持在一定左右以下,增加同时需求数量
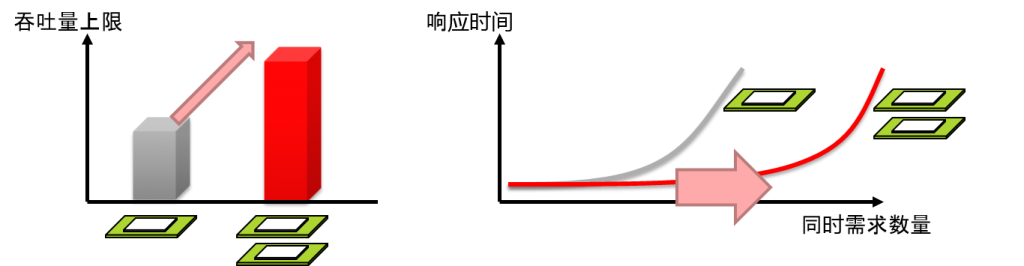
- 增加CPU核心
- 为了增加CPU的数据消費能力
- 也必须增加对CPU的数据供給能力
- 性能最差的因素会压制整体的性能
- 数据库服务器中,存储子系统经常会出现瓶颈
- 实际上,根据不同情况,导致瓶颈的因素也不同

- Network Interface Card 自身的接接收信息息队列
- 作为OS的内部操作,1个网络接收信息队列的「软分割处理的一部」负责1个CPU
- CPU饱和的话,网络接收信息处理功能也会饱和
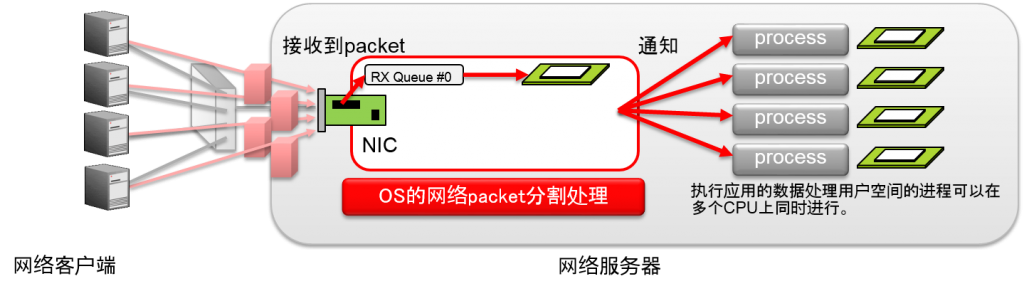
单一队列NIC的问题
- 网络接收的软分割处理由一个CPU负责
- CPU饱和的话,网络接收处理功能也会饱和
- 即使NIC的硬件带宽下降了
- 即使其他CPU使用率有富余
- CPU饱和的话,网络接收处理功能也会饱和
- OS内部的网络接收的软分割处理
- 由一个CPU负责的话,就会在接收大量packet时,饱和
- 通过多核心化增加1台的服务器拥有的CPU核心数量
- 1台可以处理的需求数量应该也会增加,但是……
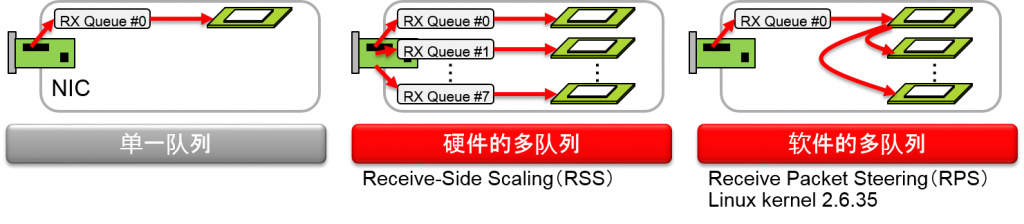
Ethernet NIC 的接收信息队列的改良
- 单一队列 NIC
- 台式电脑用 / 笔记个电脑用
- 硬件的多队列 NIC
- Receive-Side Scaling (RSS)
- 用于接收大量的网络packaet
- 服务器用NIC
- 在模拟软件中模拟多队列 NIC
- Receive Packet Steering (RPS)
- Linux kernel 2.6.35安装的功能
- UEK R1 (2.6.32base) 也安装了
网络接收信息处理的硬件的改良
- Receive-Side Scaling (RSS)
- NIC自身拥有多个队列
- 用多个CPU分担接收信息时的软分割处理
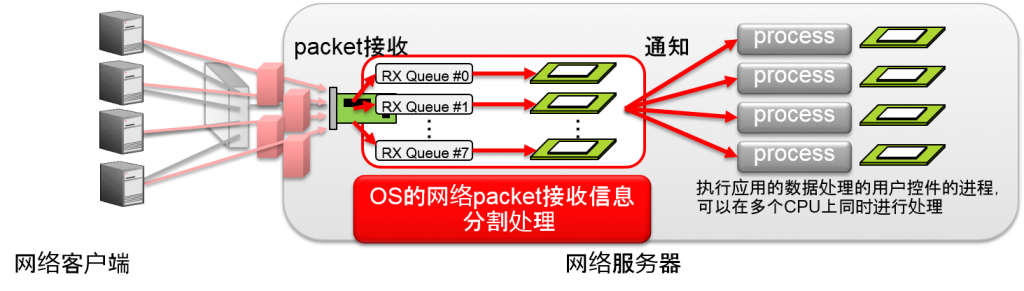
- NIC芯片自身有多个队列
- 例:Intel 82576EB

Receive-Side Scaling(RSS)
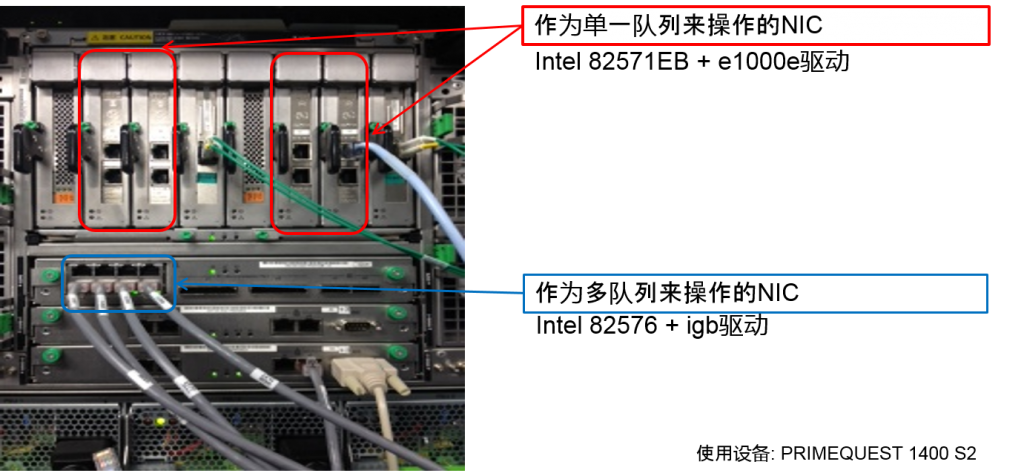
Linux中的NIC的单一队列/多队列查看方法
- /sys/class/net/ethX/queues/
- 作为多队列来操作的NIC会展示多个的接收信息队列(rx-n)
- 队列的个数量依赖于NIC芯片以及device驱动,CPU数量等

- /proc/interrupts
- 单一队列NIC中,对一个interface只能分割一个队列
- 多队列NIC时,对一个interface能分割多个队列

dmesg 命令
Intel(R) Gigabit Ethernet Network Driver - version 3.0.6-k2 Copyright (c) 2007-2011 Intel Corporation. igb 0000:05:00.0: PCI INT A -> GSI 16 (level, low) -> IRQ 16 igb 0000:05:00.0: setting latency timer to 64 alloc irq_desc for 52 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 52 for MSI/MSI-X alloc irq_desc for 53 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 53 for MSI/MSI-X alloc irq_desc for 54 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 54 for MSI/MSI-X alloc irq_desc for 55 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 55 for MSI/MSI-X alloc irq_desc for 56 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 56 for MSI/MSI-X alloc irq_desc for 57 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 57 for MSI/MSI-X alloc irq_desc for 58 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 58 for MSI/MSI-X alloc irq_desc for 59 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 59 for MSI/MSI-X alloc irq_desc for 60 on node -1 alloc kstat_irqs on node -1 alloc irq_2_iommu on node -1 igb 0000:05:00.0: irq 60 for MSI/MSI-X igb 0000:05:00.0: 0 vfs allocated igb 0000:05:00.0: Intel(R) Gigabit Ethernet Network Connection igb 0000:05:00.0: eth0: (PCIe:2.5Gb/s:Width x4) 00:17:42:9b:e0:50 igb 0000:05:00.0: eth0: PBA No: FFFFFF-0FF igb 0000:05:00.0: Using MSI-X interrupts. 8 rx queue(s), 8 tx queue(s) eth0 有多个的队列 (irq 52到60)
- NIC即使是硬件多队列,通过组合使用device驱动,也可以作为单一队列来操作
- NIC的芯片的目录中,即使记载了多队列/RSS,但在OS上要如何操作又是不同的
- RSS即使有效,也需要配合device驱动来查看
- Receive Packet Steering (RPS)
- NIC即使是单一队列,也需要在多个CPU中分担软分割处理的一部分
- 在软件中模拟多队列
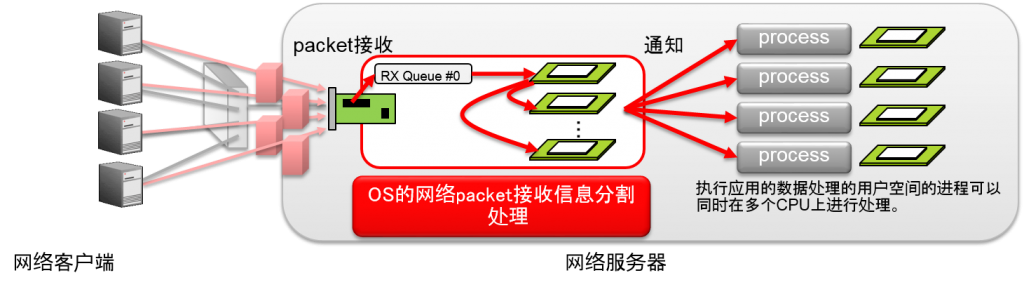
- Receive Packet Steering & Receive Flow Steering
- Linux 2.6.35 的功能back port 到UEK R1(2.6.32base)了
- Oracle Linux 5 + UEK R1中也可以使用
- RHEL中安装了6.1
- 网络device的1个接收信息队列的软分割处理由一个CPU负责
- 接收信息队列为1个device时,网络接受信息吞吐量就会到达上限
- 即使其他CPU核心有富余,网络需求就会到达上限,因为服务器性能也会到达上限
- Linux 2.6.35 的功能back port 到UEK R1(2.6.32base)了
- RPS&RFS可以使用软件,将一个网络接收信息队列的软分割处理分散在多个CPU中
- 可以改善单一队列NIC中的接收信息性能
- RPS/RFS中将软分割处理分散在多个CPU后们需要重新设定
- 设定文件如下所述
/sys/class/net/ethX/queues/rx-Y/rps_cpus(X为NIC的数量Y为队列的数量)
- 默认値
- 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000
- 如果设定为0的话,RPS就会无效。换言之,默认就是无效的
- 加入标签时,使用16进制,对各个CPU添加标签
(内部16进制被变更为2进制) - 例: echo f > /sys/class/net/eth0/queues/rx-0/rps_cpus的情况,2进制就变成了“1111”。
这时,通过RPS,可以成为CPU分割对象的CPU最多为3个。
- 使用RPS/RFS将软分割处理分散到多个CPU中,并且需要重新设定
- 系统整体的设定文件(系统整体中的设定値)
/proc/sys/net/core/rps_sock_flow_entries(默认値:0)
- 各个ethdevice的设定文件(各个device的设定値)
/sys/class/net/ethX/queues/rx-Y/rps_flow_cnt(默认値:0)
(X为NIC的数量,Y为队列的数量)
- 各设定文件中,可以设定任意值(仅限2的阶乘值)
- 将输入到/proc/sys/net/core/rps_sock_flow_entries中的值,设定为不超过所有ethdevice的rps_flow_cnt的合计值来进行设定
验证设备的1Gbps Ethernet NIC

Comment