
ORACLE RAC节点意外重启Node Eviction诊断流程图
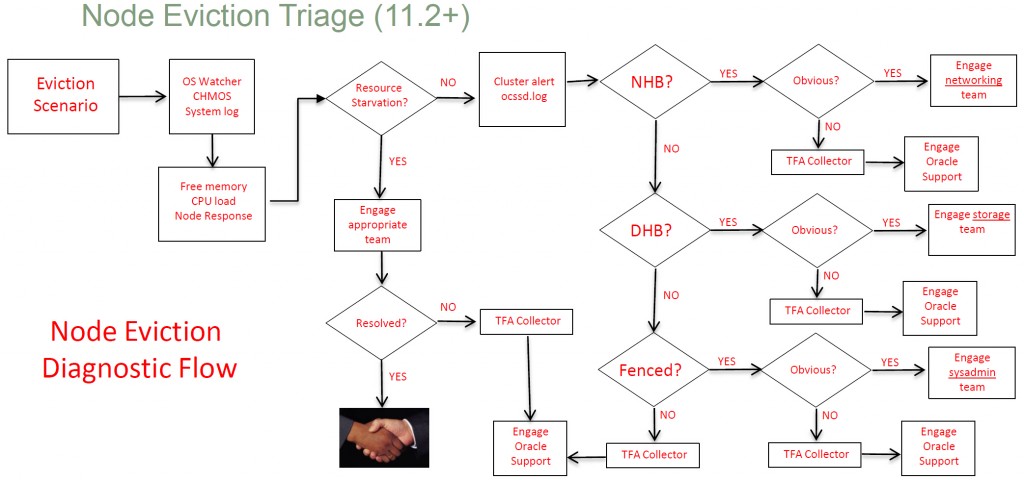
导致实例逐出的五大问题 (Doc ID 1526186.1)
适用于:
Oracle Database – Enterprise Edition – 版本 10.2.0.1 到 11.2.0.3 [发行版 10.2 到 11.2]
本文档所含信息适用于所有平台
用途
本文档针对导致实例驱逐的主要问题为 DBA 提供了一个快速概述。
适用范围
DBA
详细信息
问题 1:警报日志显示 ora-29740 是实例崩溃/驱逐的原因
症状:
实例崩溃,警报日志显示“ORA-29740:evicted by member …(被成员…驱逐)”错误。
可能的原因:
此问题的部分原因是集群中的通信错误、向控制文件发送“心跳”失败以及其它原因。
检查所有实例的 lmon 跟踪文件,这对确定实例驱逐的原因代码而言非常重要。查找包含“kjxgrrcfgchk:Initiating reconfig”的行。
这将提供一个原因代码,如“kjxgrrcfgchk:Initiating reconfig, reason 3”。实例驱逐时发生的大多数 ora-29740 错误是由于原因 3(“通信故障”) 造成的。
Document 219361.1 (Troubleshooting ORA-29740 in a RAC Environment) 介绍了以下几种可能造成原因 3的 ora-29740 错误原因:
a) 网络问题。
b) 资源耗尽(CPU、I/O 等)
c) 严重的数据库争用。
d) Oracle bug。
解决方案:
2) 检查网络配置,确保所有节点上的所有网络配置均设置正确。
例如,所有节点上 MTU 的大小必须相同,并且如果使用巨帧,交换机也能够支持大小为 9000 的 MTU。
3) 检查服务器是否存在 CPU 负载问题或可用内存不足。
4) 检查数据库在实例驱逐之前是否正处于挂起状态或存在严重的性能问题。
5) 检查 CHM (Cluster Health Monitor) 输出,以查看服务器是否存在 CPU 或内存负载问题、网络问题或者 lmd 或 lms 进程出现死循环。CHM 输出只能在特定平台和版本中使用,因此请参阅 CHM 常见问题 Document 1328466.1
6) 如果 OSWatcher 尚未设置,请按照 Document 301137.1 中的说明进行设置以运行 OSWatcher。
CHM 输出不可用时,使用 OSWatcher 输出将有所帮助。
问题 2:警报日志在实例崩溃或驱逐前显示“ipc send timeout”错误
症状:
实例驱逐时,警报日志显示许多“IPC send timeout”错误。此消息通常伴随数据库性能问题。
可能的原因:
lmon、lms 和 lmd 进程报告“IPC send timeout”错误的另一个原因是网络问题或服务器资源(CPU 和内存)问题。这些进程可能无法获得 CPU 运行调度或这些进程发送的网络数据包丢失。
涉及 lmon、lmd 和 lms 进程的通信问题导致实例驱逐。被驱逐实例的警报日志显示的信息类似于如下示例
IPC Send timeout detected.Sender: ospid 1519
Receiver: inst 8 binc 997466802 ospid 23309
如果某实例被驱逐,警报日志中的“IPC Send timeout detected(检测到 IPC 发送超时)”通常伴随着其它问题,如 ora-29740 和“Waiting for clusterware split-brain resolution(等待集群件“脑裂”解决方案)”
解决方案:
1) 检查网络,确保无网络错误,如 UDP 错误或 IP 数据包丢失或故障错误。
2) 检查网络配置,确保所有节点上的所有网络配置均设置正确。
例如,所有节点上 MTU 的大小必须相同,并且如果使用巨帧,交换机也能够支持大小为 9000 的 MTU。
3) 检查服务器是否存在 CPU 负载问题或可用内存不足。
4) 检查数据库在实例驱逐之前是否正处于挂起状态或存在严重的性能问题。
5) 检查 CHM (Cluster Health Monitor) 输出,以查看服务器是否存在 CPU 或内存负载问题、网络问题或者 lmd 或 lms 进程出现死循环。CHM 输出只能在特定平台和版本中使用,因此请参阅 CHM 常见问题 Document 1328466.1
6) 如果 OSWatcher 尚未设置,请按照 Document 301137.1 中的说明进行设置以运行 OSWatcher。
CHM 输出不可用时,使用 OSWatcher 输出将有所帮助。
问题 3:在实例崩溃或驱逐前,问题实例处于挂起状态
症状:
在实例崩溃/驱逐前,该实例或数据库正处于挂起状态。当然,也可能是节点挂起。
可能的原因:
在执行驱逐其他实例动作的实例警报日志中,您可能会看到与以下消息类似的消息:
Remote instance kill is issued [112:1]:8
或者
Evicting instance 2 from cluster
解决方案:
2) 检查 CHM (Cluster Health Monitor) 输出,以查看服务器是否存在 CPU 或内存负载问题、网络问题或者 lmd 或 lms 进程出现死循环。CHM 输出只能在某些平台和版本中使用,因此请参阅 CHM 常见问题 Document 1328466.1
3) 如果 OSWatcher 尚未设置,请按照 Document 301137.1 中的说明进行设置以运行 OSWatcher。
CHM 输出不可用时,使用 OSWatcher 输出将有所帮助。
问题 4:在一个或多个实例崩溃或驱逐前,警报日志显示“Waiting for clusterware split-brain resolution(等待集群“脑裂”解决方案)”
症状:
在一个或多个实例崩溃之前,警报日志显示“Waiting for clusterware split-brain resolution(等待集群件“脑裂”解决方案)”。这通常伴随着“Evicting instance n from cluster(从集群驱逐实例 n)”,其中 n 是指被驱逐的实例编号。
可能的原因:
常见原因有:
1) 实例级别的“脑裂”通常由网络问题导致,因此检查网络设置和连接非常重要。但是,因为如果网络已关闭,集群件 (CRS) 就会出现故障,所以只要 CRS 和数据库使用同一网络,则网络不太可能会关闭。
2) 服务器非常繁忙和/或可用内存量低(频繁的交换和内存扫描),将阻止 lmon 进程被调度。
3) 数据库或实例正处于挂起状态,并且 lmon 进程受阻。
4) Oracle bug
以上原因与问题 1的原因相似(警报日志显示 ora-29740 是实例崩溃/驱逐的原因)。
解决方案:
1) 检查网络,确保无网络错误,如 UDP 错误或 IP 数据包丢失或故障错误。
2) 检查网络配置,确保所有节点上的所有网络配置均设置正确。
例如,所有节点上 MTU 的大小必须相同,并且如果使用巨帧,交换机也能够支持大小为 9000 的 MTU。
3) 检查服务器是否存在 CPU 负载问题或可用内存不足。
4) 检查数据库在实例驱逐之前是否正处于挂起状态或存在严重的性能问题。
5) 检查 CHM (Cluster Health Monitor) 输出,以查看服务器是否存在 CPU 或内存负载问题、网络问题或者 lmd 或 lms 进程出现死循环。CHM 输出只能在特定平台和版本中使用,因此请参阅 CHM 常见问题 Document 1328466.1
6) 如果 OSWatcher 尚未设置,请按照 Document 301137.1 中的说明进行设置以运行 OSWatcher。
CHM 输出不可用时,使用 OSWatcher 输出将有所帮助。
问题 5:另一个实例尝试驱逐问题实例,但由于一些原因未能成功驱逐,最终CRS会终止该问题实例。
症状:
一个实例驱逐其他实例时,在问题实例自己关闭之前,所有实例都处于等待状态,但是如果问题实例因为某些原因不能终止自己,发起驱逐的实例将发出 Member Kill 请求。Member Kill 请求会要求 CRS 终止问题实例。此功能适用于 11.1 及更高版本。
可能的原因:
Remote instance kill is issued [112:1]:8
例如,以上消息表示终止实例 8 的 Member Kill 请求已发送至 CRS。
问题实例由于某种原因正处于挂起状态且无响应。这可能是由于节点存在 CPU 和内存问题,并且问题实例的进程无法获得 CPU 运行调度。
第二个常见原因是数据库资源争用严重,导致问题实例无法完成远程实例驱逐该实例的请求。
另一个原因可能是由于实例尝试中止自己时,一个或多个进程“幸存”了下来。除非实例的所有进程全部终止,否则 CRS 不认为该实例已终止,而且不会通知其它实例该问题实例已经被终止。这种情况下的一个常见问题是一个或多个进程变成僵尸进程且未终止。
并导致CRS通过节点重启或 rebootless restart( CRS 重新启动但节点不重启)进行重新启动。这种情况下,问题实例的警报日志显示
Instance termination failed to kill one or more processes
Instance terminated by LMON, pid = 23305
(实例终止未能终止一个或多个进程
实例被 LMON, pid = 23305 终止)
解决方案:
1) 查找数据库或实例挂起的原因。对数据库或实例挂起问题进行故障排除时,获取全局 systemstate 转储和全局hang analyze 转储是关键。如果无法获取全局 systemstate 转储,则应获取在大致相同时间所有实例的本地 systemstate 转储。
2) 检查 CHM (Cluster Health Monitor) 输出,以查看服务器是否存在 CPU 或内存负载问题、网络问题或者 lmd 或 lms 进程出现死循环。CHM 输出只能在某些平台和版本中使用,因此请参阅 CHM 常见问题Document 1328466.1
3) 如果 OSWatcher 尚未设置,请按照 Document 301137.1 中的说明进行设置以运行 OSWatcher。
CHM 输出不可用时,使用 OSWatcher 输出将有所帮助.

Comment