
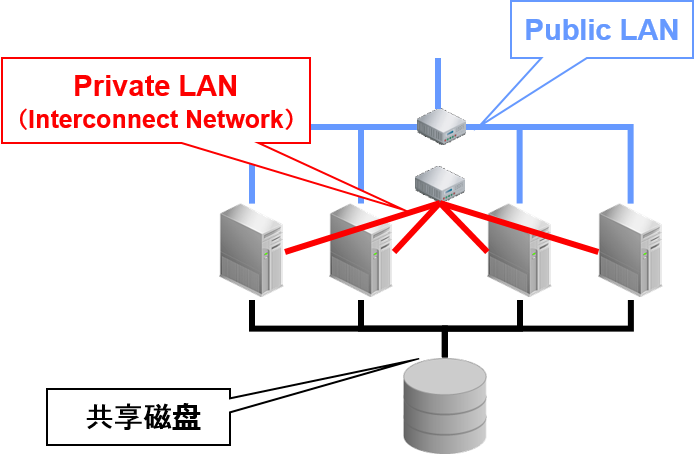
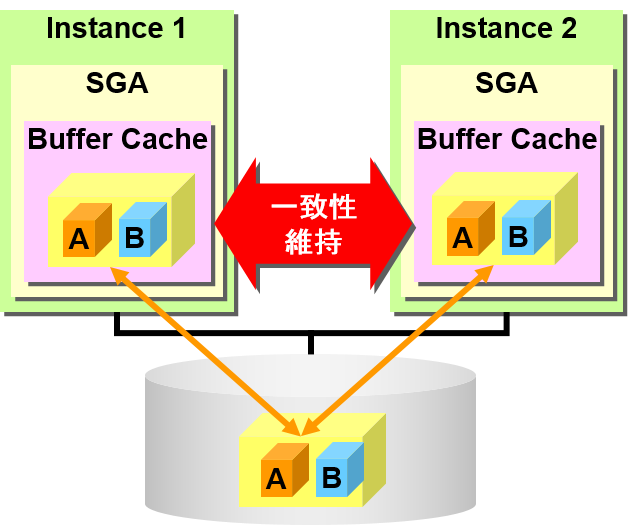
Oracle Real Application Clusters(RAC)
- 共享磁盘/共享高速缓存型cluster数据库
- 所有节点可以直接访问所有数据
- Oracle软件维持缓冲区高速缓存的一致性
- Cache Fusion Technology
- 可以通过所有节点来分散负荷
- 分离故障节点故障节点
- 全自动恢复处理
- 正常节点中不分散
构成RAC 的组成部分以及其功能
- Global Resource Directory (GRD)
- 在此说明RAC环境固有的数据库的内部操作:以GRD 为中心,在RAC环境中的锁定机制、实例恢复。
- Oracle Clusterware
- 在此说明10g RAC 的结构中必需的Oracle Cluster ware 。通过Oracle Cluster ware 来管理节点以及实例的membership的机制,10g RAC 的管理方法
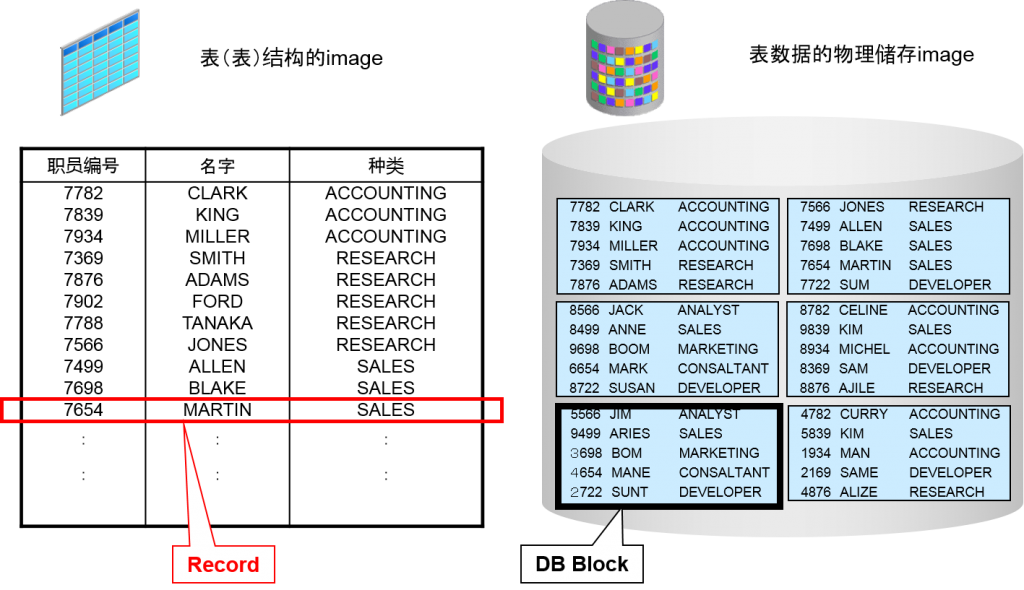
表数据的物理储存image
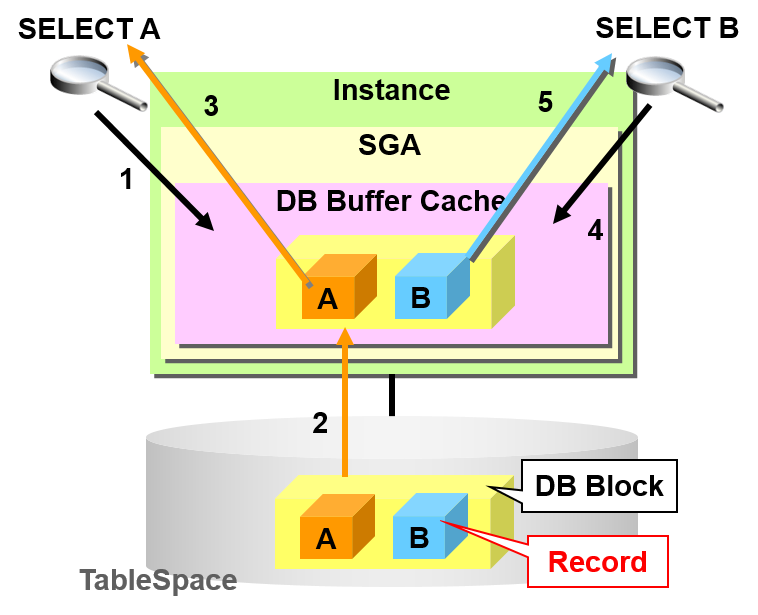
数据库的SELECT操作
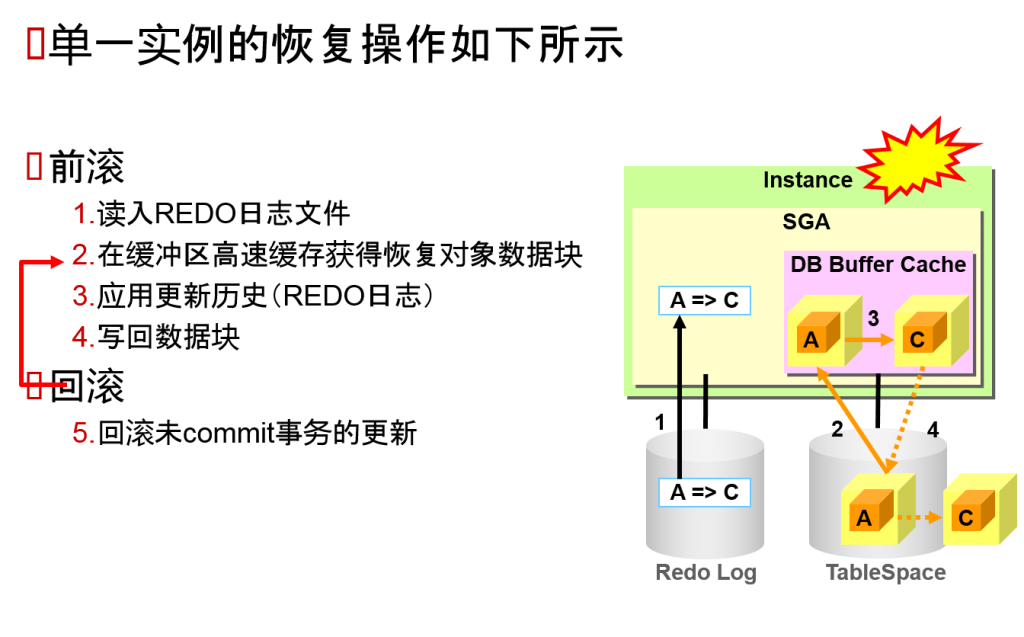
单一实例的SELECT的操作如下所示
SELECT 对象块中储存A与B的数据
- SELECT A
- 搜索缓冲区高速缓存,发现不存在(高速缓存miss)
- 从磁盘中读入DB块
- 抽出SELECT 对象的记录A
- SELECT B
- 搜索缓冲区高速缓存内发现存在(高速缓存命中)
- 抽出SELECT 对象的记录B
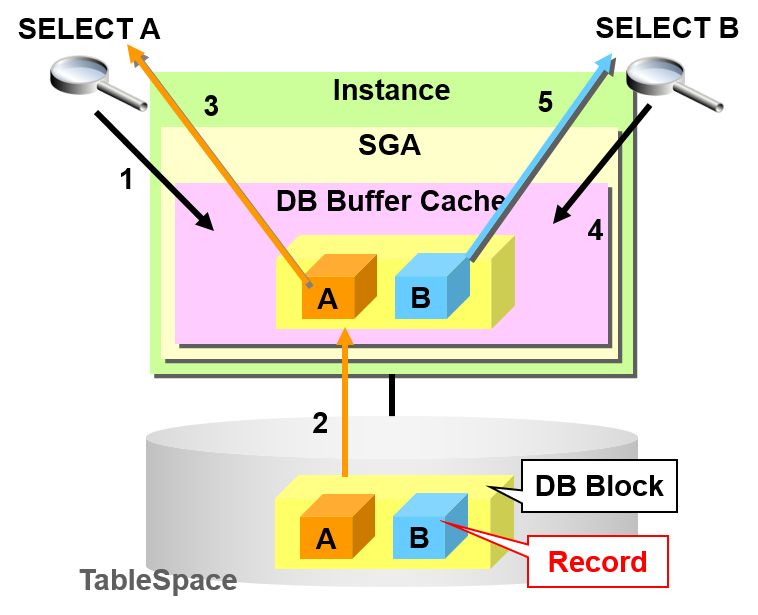
单一实例的UPDATE操作如下所示
- UPDATE A => C
- 在缓冲区高速缓存获得数据块
- 日志缓冲区中保存了更新历史
- 更新数据块
- COMMIT
- 对REDO日志文件写入2.的更新历史
- 非同步地对磁盘写回数据块
恢复的机制
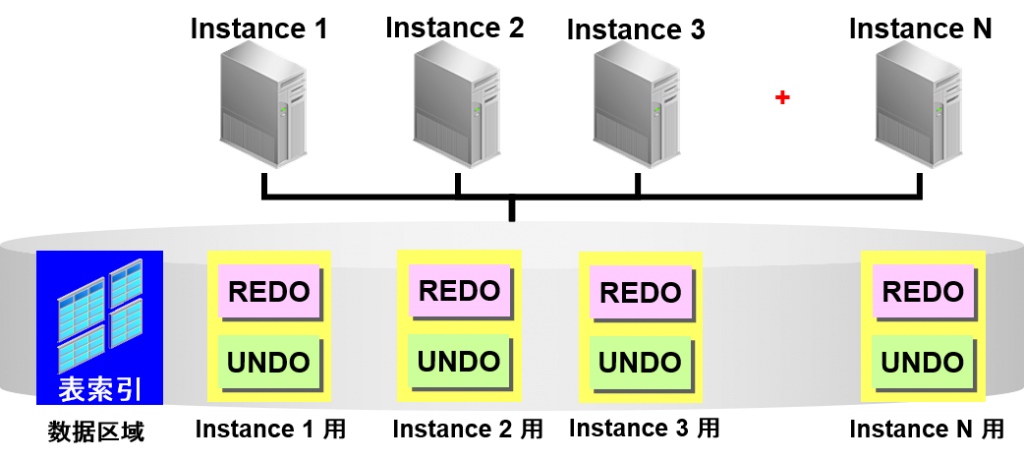
Oracle Real Application Clusters
hi 孙潇潇共享磁盘/共享高速缓存型cluster数据库
所有节点可以直接访问所有数据
通过Cache Fusion可以在多个节点之间保持缓冲区高速缓存的一致性
单一实例与同样的结构
在每个实例中追加
Redo日志、Undo表区域
分离故障节点
全自动恢复处理
正常节点中不分散
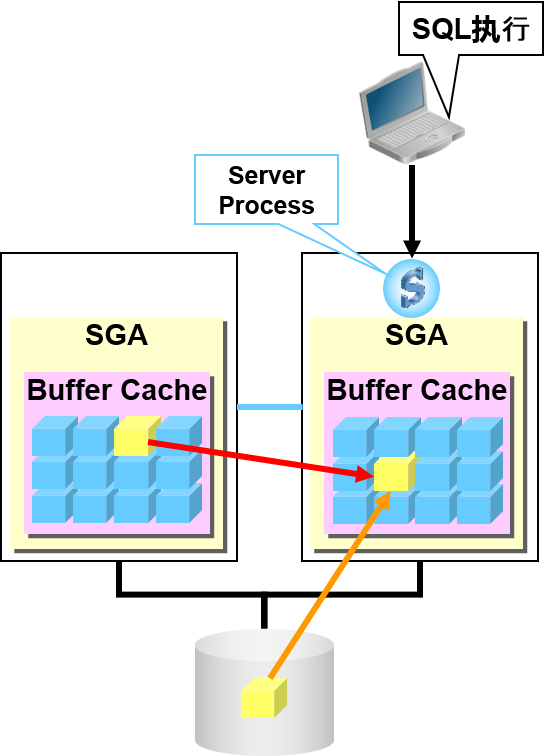
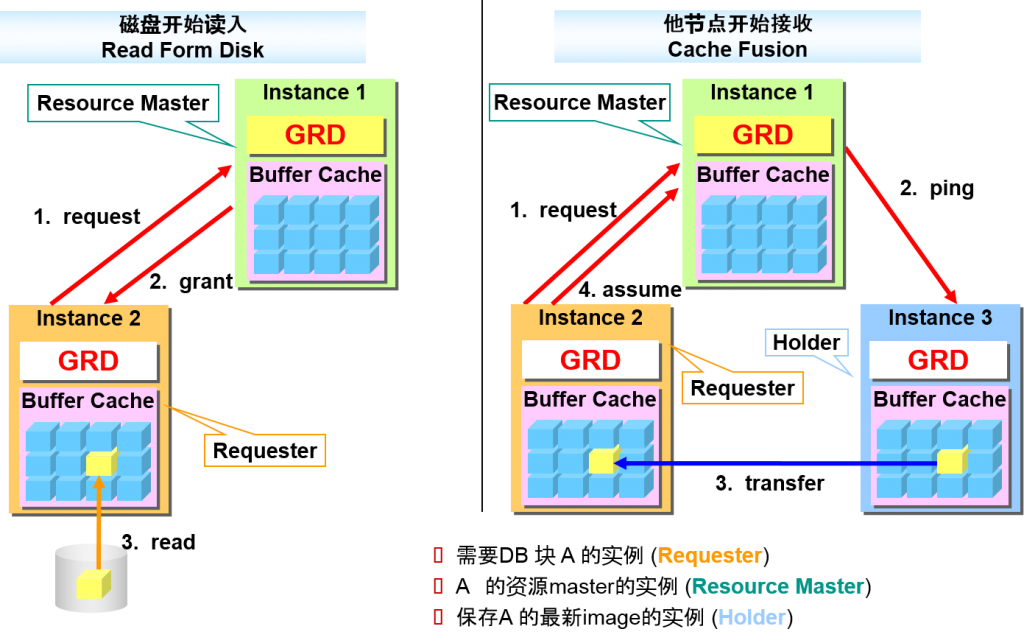
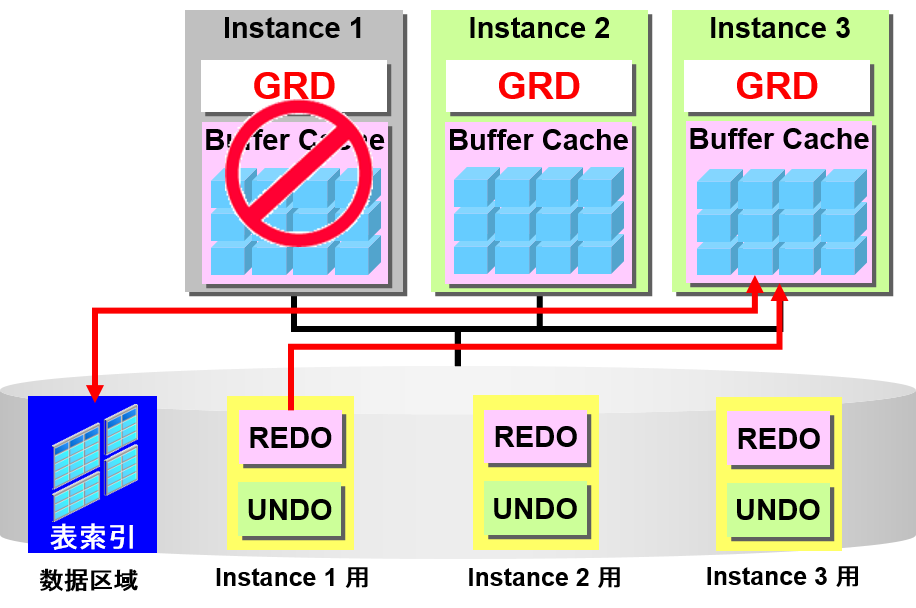
高速缓存miss的情况
- 单一实例
- 从磁盘开始读入
- Oracle Real Application Clusters
- 从磁盘开始读入
- 从他节点的高速缓存开始接收
- 命中了高速缓存的情况
- 单一实例
- 使用高速缓存的数据
- Oracle Real Application Clusters
- 使用高速缓存的数据
- 单一实例
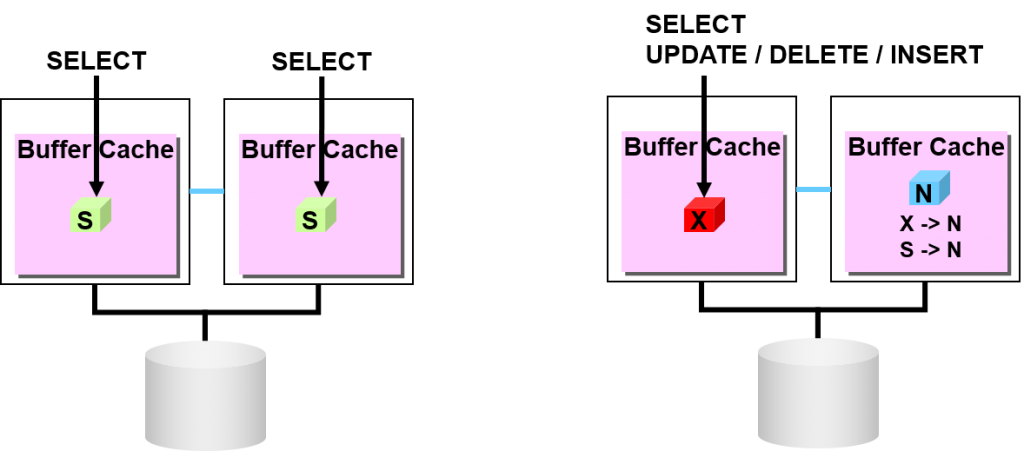
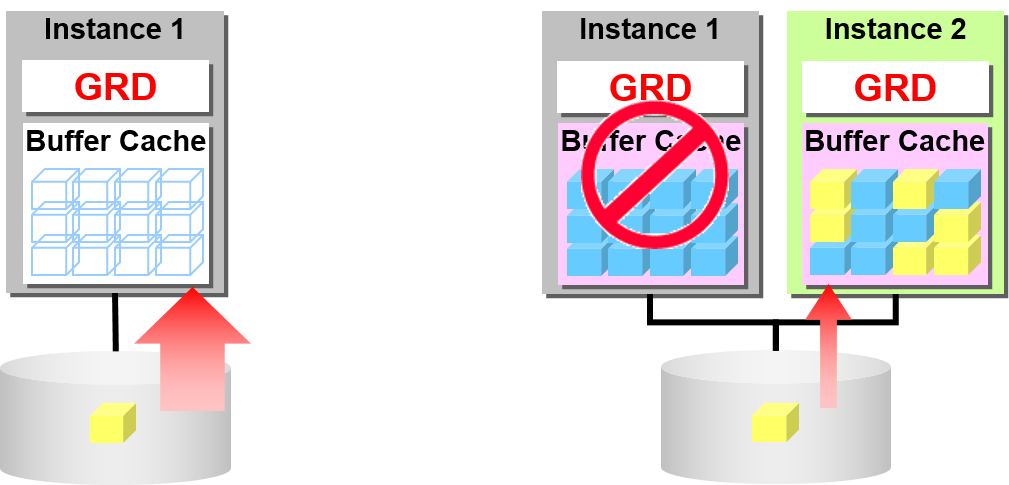
数据库块的锁定模式
共享锁定的块可以在多个节点中复制
- Shared 模式的数据块可以在多个节点中进行复制
- 使用多个节点,可以并列读出
更新需要将块设定为排他属性
- 只能有一个块可以拥有eXclusive 模式的数据块
- 将其他的节点高速缓存的数据块变换成 Null 模式
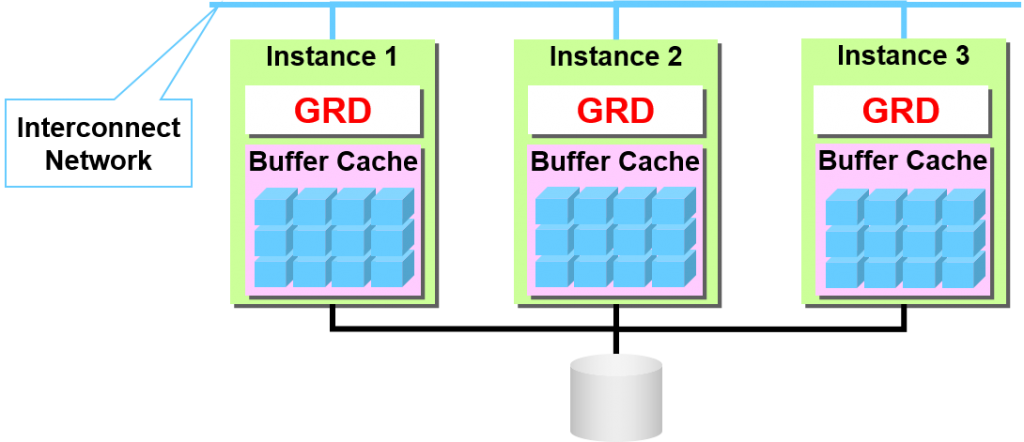
Global Resource Directory
Global Resource Directory(GRD)
–记录保存资源节点以及锁定状态的Directory
–将cluster的所有的节点的在主内存上进行分散配置
有着保持某个数据块锁定的状态的责任的GRD仅限cluster的节点之一,我们称为资源master
GRD是通过以下两个组成部分构成的
GCS:Global Cache Service
保护缓冲区高速缓存上的块
GES:Global Enqueue Service
保护块以外的对象(队列等)
通过以下的进程执行处理 (就会变成RAC固有的进程)
LMD0 (global enqueuer Service daemon)
对GES资源执行全盘调整的进程。
LMSn (global高速缓存服务进程)
GCS资源就是负责对块进行全盘调整的进程,高速缓存flash中,这个进程发挥了巨大作用。
LCK0 (锁定进程)
处理除library高速缓存以及dictionary高速缓存等、高速缓存Fusion以外的资源要求的进程。
LMON (全盘入队服务监视器)
监视GRD的重新架构以及cluster内的membership(IMR)的进程。
注意) RAC固有的进程除上述以外,还有DIAG进程。DIAG进程是跨越多个实例之间输出诊断信息的进程。
Cache Fusion 与 GRD 的关系
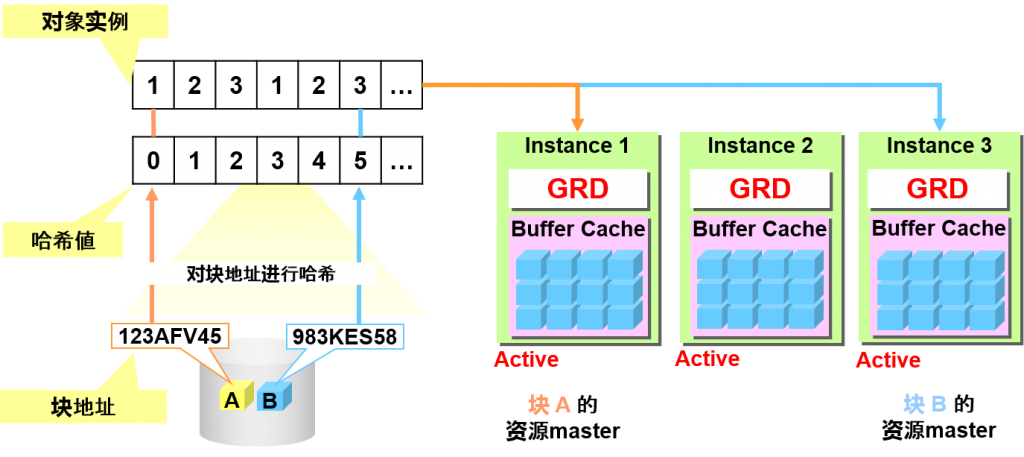
资源master的分配
某块的资源master的节点是根据块地址的哈希值来决定的
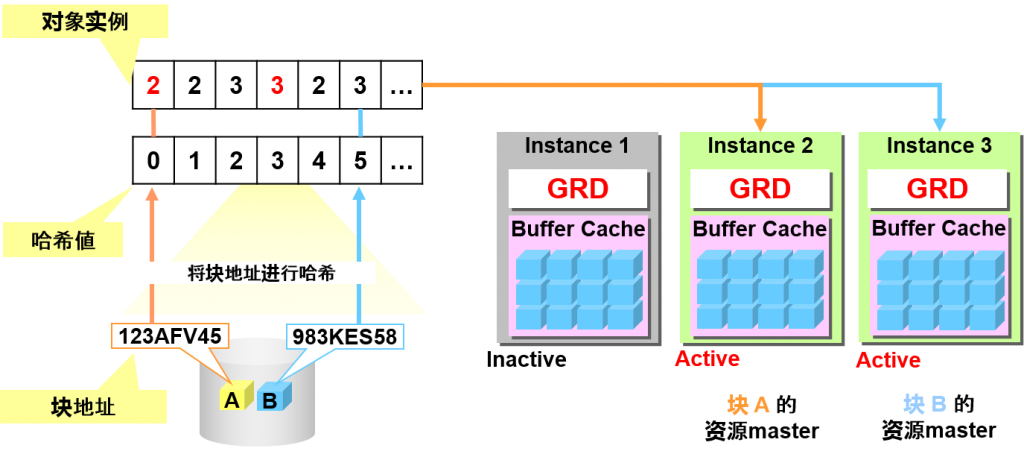
Instance 1 终止的话,就会在活跃实例中重新构成信息
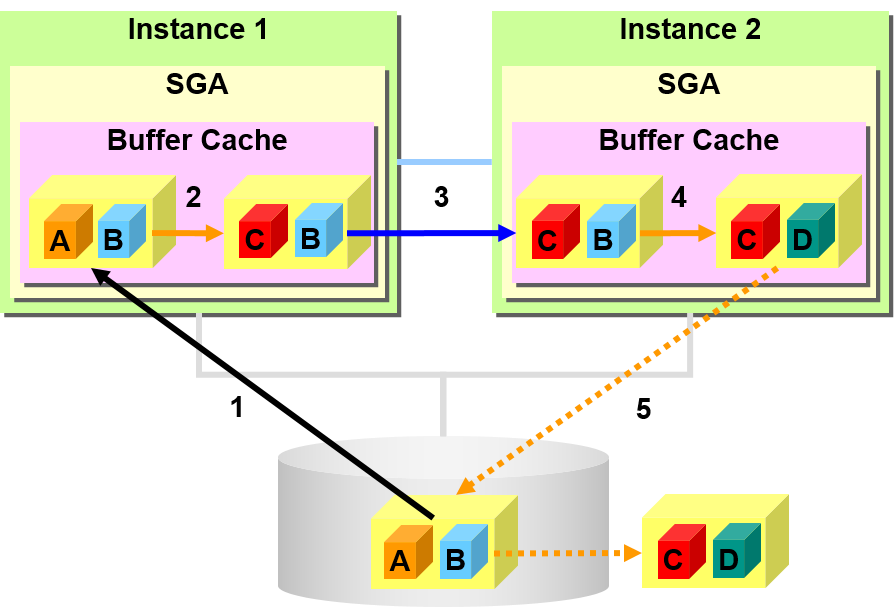
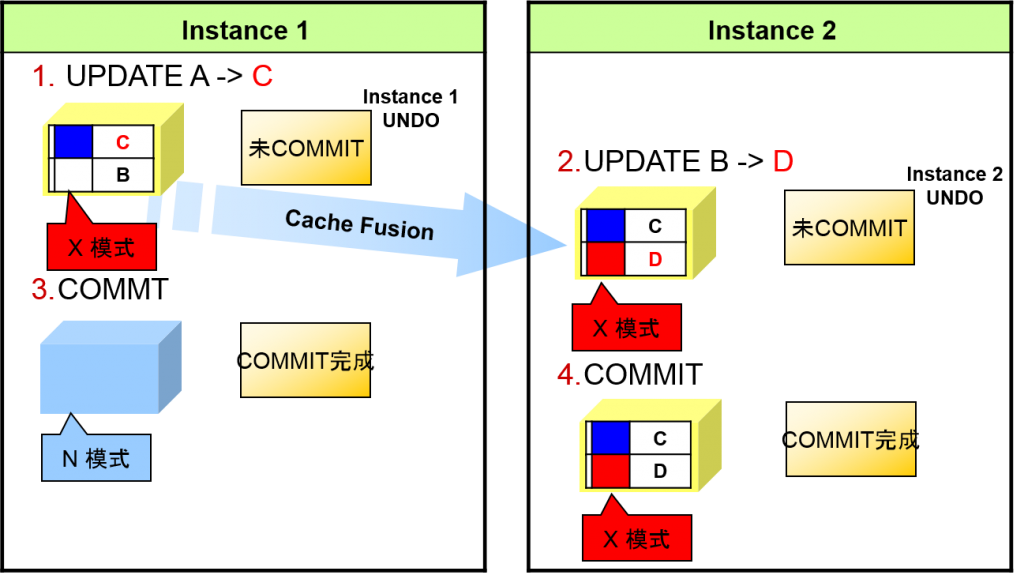
通过Cache Fusion 获得的高速缓存数据的一致性
两个实例同时执行同一个数据块的更新时
–对象块会储存A和B的数据
- Instance 1读入块
- Instance 1 更新【A】 -> 【C】
- Instance 1 向Instance 2 传送块
- Instance 2 更新 【B】 -> 【D】
- Instance 2写入块
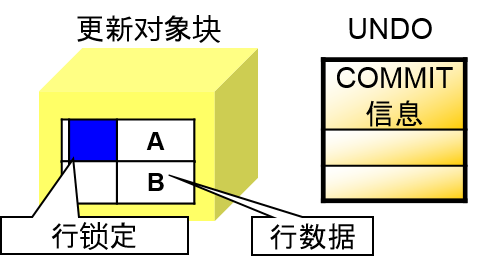
Cache Fusion 的锁定与行锁定的关系
对象是Cache Fusion 的锁定
Oracle 实例与数据块之间关系的锁定状态
事务的行水平锁定的状态的維持
某个实例以 X 模式被保存了,但这并不代表其他实例无法更新块了
行水平锁定与 COMMIT 的管理
可以通过DB 块 + UNDO来管理是否完成COMMIT
各行头中,写入了行锁定flag
UPDATE 文 -> 更新行数据
COMMIT ->更新 UNDO
即使行头中存在行锁定flag,UNDO中如果记录了commit完成的话,就会开放锁定
从2个实例中更新同一块内的其他记录
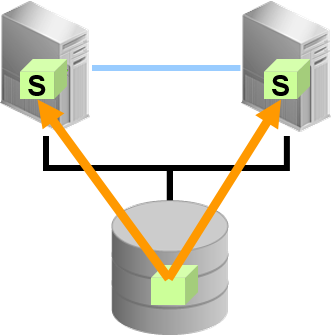
节点 本地内存访问并列化
节点本地内存访问并列化
不需要节点之间交换信息
library高速缓存(同一 SQL 文的内存上的)搜索、对REDO缓冲区的写入,保证Latch(内部的排他控制机制) 等
并列读出高速缓存块
可以复制Share 模式的块
共享内存的并列访问
没有发生DB块竞争的处理
不经过缓冲区高速缓存直接加载以及直接读取

Oracle RAC 数据库结构
追加节点时还会追加REDO日志、Undo表区域
–不需要重新构成数据以及修改应用(扩展性)
全节点可以访问所有磁盘的状态
–发生故障时,无论哪个节点都可以持续进行处理(可用性)
Oracle RAC 的恢复
不需要重启发生故障的实例
正常节点读入故障节点的REDO日志,执行块恢复
执行恢复的实例是获得IR入队的实例
Global Resource Directory 重新架构
单一实例的情况
冷启动(没有高速缓存)
需要开始读入所有恢复对象的块
RAC 的情况
开始在正常节点的缓冲区高速缓存中执行恢复
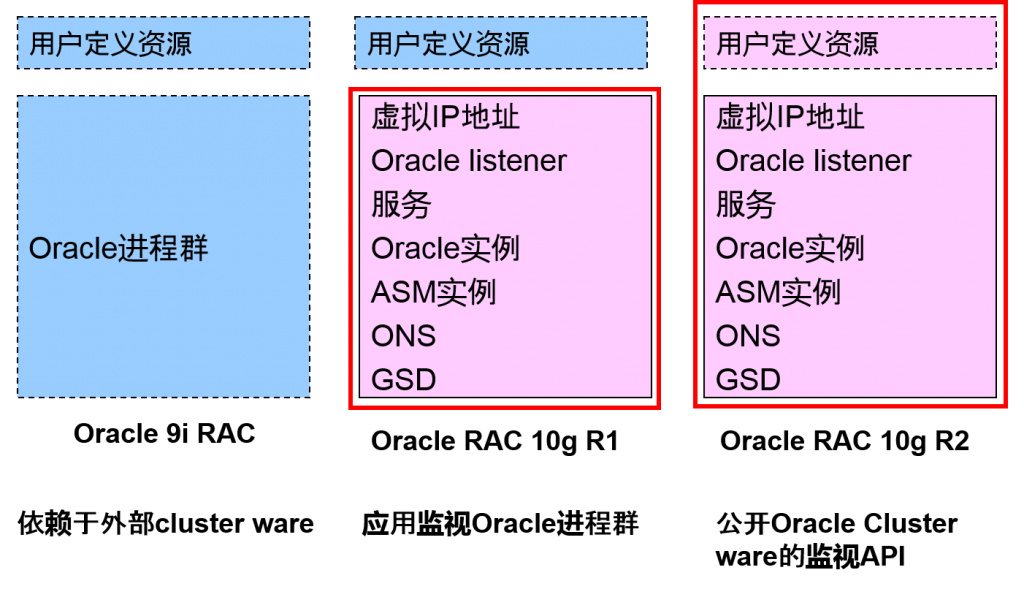
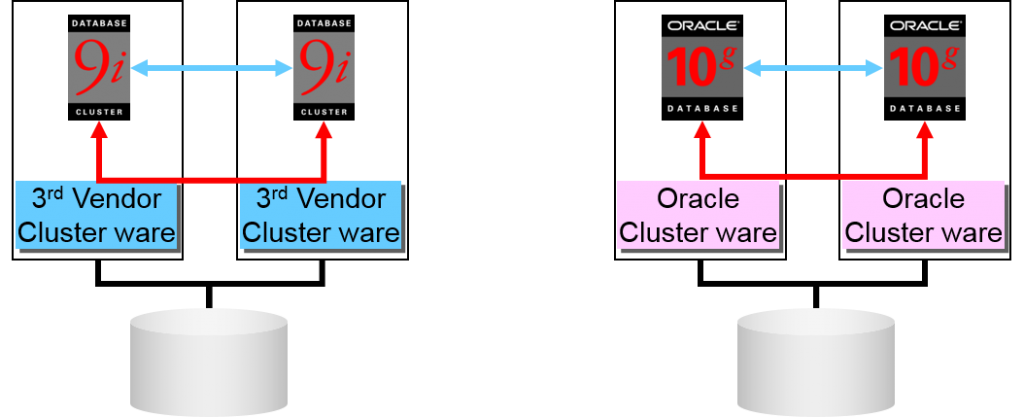
Oracle Clusterware 是什么
- 是构成Oracle Real Application Clusters 10g 所必需的部件之一。
–可以在没有第三方制作的cluster ware的情况下构成RAC
| Oracle9i RAC | Oracle RAC 10g | |
| 监视构成节点 | 第三方制作的cluster ware | Oracle Cluster ware |
| Oracle的故障监视与自律重启 | 通过cluster ware的监视,使用API来制作 | 标准装备 |

构成Oracle Clusterware 的部件
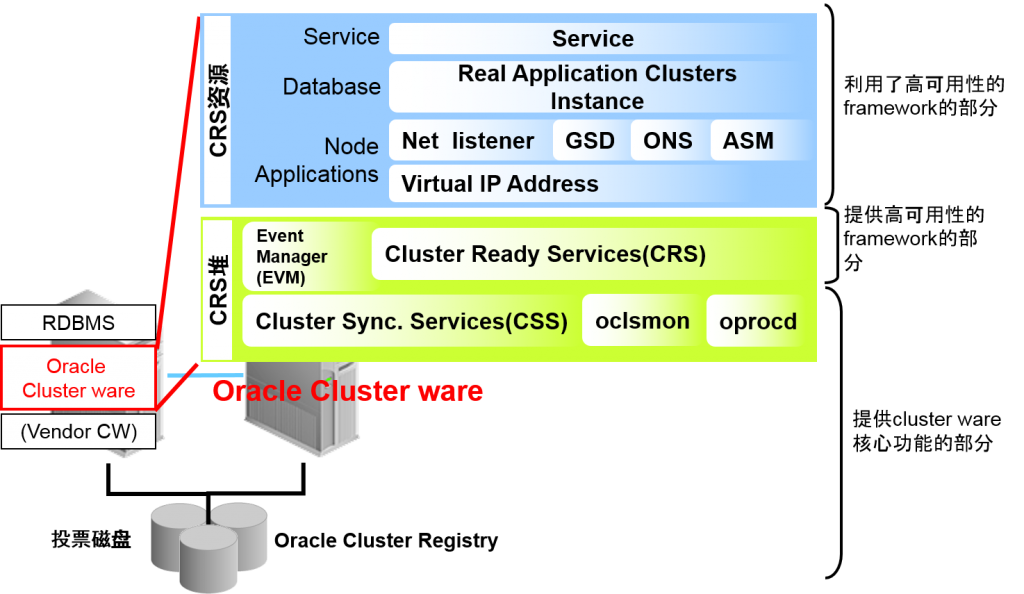
扩张Oracle Cluster ware 监视对象
- 3大daemon负责重要责任
- Event Manager
Oracle Cluster ware 内部的Event routing
- Cluster Ready Services
cluster资源监视
- Cluster Synchronization Services
cluster节点结构的一致性
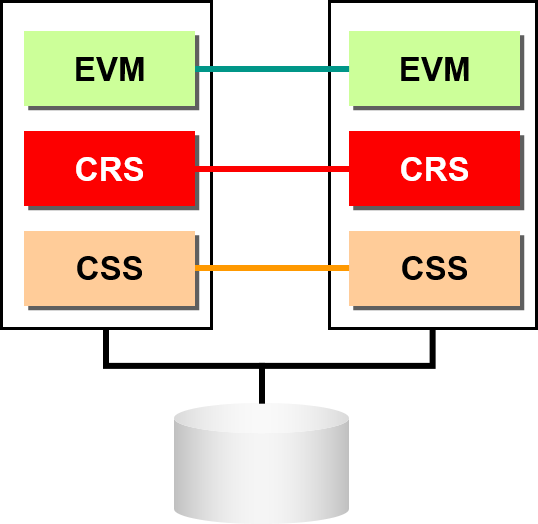
CRS 所需要的2个文件
2个文件在共享 Disk 中的设置
- Oracle Cluster Registry
保存cluster的结构信息
Oracle Cluster ware管理其所控制的进程信息
OCR可以多重化
- Voting Disk
节点之间信息交换发生故障时,各自的节点对可以与自身交换信息的节点进行投票的注册表
可以定义多个投票的磁盘
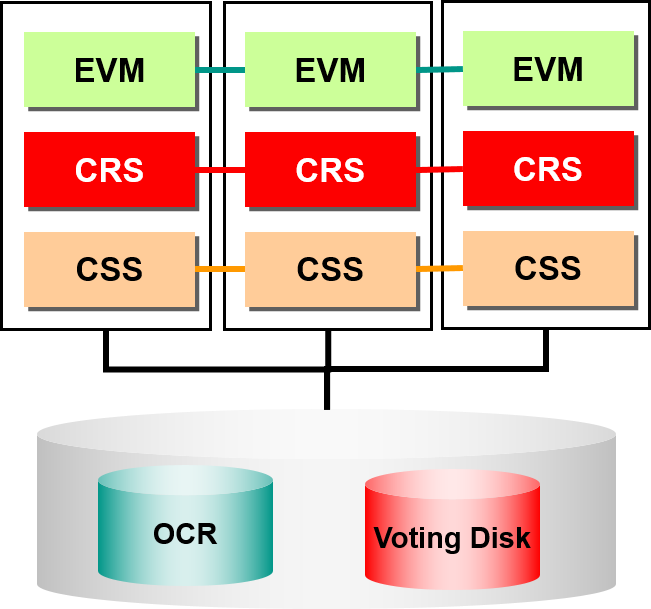
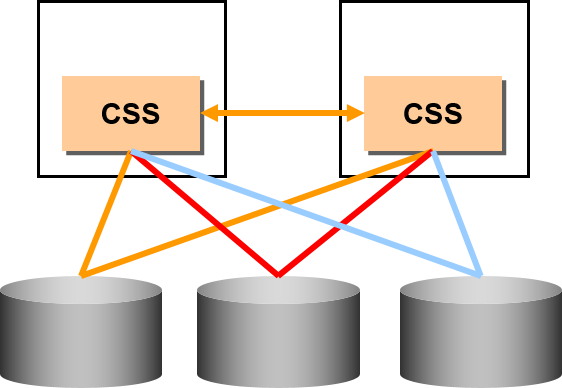
Cluster Synchronization Services : CSS
cluster节点结构的一致性
- 可用性管理对象
–cluster (节点)
Oracle数据库运行的节点
Private Interconnect
CSS所使用的cluster Interconnect
※作为GCS/GES回路指定其他的网络时,仅限CSS所使用的回路
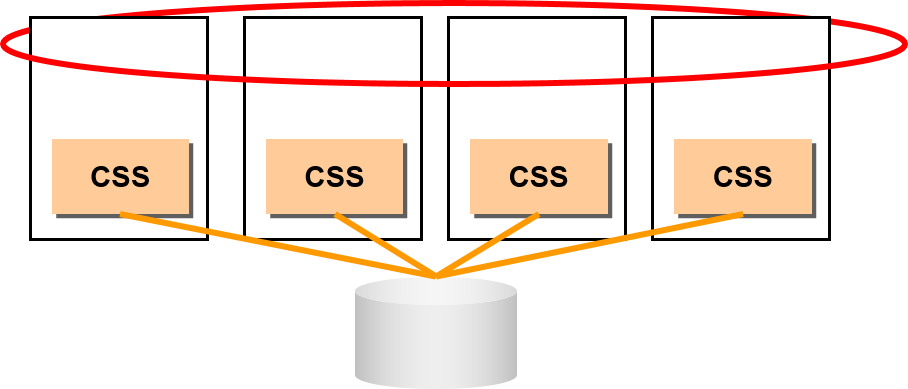
Cache Fusion是实例之间的直接信息交换
一部的内部管理信息经过cluster ware
如果cluster ware 没有与RAC 实例的Interconnect,那么就无法操作RAC。(请事先确认RAC 的系统结构。)
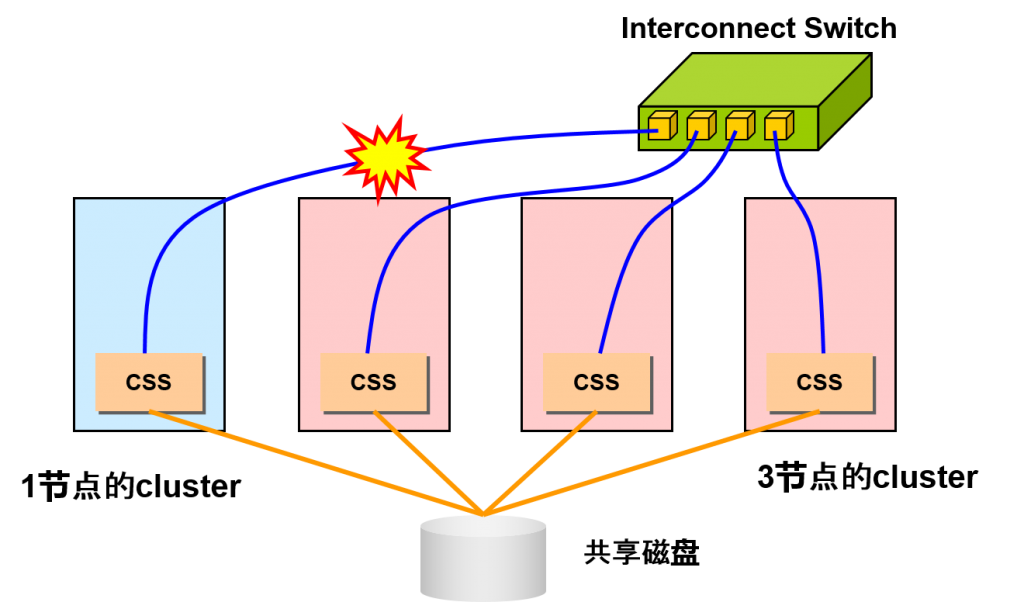
Split brain脑裂
- 因为节点之间信息交换存在问题,cluster被分散为多个
–cluster的一致性崩溃
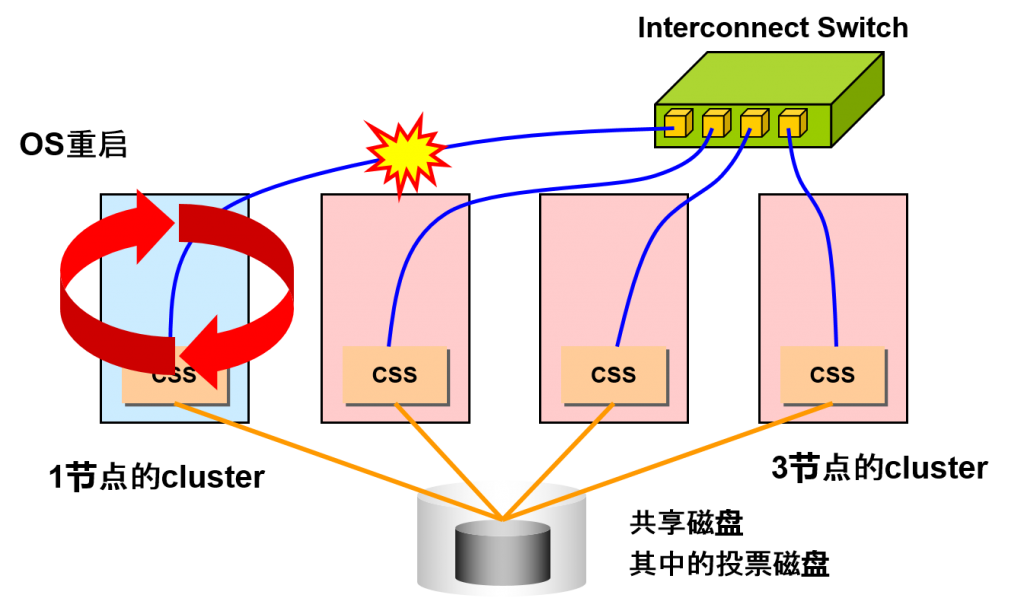
Split brain及其解决方法
- 使用投票磁盘,调整残存的节点
–残存的子cluster只有1个
解决CSS 的Split brain
- Interconnect中存在问题时
–多个子cluster可能破坏数据的一致性。
–会留下1个节点数较多的子cluster。
–Switch都发生故障时,留下一个节点。
–
- 节点故障也与解决Split brain相同
–无法访问之前存在的节点了!
CSS 的投票磁盘
- 无法访问投票磁盘时(I/O故障)
–那个节点会重启。
- 投票磁盘的可用性
–RAC 10g R1 中,依赖于硬件的冗余
–RAC 10g R2 中,可以定义多个投票磁盘
CSS 投票磁盘最多31个
(安装时最多可以指定3个)
CSS 的日志文件
- Split brain解決
–Interconnect故障
–节点故障
–投票磁盘故障 (磁盘I/O故障)
$ORA_CRS_HOME/log/<node_name>/cssd/ocssd.log
(超过CSS时间限制后,重新架构cluster节点)
[ CSSD]2006-01-30 21:37:13.356 [256519088] >TRACE: clssgmMasterSendDBDone: group/lock status synchronization complete
[ CSSD]CLSS-3000: 重新架构成功Incarnation 3 (1节点)
[ CSSD]CLSS-3001:本地节点编号1、masterー节点编号1
Cluster Ready Services : CRS
- 执行cluster资源的故障监视
–我们将CRS 的监视对象称为资源
- CRS 资源的故障监视
- 故障资源的重启
- 故障资源的文件过载

通过CRS 执行的资源操作与监视

通过CRS 执行的资源操作与监视
每个CRS 资源都有资源流程文件
–储存在共享磁盘上的 Oracle Cluster Registry之中
$ORA_CRS_HOME/bin/crs_stat -p [资源名]

通过CRS 监视资源与重启
CRS 每隔一段时间就需要确认资源状态
–如果检测到故障的话就试着重启资源
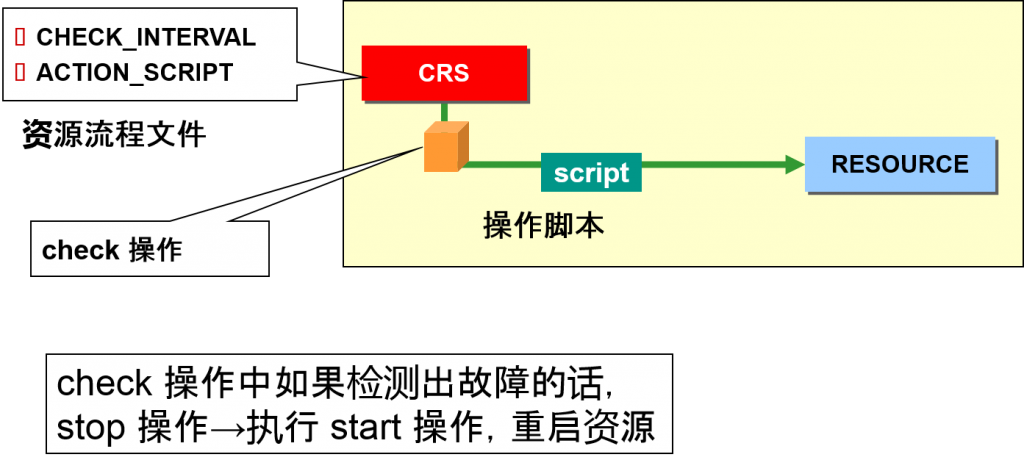
通过CRS 监视资源以及文件过载
- 无法重启资源时,就会产生文件过载
–通过別的节点启动资源
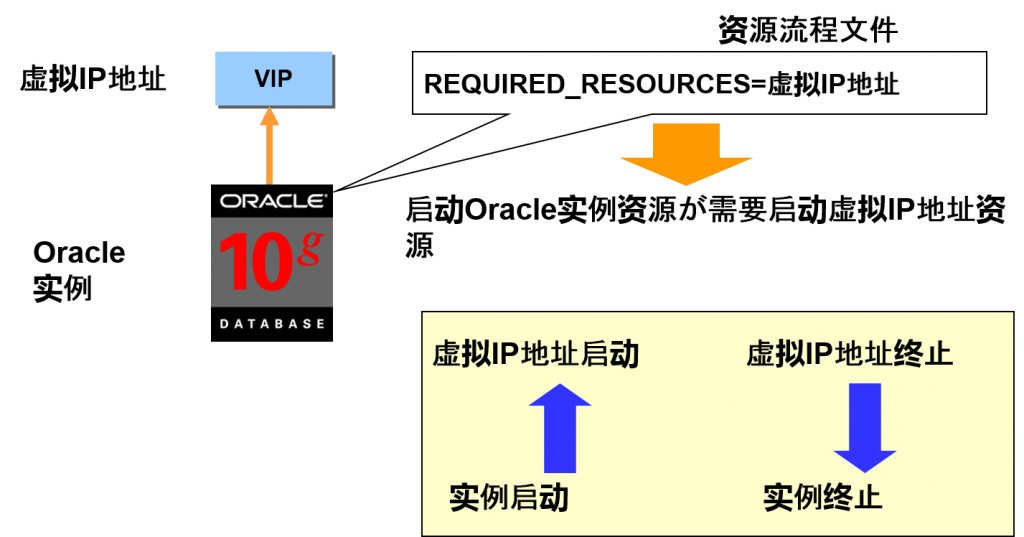
例)虚拟IP地址
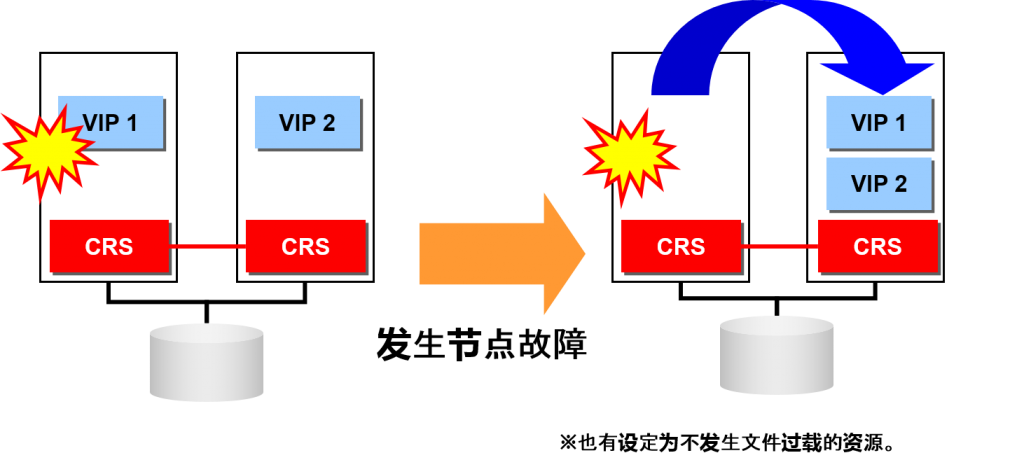
资源的依存关系
需要启动启动其他资源时
使用srvctl 管理Oracle
通过srvctl 管理 CRS 资源
确认CRS 资源的制成、删除、结构变动、启动、终止、使用不可/使用可能的変更的状态
从实例移动到实例的服务
srvctl 是通过数据库以及实例的 CRS 资源来制作的,实际上并不会制作数据库
不利用Database Configuration Assistant 来制成数据库时,利用srvctl 登录 CRS
listener的 CRS 资源无法使用 srvctl 来制作
制成时需要使用Net Configuration Assistant
启动/终止可以使用srvctl { start | stop } nodeapps
srvctl 的使用方法总结
- srvctl 处理内容 处理对象 [选项]
–add nodeapps, asm, database, instance, service
–disable database, instance, service
–enable database, instance, service
–modify nodeapps, asm, database, instance, service
–remove nodeapps, asm, database, instance, service
–Relocate service from one instance to another
–start nodeapps, asm, database, instance, service
–status nodeapps, asm, database, instance, service
–stop nodeapps, asm, database, instance, service
Event Manager : EVM
- Oracle Cluster ware 内部的Event routing
–管理者可以查看event
–故障实验非常方便,但不能应用于故障解析
- CRS资源启动/终止
- CSS节点脱离
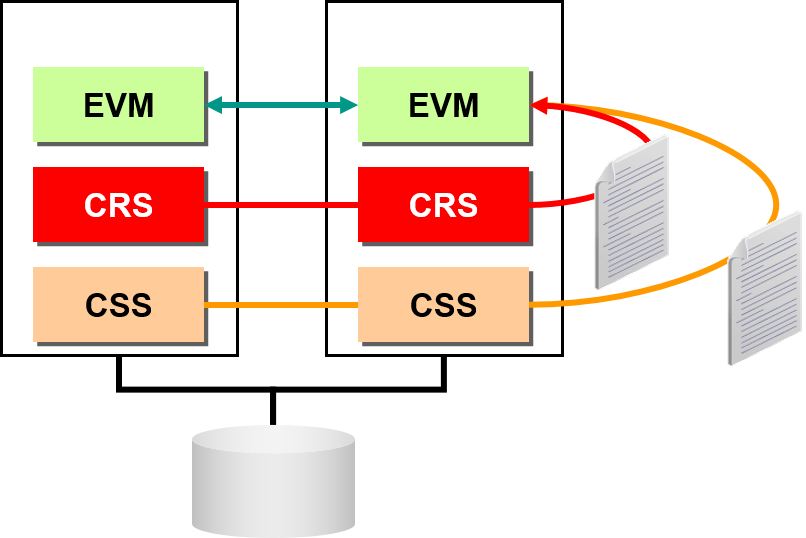
CRS 守护进程日志 与 EVM event日志
–将cluster广泛资源启动/终止日志聚集到一个之中
–要解析意外故障请观察 CRS/CSS 守护进程日志
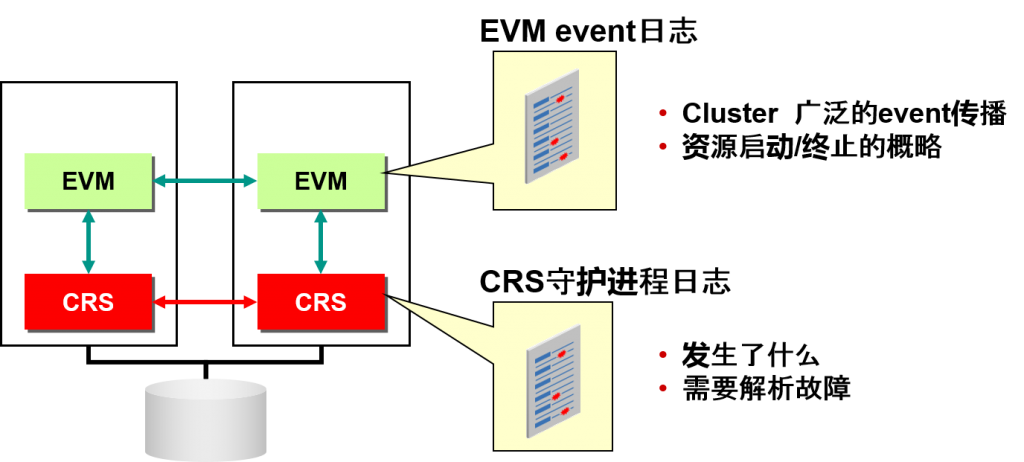
EVM 日志
- EVM 守护进程自身的日志
–启动EVM 守护进程
–$ORA_CRS_HOME/log/<节点名>/evmd/evmd.log
–
- EVM event日志
–CRS 资源的启动/终止等
–$ORA_CRS_HOME/evm/log/<节点名>_evmlog.<YYYYMMDD>
–请参考二进制文件的专用命令
参考EVM event日志
- $ORA_CRS_HOME/bin/
–evmshow -t <template> <log_file>
–evmwatch -A -t <template>
- -t <template>
–到底输出哪个event呢
evmwatch 的例 (实例监视器的检测event出现了)
$ evmwatch -A -t “[@timestamp][@host_name] @@”
“[11-Jan-2005 22:09:26][jpsun129d4] RAC: ora.orcl.orcl12.inst: imcheck: ”
“[11-Jan-2005 22:09:26][jpsun129d4] RAC: ora.orcl.orcl12.inst: imup: ”
@timestamp时刻 @host_name 产生event的主机名 @@信息本文
正常状态的 EVM event日志
- 实例监视器的检测event出现了

上述为2实例结构的RAC中的EVMevent的例子。
正常时,仅会出现实例监视器定期检测event。
存在ASM实例时,就会出现实例监视器的检测event。
会通知到所有节点中的所有实例监视器的检测event。
CRS 资源启动/终止的 EVM event日志
- 由此我们可以看出这里CRS 想启动资源
–观察CRS 守护进程的日志也可以看出
例) Oracle listener启动
$ evmwatch -A -t “[@timestamp][@host_name] @@”
“[13-Feb-2006 16:23:22][jpdelplzr] CRS ora.jpdelplzr. listener_JPDELPLZR.lsnr is transitioning from state OFFLINE to state ONLINE on member jpdelplzr”
由此启动listener
listener启动中…
“[13-Feb-2006 16:23:24][jpdelplzr] RAC: ora.jpdelplzr. listener_JPDELPLZR.lsnr: up: ”
“[13-Feb-2006 16:23:24][jpdelplzr] CRS ora.jpdelplzr. listener_JPDELPLZR.lsnr started on member jpdelplzr”
listener启动完成
EVM event: resource not restarting
- 意味着资源没有被重启
–这是因为没有文件过载的服务资源
–相关资源终止

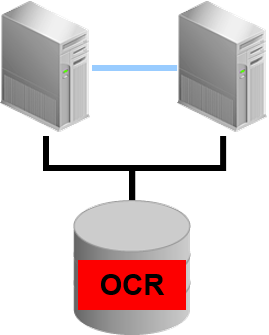
Oracle Cluster Registry
- 利用CRS 堆,以及 Oracle 数据库
共享磁盘上的注册表
–保持CRS 资源、CSS、EVM的结构、以及现在的状态
–保持CRS 堆的设定参数
- 如果OCR被破坏的话,就无法启动CRS
- OCR无法在ASM 上设置
- RAC 环境下,会自动备份OCR 区域的文件。
CRS获得上述备份需要4小时
- 上述备份并不能获得使用了ocrconfig 命令的OCR区域的理论EXPORT转储。
通过使用ocrconfig -export <file name>”命令,对OCR区域的配置进行变更时,变更前以及变更后都可以获得专家支持,由此就可以处理不可预见的错误了。
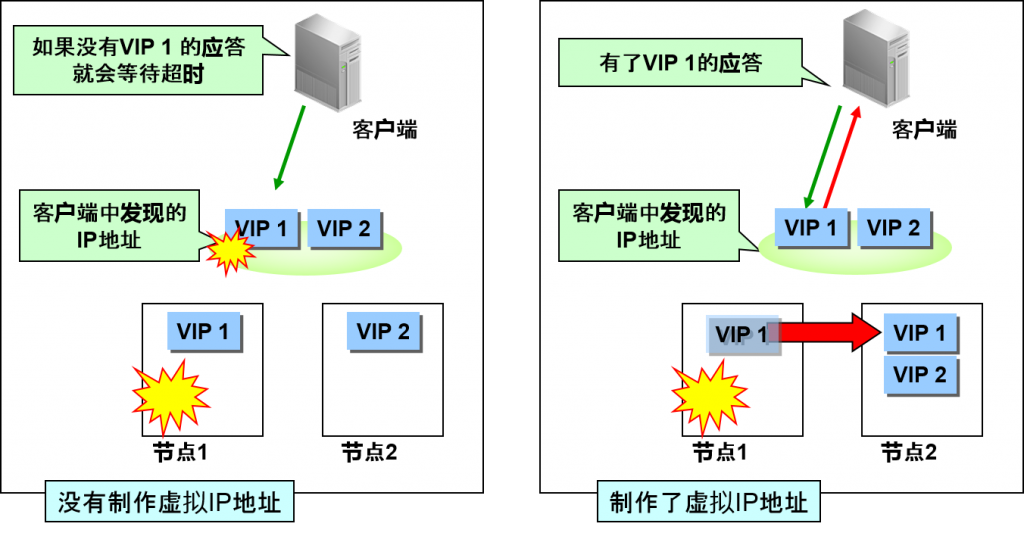
虚拟 IP 地址
节点故障时,就会使用cluster ware的功能,将IP地址移动到正常节点中。
服务器的IP地址一般在客户端开始位置。
客户端在TCP超时之前就会返回应答。
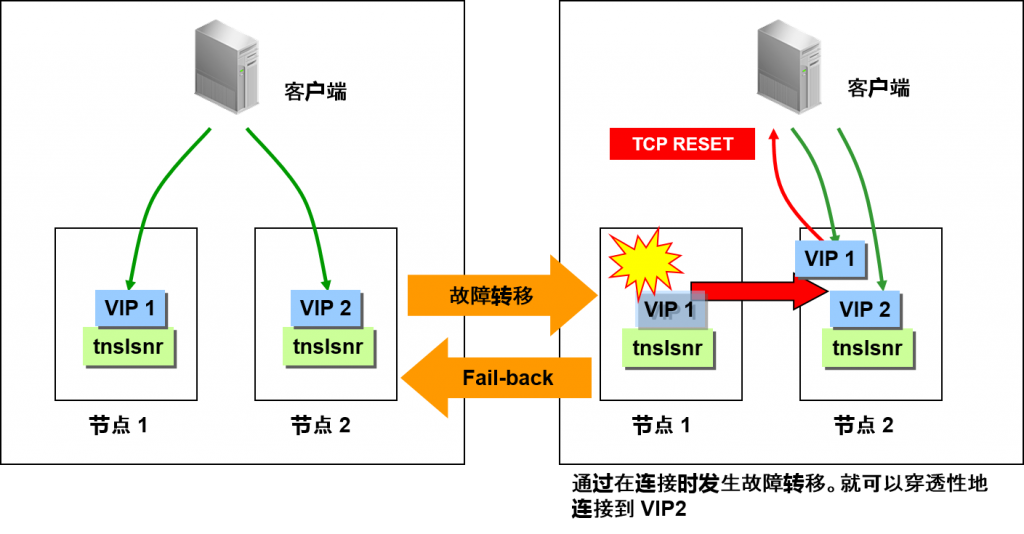
RAC 中的虚拟 IP 地址的结构
RAC 中,文件超载的虚拟IP地址通过切断连接来构造。
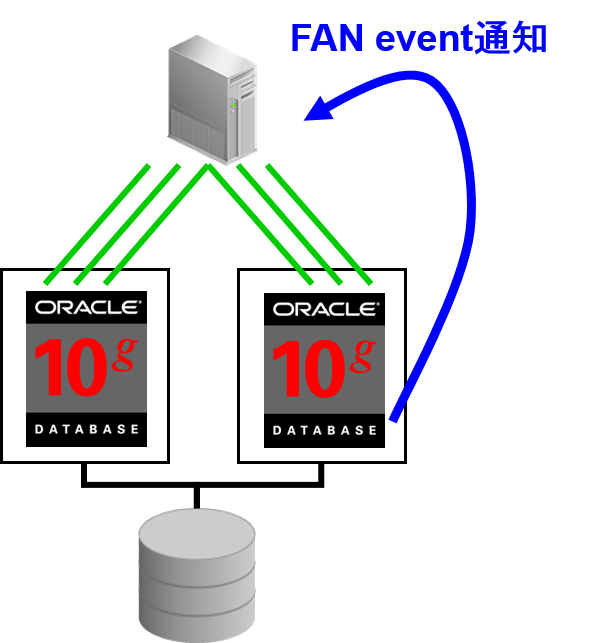
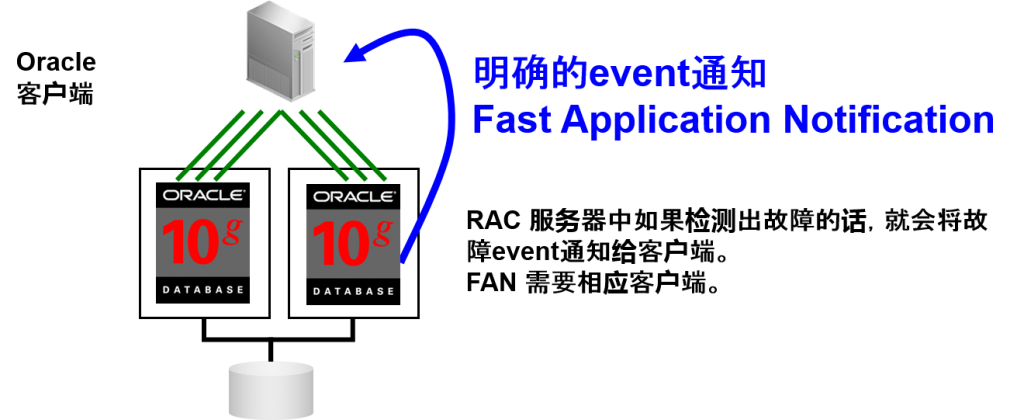
Fast Application Notification
- 向RAC 开始客户端通知event的机制
–长时间连接负载均衡器
–高速连接故障转移
FANevent通知的回路
Oracle Notification Service 经过
客户端为JDBC驱动时
RAC 10g Release 1 仅限这个路径
Oracle Advanced Queuing 经过
客户端为 ODP.NET 或OCI 的情况
在RAC 10g Release 2 中新建
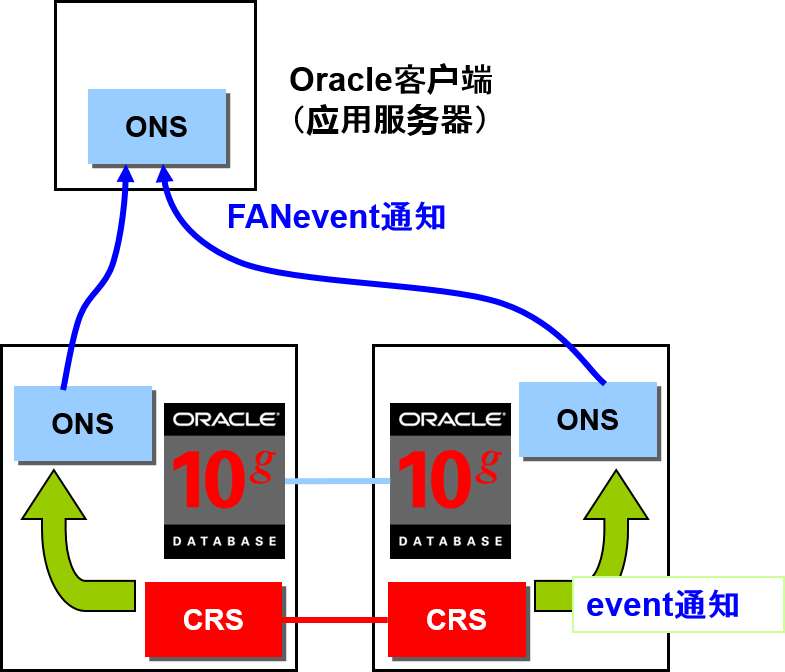
Oracle Notification Services
- Oracle Notification Services
Oracle AS 的OPMN 的subset
ONS守护进程的作用是向远程节点传播信息割
- Oracle Cluster ware
Cluster Ready Services 是故障监视
通知ONS event
Oracle Database 10g 服务 的概念
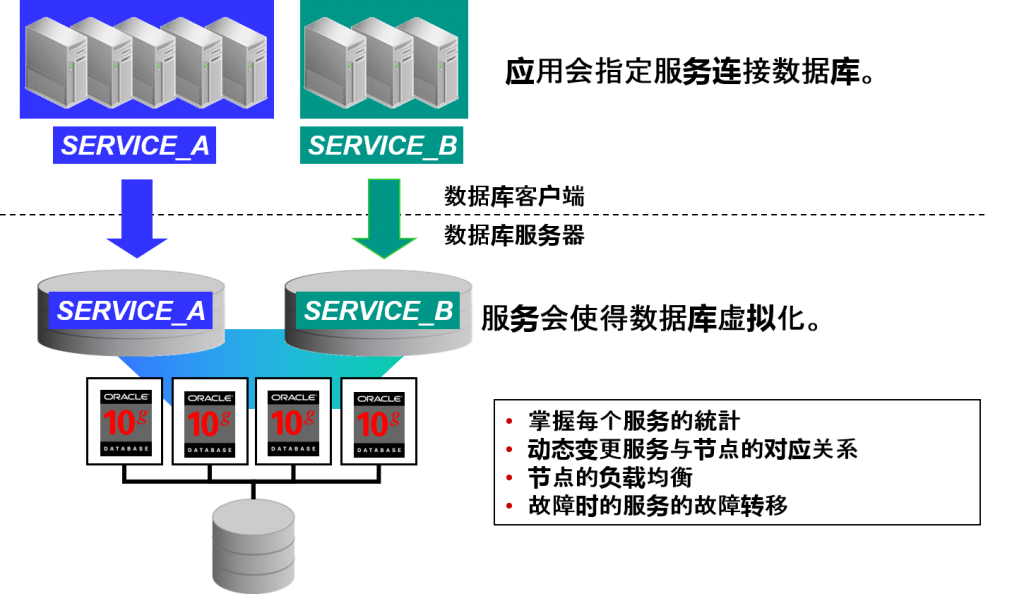
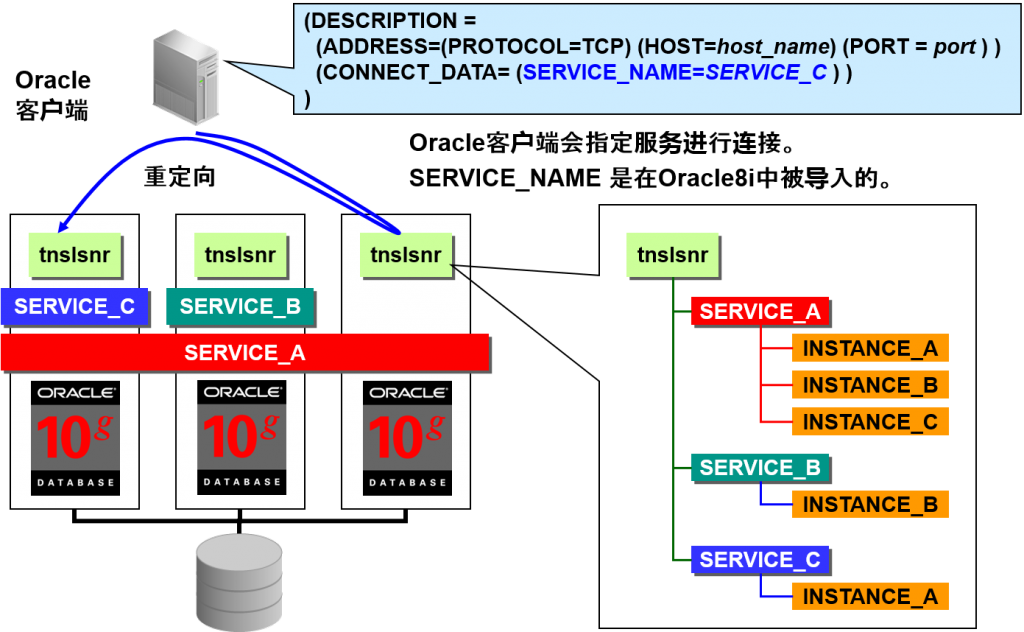
Service服务是什么
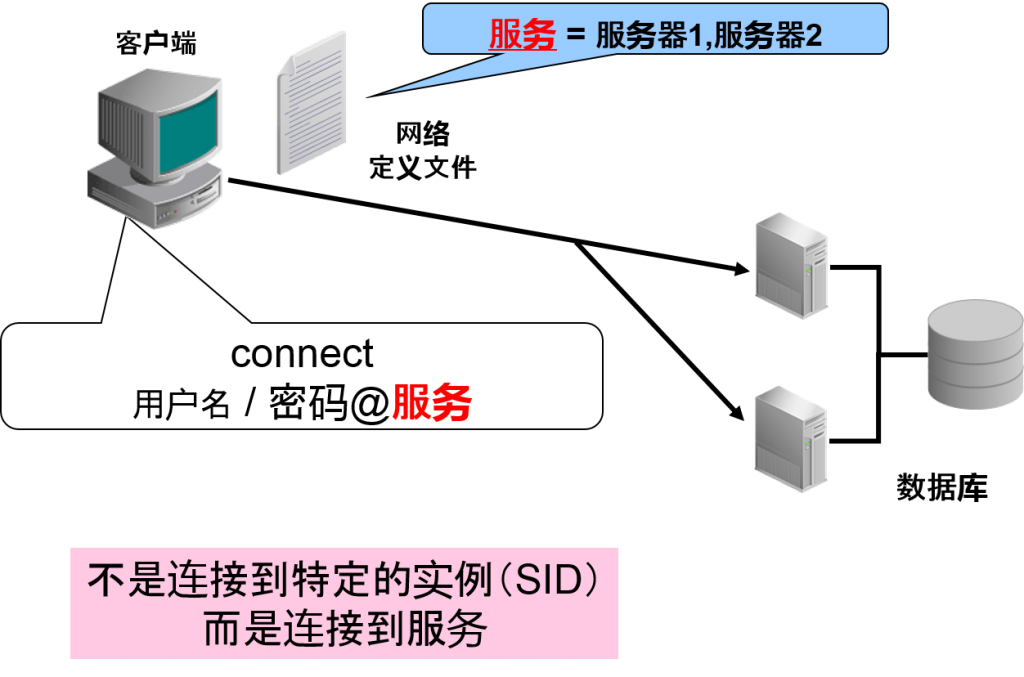
服务与 Oracle 实例
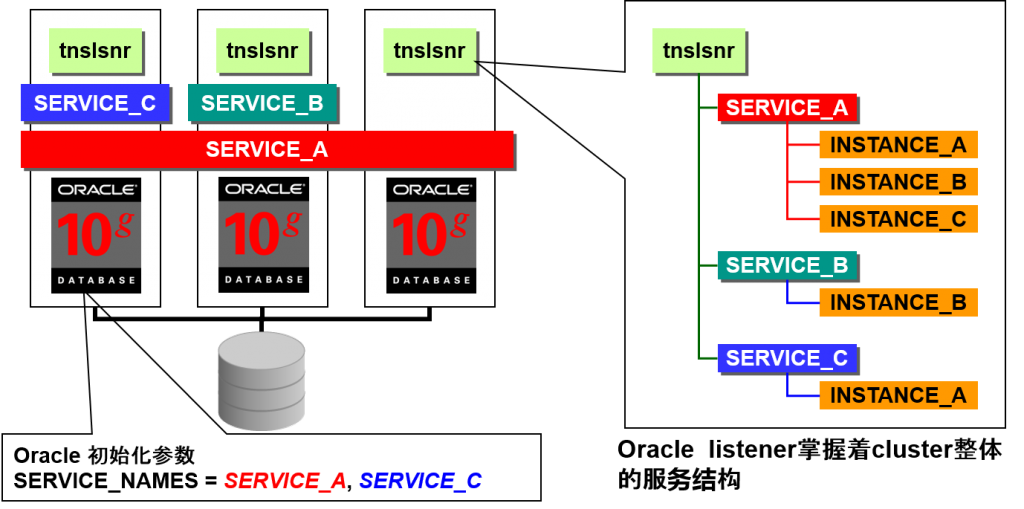
- 服务与 Oracle 实例有关。
- Oracle 实例会在oracle listener中记录自己负责的服务名。
制成服务
- 服务的制成方法
–SRVCTL 命令
–DBCA
- 通过DBCA 制成服务时,会自动制成DB中的 tnsnames.ora 文件
–DB Control
- 可以选择连接负载均衡的policy
- 选择服务
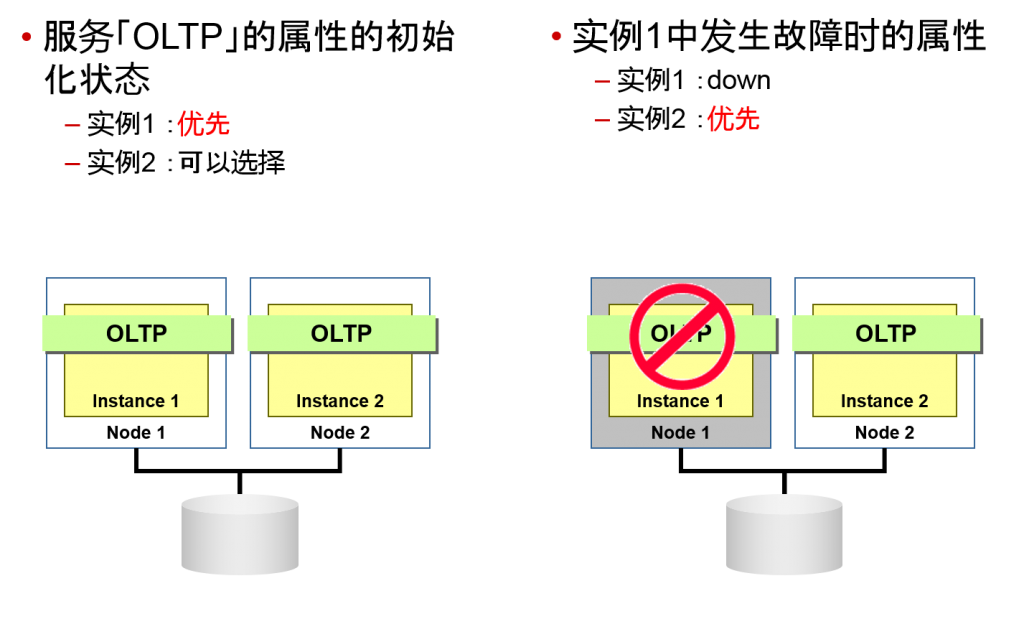
| 优先实例
(Preferred) |
一般而言就是想运行的实例 |
| 可以选择的实例
(Available) |
无法使用优先实例时,就可以执行备份的实例 |
| 未使用
(Not Used) |
这个服务中没有使用到的实例
|
实例列表
- 各自的服务对于cluster内的所有的
实例都有着以下属性
–优先(Preferred)
- 服务基本在这个实例上运行
–可以选择(Available)
- 优先实例中发生故障时,服务就会将故障转移到这个实例中
–未使用(Not Used)
- 服务没有在这个实例运行
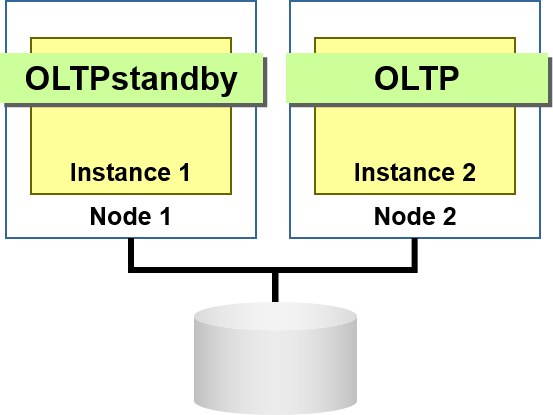
- 不仅可以变更应用、终止现有服务,甚至可以重新架构现有服务
- 通过对服务增减负荷,可以灵活变更提供服务的实例数
根据时间段不同,可以根据负荷量重新架构
在cluster中追加了节点的情况
- 实例1开始恢复时的属性
–实例1 :可以选择
–实例2 :优先
网络设置
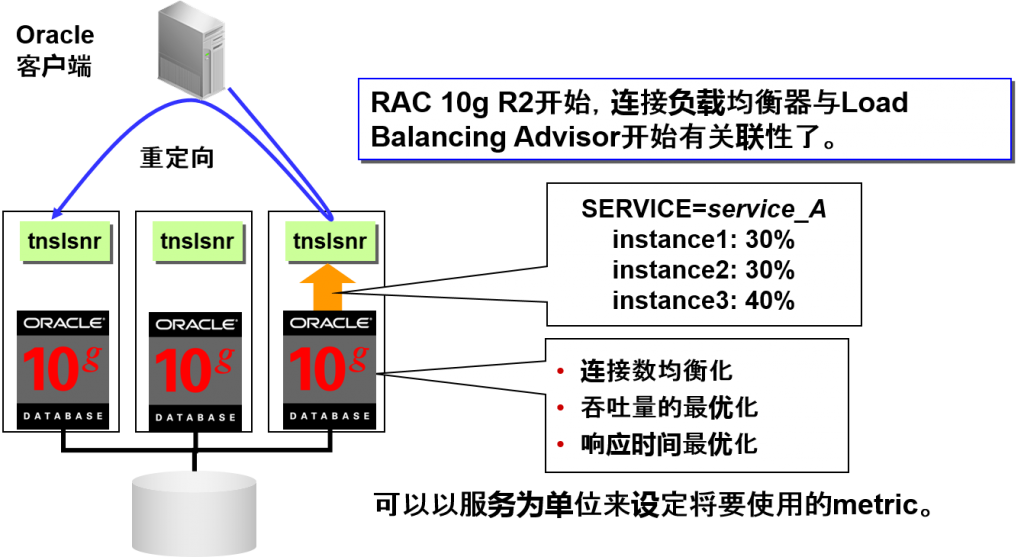
- 负载均衡
DB服务器的连接的負荷分散
连接到listener时,会进行自动均衡
- 故障转移
发生故障时,切换新建/现有会话的生存节点
负载均衡
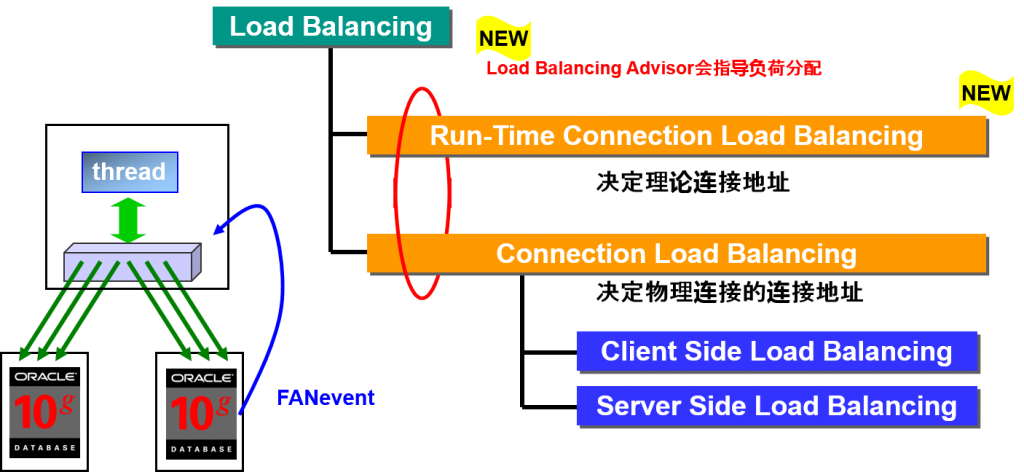
连接负载均衡器
Connection Load Balancing
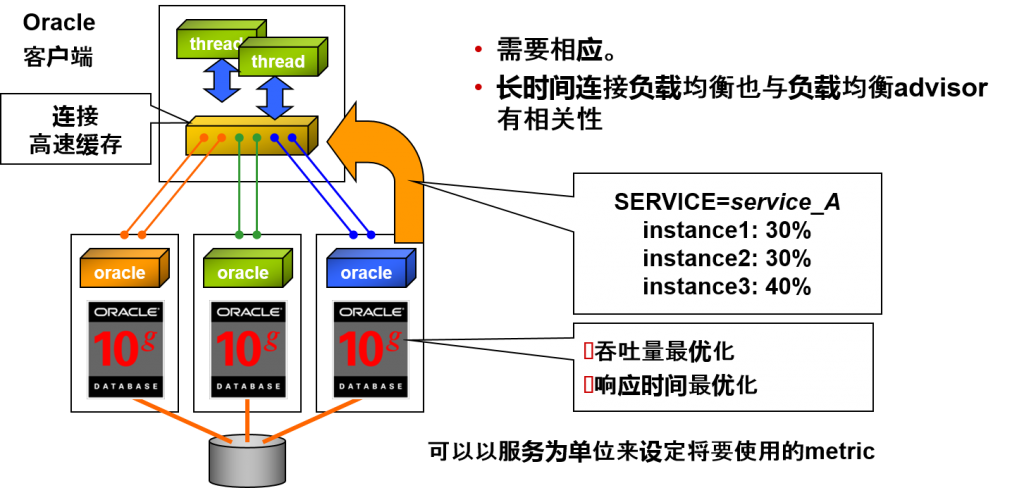
在每个服务中动态指导建立新建连接的比例。
- 觉得到底连接到哪个实例中
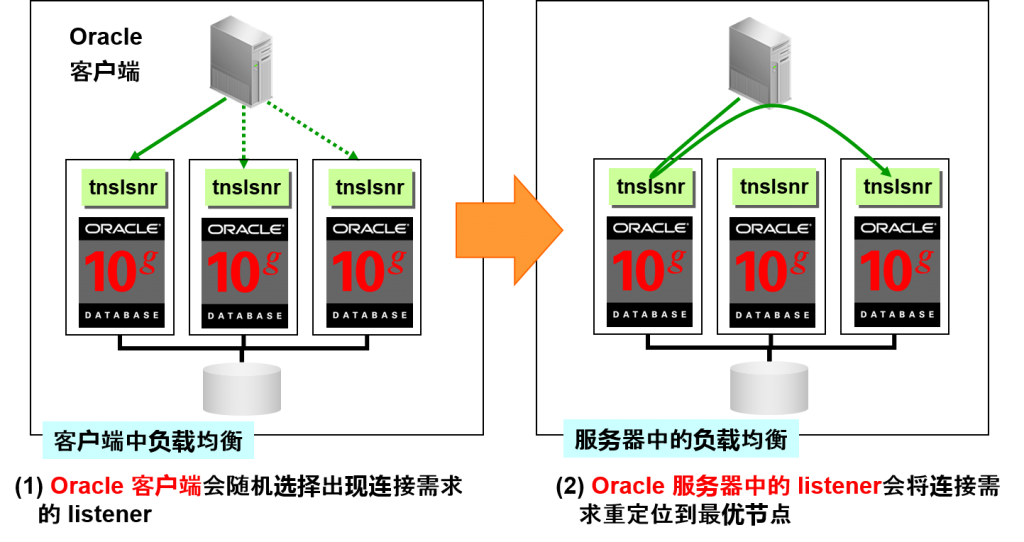
客户端中的负载均衡的设定
这是Oracle客户端的连接描述符的设定

服务器中的负载均衡的设定
通过设定LOCAL_ listener 与REMOTE_ listener ,可以掌握Oracle listener 及cluster整体的服务结构。
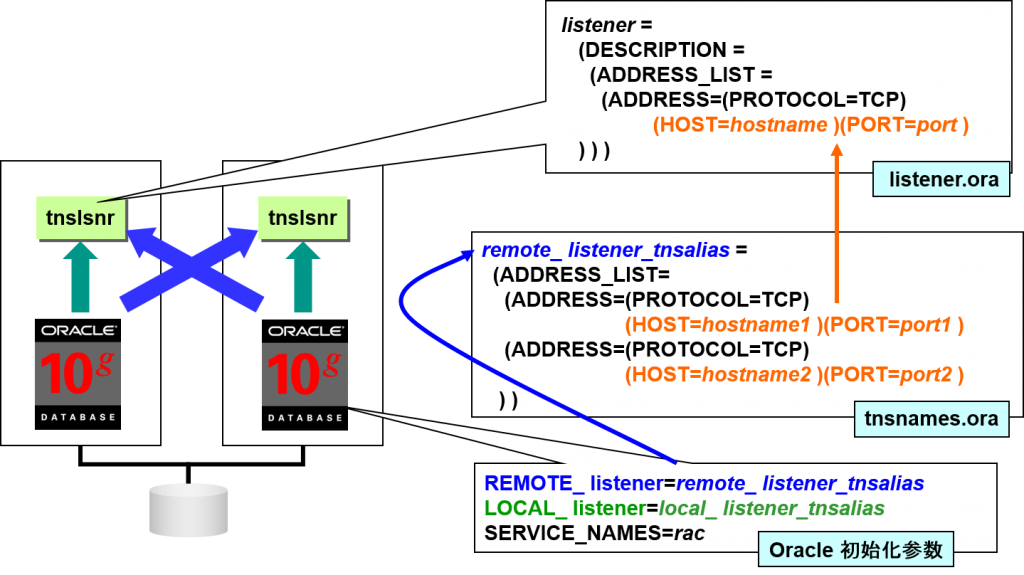
REMOTE_ listener 中会列举cluster整体的 Oracle listener。
长时间连接负载均衡
Run-Time Connection Load Balancing
动态指导分配各个每个服务中的,转移到应用中的线程的,建立完成的连接高速缓存。
故障转移
- 提供多个连接故障转移
- 确立连接时的故障转移
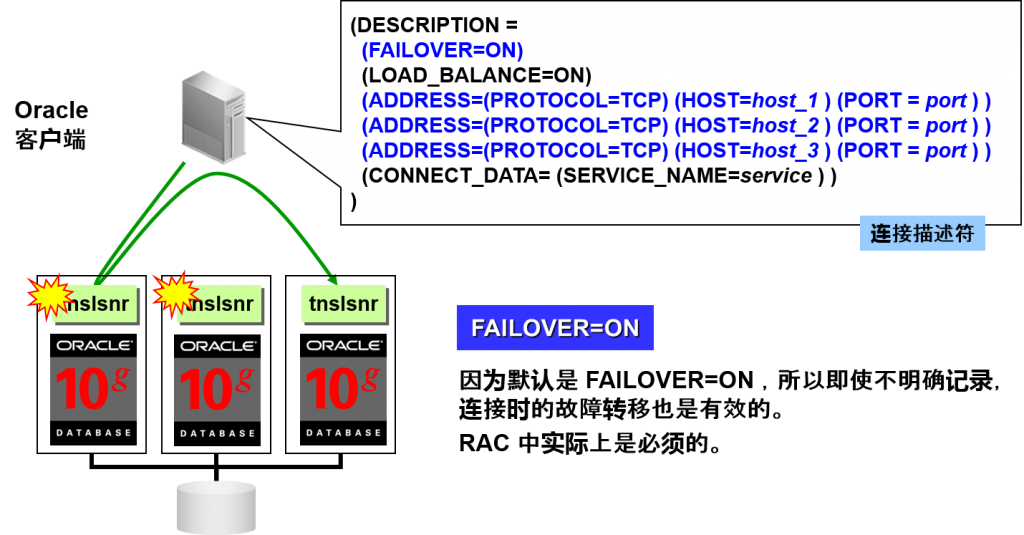
–Connection Time Failover(CTF)
连接时的故障转移
- 对建立Oracle 连接时产生的故障进行故障转移
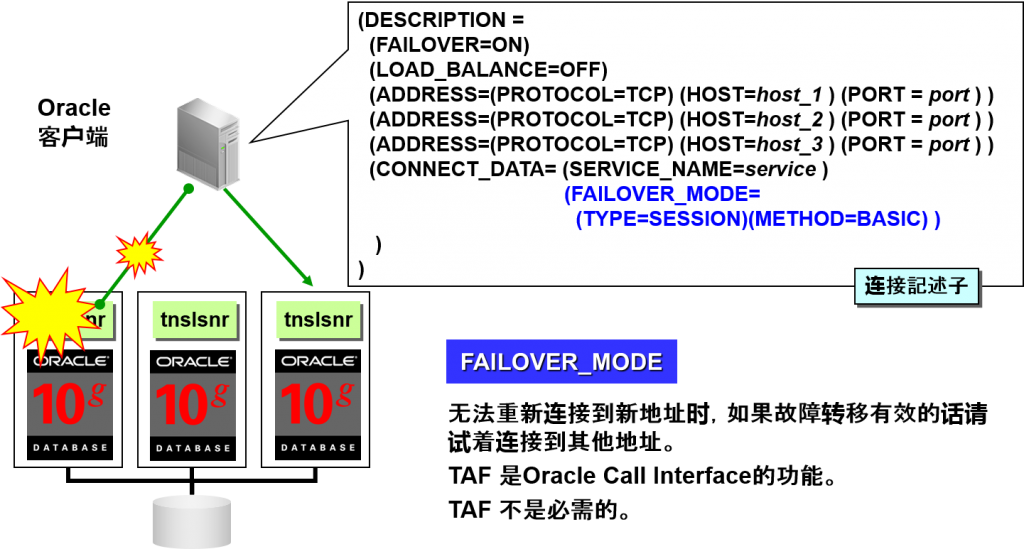
- 连接中的故障转移
–Transparent Application Failover(TAF)
穿透性的应用故障转移
- 对于建立完成的 Oracle连接故障 进行故障转移
–Fast Connection Failover(FCF)
高速连接时故障转移
- 连接池中,检测到RAC故障时,将无效的连接清除,进行故障转移
通过Oracle 进行的连接故障转移
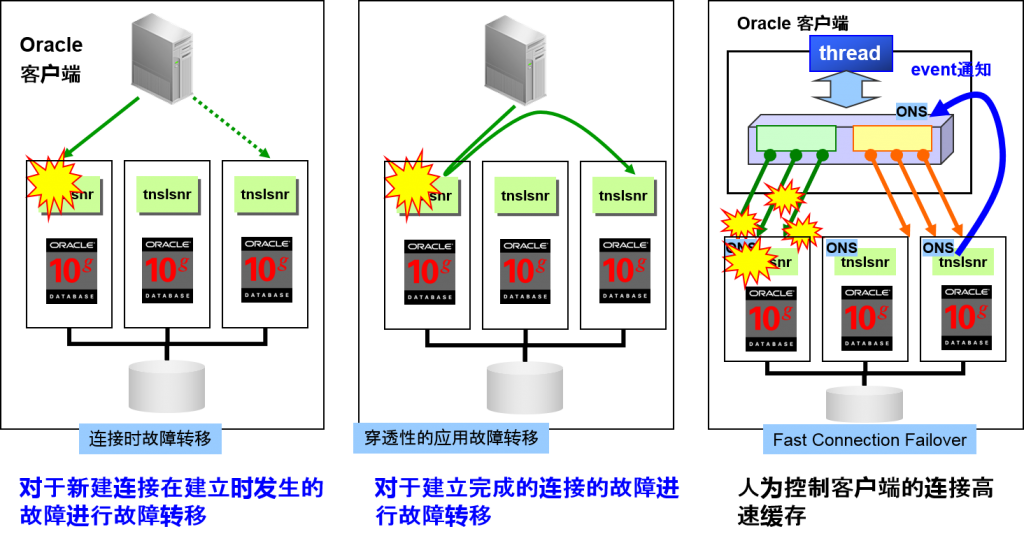
连接时故障转移
新建连接建立失败是,先试着执行其他连接地址
穿透性的应用故障转移
对于建立完成的连接被切断的情况,请试着重新连接
高速连接故障转移
人为控制客户端的连接高速缓存。
在TCP 超时之前,就会清除连接。
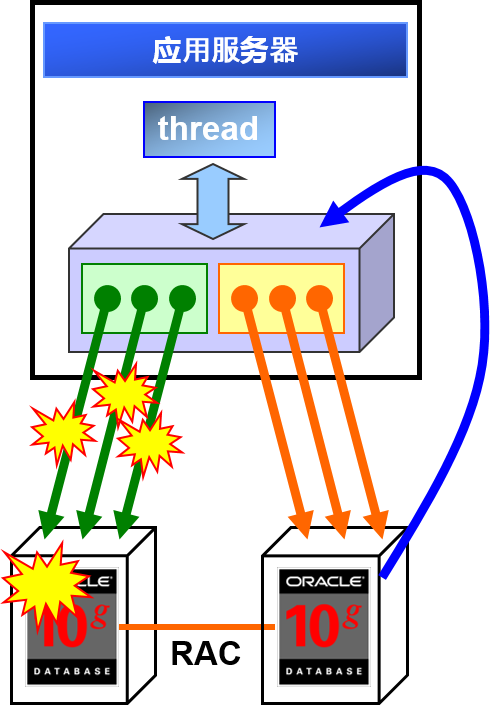
Fast Connection Failover
- 与RAC 连接,控制连接高速缓存
- DOWN event (终止的通知)
关闭相关物理连接
防止连接高速缓存返回无效连接
- UP event (启动的通知)
制成物理连接
在实例启动时自动处理
※只有JDBC驱动的FCF可以处理UPevent。ODP.NET与OCI没有对应关系。
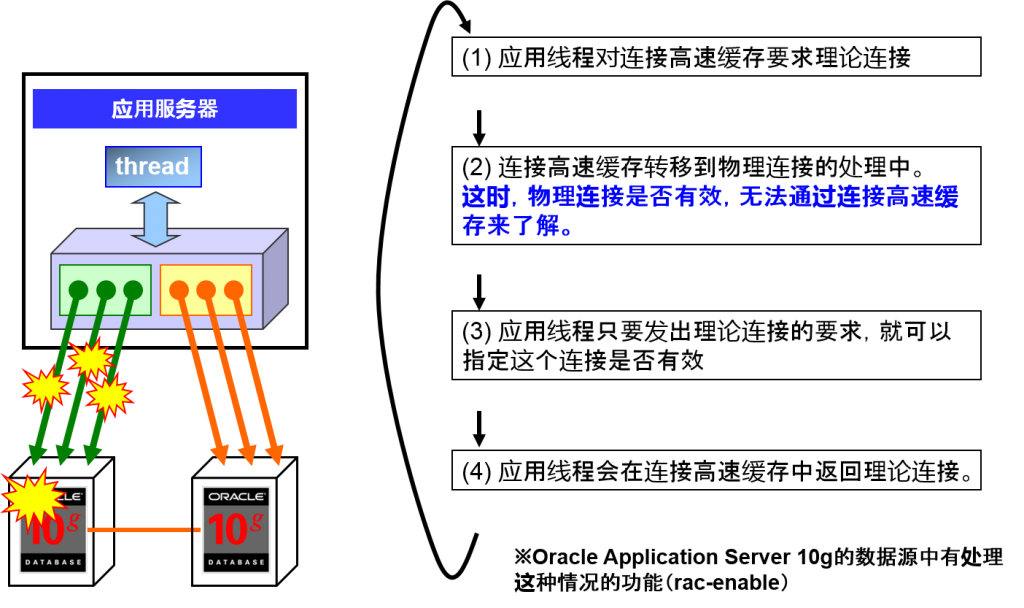
没有Fast Connection Failover 的情况
也有从连接高速缓存中取出无效连接的情况。
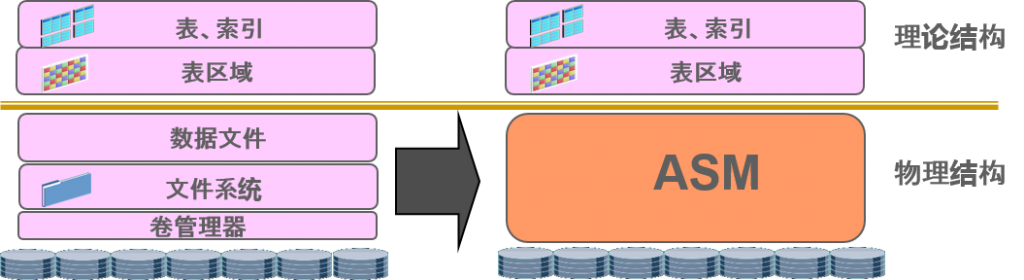
Automatic Storage Management
Oracle专用的存储管理部件需要同时兼顾管理方便以及性能
- Automatic Storage Management (ASM)
–Oracle专用卷管理器
–通过对Oracle相关的大部分文件,执行最合适的多重化以及Striping进行储存
–可以通过EM管理
- ASM的优点
不需要文件系统以及管理数据文件
通过直接访问磁盘驱动,减少过载
可以对所有磁盘驱动都进行监视调优
所有的存储环境中,共通的功能管理性
根据用途不同,灵活选择Striping以及长度

Comment