
介绍
2个月前,我写了一篇关于您如何追尾Oplog的文章同样在分片群集上,并过滤掉从balancer process中产生的内部插入和删除。
它出版后,我收到了更多关于这个话题的反馈,指出两种scenarios目前在需要OPLOG追尾的应用仍有问题。一个还适用于非分片集群,二是仍是分片相关的问题。两者或许都比第一篇博客文章讨论的模糊,但还是很真实的问题。
故障切换 failover 和数据回滚
第一个问题的出现是由于故障切换failover。比方说你从一个主节点追尾OPLOG,其中遇到一些网络问题,这将导致另一个节点当选为新的主节点,而旧的主节点最终下台。在这种情况下,可能的是该process追尾OPLOG会读取到一些事件尚未被实际复制到另一个节点。然后,当一个新的主节点已经被选出,这些事件不是实际的数据库的当前状态的一部分。从本质上讲,他们从来没有发生过 – 但是追尾OPLOG的process认为他们做了。
(请注意,当旧的主节点在某些时候要重新加入副本集,它首先必须数据回滚事件,这些事件是并未被复制,也不再是数据库的一部分。)
下面的图片说明了事件的顺序。需要注意的是事件D和E并不存在于数据库最终状态,但Observer认为他们存在。
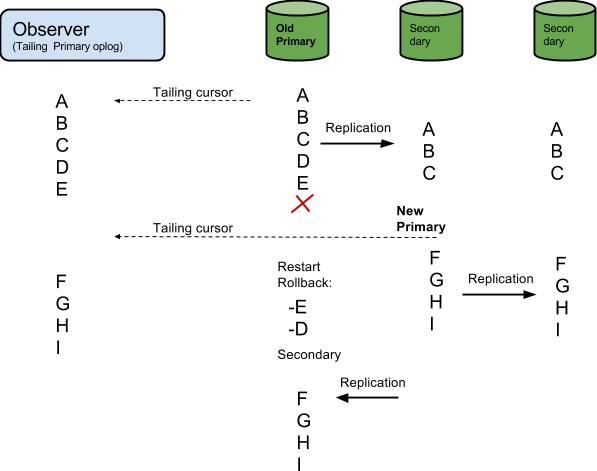
幸运的是,在故障切换failover和数据回滚的情况下,有几种解决方案,你可以用它来得到一个正确的读取:
一个好消息是,在故障切换failover的情况下,他们会强迫任何客户端连接被关闭,因此客户必须重新连接并重新发现在副本集中的主节点。作为这一过程的一部分,我们也可以做一些事情,以防止上述不必要的麻烦。
一个简单的解决方案,可能会适用于像Meteor的应用,你只需要重新加载数据模型使应用程序重新启动,然后像往常一样在新的主节点追尾OPLOG。唯一需要注意的是,这会不会导致剧增的查询命令,当所有的应用程序突然需要发出大量的查询来重新加载它们的数据模型。我能想到各种方法来缓解,但是这超出这个帖子的讨论范围。
ETL和复制系统通常将必须复制一些包含事件的内部缓冲器buffer。在许多情况下,它可能只需简单地停止复制,检查在新的主节点的OPLOG的缓冲区,如果需要的话,删除已经消失在故障切换failover的任何operation。如果事件消失数(即数据回滚)比在ETL /复制工具的缓冲器存在的东西数量大,那么它应该因为一个error就停止了,让用户修复并重新启动这个情况。注意可以增加缓冲器用来最小化这事件发生的概率。
最后一个完全不同的方法是追尾在一个副本集中多数甚至所有节点的oplogs。由于成对的TS&H字段独特地标识每个事务,它可以很简单地从应用侧的每个OPLOG得到结果,使“输出”尾部线程是已经至少由大部分的MongoDB节点返回的事件。在这种方法中,你并不需要关心一个节点是主节点或备份节点,你只要追尾OPLOG的所有节点和由多数oplogs返回并被认为是有效的所有事件。如果您收到没有在大多数oplogs存在的事件,这些事件会被跳过并丢弃。
在MongoDB中,我们计划通过追尾OPLOG的方式来提高的用户接收更改通知的体验。一个改进是封装的一个或一些上述技术使它们能通过一个库(如MongoDB的连接器)被透明地处理。另一个未来的解决方案将是SERVER-18022,它允许OPLOG从反映群集的多数行为状态的快照中读取数据。
分片集群中孤立文档的更新
在一个分片群集中,孤立文件是存在于一个数据库节点上的文件,即使根据分片密钥和当前chunk分配,文档在这个时间点上真的应该在另一个节点。 (当前chunk分配存储在配置服务器上,在config.chunks集合)。
即使孤立文件(根据其本身的定义)不应该存在的,它们可以出现并且是无害的。例如,它们可以因一个中断chunk迁移出现:文件被插入到一个新的分片,但由于某些原因,并没有从旧的中被删除。
在大多数情况下,MongoDB会正确处理它们的存在。例如,如果您通过mongos连接到分片数据库,并做了find(),那么mongod process会从结果集中过滤掉任何它可能遇到的孤立文件。 (可能同一个文件会由其他的mongod送回,因为根据当前chunk的分布,它的存在是有效的。)在另一方面,如果直接连接到副本集,做同样的find(),您将能够看到孤立文件在那里。你甚至可以在节点中insert()一个超出范围的分片键值的文件,为自己人为地创造一个孤立文档。
有一个情况,当孤立文档不幸地暂时没有被检测并过滤出就是一个多项更新:
db.people.update(
{ age: { $gte: 65 } },
{ $set: { seniorCitizen: true } },
{ multi: true }
)
如果这样的多项更新击中孤立文档,孤儿文件将被更新,更新将被记录在OPLOG并复制。因此,如果你在一个分片集群追尾OPLOG,你可以看到这些更新,从一个集群范围的角度被认为是ghost的更新 – 他们从来没有发生过,应该是对外不可见的。
遗憾的是,我不知道有任何通用的和可靠的方法来解决此问题。对于一些应用可以最小化孤立文件曾经出现的风险,通过关闭balancer process和手动分配chunks:
关掉balancer process。
最好是在插入数据之前在一个空的collection,手动拆分和分配chunks。
为了增加保障,定期运行cleanupOrphaned,或者当你觉得有可能要孤立文件的某处。 (例如,如果您手动移动一些chunks。)
从根本上说,这是一个在MongoDB的代码库需要解决的问题。一个多项更新应检测和跳过孤立文件。至于变更通知notification use cases 以改善用户体验的部分,我们也必须以某种方式解决这个问题。 (解决方案正在讨论,但我不会赘述在这篇文章中,我的重点是更多的是目前可以适用的解决方案或解决方法。)

Comment