- Cell 升级介绍
- Cell 补丁内容
- Cell 磁盘配置
- Cell 补丁管理器
- Cell 升级指南
在这个讲义中,所有与cell打补丁有关的各项具体话题都会讲到。 我们选择最佳的演讲顺序,以确保你能更好地理解。
因此,我们从总体介绍介绍开始,设置基线。从这里开始,我们将讨论更多细节,开始解释在cell补丁中究竟有些什么。
接下来,我们对磁盘配置详细讨论,因为这在回滚过程中发挥核心作用。在操作补丁管理器及谈论最佳实践之前,我们将讨论一般补丁流。
- Cell 补丁准备
- Cell 补丁应用一个补丁
- Cell 补丁阶段和时序
- 回滚一个Cell 补丁
- Cell 补丁 – 参考资料
- Cell 补丁 – 案例
- Cell 补丁故障排除
- Cell 补丁 – 收集数据及获取帮助
在短暂的休息后,我们将继续讨论,当你应用补丁,在它被回滚时会发生什么。
我们将讨论补丁的时序,对性能的影响。预计很多人对故障排除会有兴趣。
我们将提及获取正确的日志和cell追踪的位置,以及从哪里获得更多帮助。
最后一个主题是互动的。我们会讨论cell打补丁活动的10个失败案例,以及其解决方案。
注:由于该日程/方法,一些项目可能重叠
Cell 升级简介

简介 – 存储服务器升级
- 单个补丁下载
–同一补丁适用于所有硬件
–捆绑在QFSDP
–Exadata软件,OS, ILOM,固件
–README 和支持Note
# imageinfo -ver
Active image version: 11.2.2.3.2.110520
- 11.2.2.4.2 及更早版本包括数据库服务器的最小(便利) 包
| 组件 | 补丁 发行频率 |
| Exadata 存储服务器 | 每季度 |
好吧 – 快速回顾cell升级,往往也被称为存储服务器升级。有一个补丁,适用于甲骨文迄今发布的所有类型的cell,甚至v1。
当然,这个补丁被捆绑在新的QFSDP。我们打补丁的项目在OS,ILOM和固件的级别。如果你想知道系统之前在运行什么版本,你可以使用imagehistory。
imageinfo告诉你当前版以及你可以(或不能)回滚到的版本。当应用补丁,仔细阅读README以及引用的注释总是很重要的。
cell补丁带有一个所谓的最小包。这从11231开始就不会是这样了。最小包将在其他章节中讨论。
简介 – 发行编号
[root]# imageinfo Kernel version: 2.6.18-238.12.2.0.2.el5 #1 SMP Tue Jun 28 05:21:19 EDT 2011 x86_64 Cell version: OSS_11.2.2.4.2_LINUX.X64_111221 Cell rpm version: cell-11.2.2.4.2_LINUX.X64_111221-1 Active image version: 11.2.2.4.2.111221 Active image activated: 2012-01-26 06:10:32 -0600 Active image status: success Active system partition on device: /dev/md5 Active software partition on device: /dev/md7
演讲人注意:这是用于解释下一个幻灯片的imageinfo的幻灯片。
这张幻灯片也可连接下一个话题,不同的版本如下:
Cell版本
RPM版本
镜像版本
Imageinfo的版本相关信息 (1/2)
| 字段 | 描述 |
| Kernel Version | Cell的操作系统内核版本 |
| Cell Version | CellCLI 工具报告的发行版本 |
| Cell rpm version | CellCLI 工具报告的 cell 软件版本或 cell rpm 版本 |
| Active image version | cell镜像整体的主发布版本操作系统,核心Oracle Exadata 存储服务器软件(cell rpm)以及cell最主要部件的固件级别的发布的特定组合。cell
补丁通常会更新此信息。版本的前五个独立区域匹配Oracle产品版本识别的标准方法。最后一个区域正是发行版的版本号。它相当于创建日期的YYMMDD格式。 |
你能看到有一些组件,在理论上可以有不同的版本号。
我最后一次看到这些值不同是在测试或在SSC的beta过程中。通常这些数字是一致的。
| 字段 | 描述 |
| Active image activated | 当cell上的镜像被认为完成,无论成功或不成功,日期戳以UTC格式显示。cell 补丁以更新时间戳表示cell被打了补丁。 |
| Active image activated | 基于一组成功或失败的自检和配置操作的cell镜像的状态,统称为验证。如果该状态是未定义的,空的或失败,就要检查在/var/log/cellos目录这个的不同验证日志以确定状态的原因。 |
Exadata存储服务器升级
- 补丁包含所有固件和cell软件 (包括 OS)
- 在Exadata cell上不允许其他软件
- 补丁管理器安装和回滚
–一个调用为所有cell打补丁
–回滚到成功安装最近的版本
–非滚动和滚动(低负载)
| 方法 | 停机时间 | 补丁安装时间 |
| 滚动 | 无 | 每个cell最多2个小时 |
| 非滚动 | 总共最多2个小时 | 总共最多2个小时 |
同一时间进行所有,一次一个,或滚动
- 滚动需要 11.2.0.1 DB_BP6, GI_BP4 或 11.2.0.2 或更高
我们之前已经看到的另一张幻灯片。这是正确的,但有些附加信息。
这张幻灯片是在这里再次强调cell比除了磁盘管理或初始网络和ASR配置的其他东西“offlimits超出限制”。
补丁可以更新系统,所以任何人为更改都会丢失。
补丁由补丁管理器安装,这将在后面更详细谈到。
对我们看到的平均时间快速说明,但要理解确切时间总是取决于在补丁中有什么和滚动升级的情况:如果磁盘可以被停用。
请注意,我们从11201 BP6/ GIBP4开始支持滚动补丁升级
简介 – 下载一个补丁
从哪里下载补丁,例如 11.2.2.4.2:
- 作为补丁外部 QFSDP supporthtml.oracle.com 通过 13551280
- 作为补丁外部单个补丁通过 13513611
- 作为补丁内部通过 support.us.oracle.com
- 作为补丁内部通过 aru.us.oracle.com
这张幻灯片的目的是给一个例子,说明ACS现场工程师可以在哪里下载补丁。
这张幻灯片很重要的,我们不应该互相复制补丁。
从ARU下载补丁将确保你在补丁被拉回时得到通知。
Cell 补丁内容
- 固件
- Infiniband HCA
- Disk 控制器
- ILOM + BIOS
- 闪存卡
- SAS 背板*
- 磁盘固件
- 操作系统
- 每个cell补丁可能更新整个操作系统
- Cell 人家
- JDK
- Cell 服务器软件(bin)
- 工具:例如: ibdiagnet / ibnetdiscover / Checkhwnfwprofile
除了软件和固件更新外,配置文件也能被补丁更新。
这里的思考方法:固件:OS,Cell软件
正如前面所说,cell补丁能升级cell软件,固件,工具和操作系统。
正如在幻灯片中,cell软件可以是JDK或cell服务器二进制文件。
固件可应用于HCA,控制器,ILOM,Flash和BIOS。
进行验证,故障排除的工具(不论是否打包)
操作系统可以通过cell补丁更新,例如新的二进制文件或新的内核。
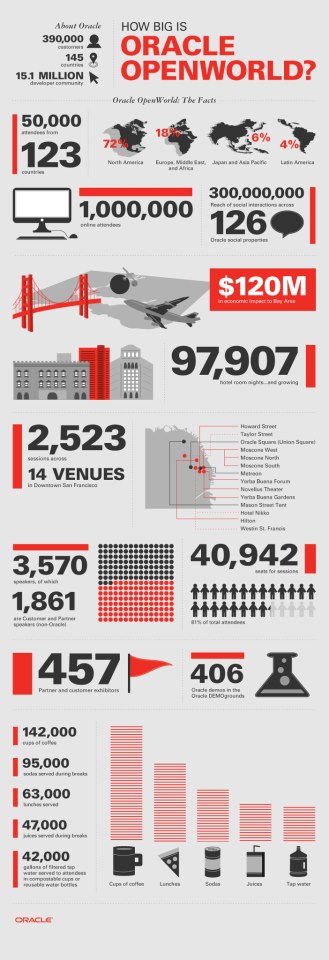
补丁内容–示例
补丁会给你带来什么版本,参见README
参见内部Exadata数据库服务器硬件固件和补丁历史 (Doc ID 1358327.1)
不是每个补丁会更新所有部件,有时会有很长一段时间没有更新,例如11.2.2.4.0/ 1/2
磁盘固件对所有磁盘并不一定是相同的。我们也支持同一cell中有不同的磁盘,只要它们具有相同的特性。
CheckHWnFWProfile (1/2)
该工具检查系统是否满足所需的硬件和固件的要求,并报告任何不匹配。
CheckHWnFWProfile可以用于获取最新软件版本号以及手动验证。
/opt/oracle.SupportTools/CheckHWnFWProfile
-d: will display details of installed hardware and firmware versions
-s: will display details of expected hardware and firmware versions
-c: will display details of what is different between installed and expected
–U 标志被用来更新固件和ILOM。
有下列选项:
-strict:验证硬件配置文件是否正确。该命令检查CPU的类型和数量,组件固件,等等。
-U 如果配置文件检查失败,且固件需要刷新,
该命令必须在单一行中输入。运行该命令关闭系统后,重置ILOM,并在启动系统前等待10分钟。
任何固件更新是作为一个Oracle数据库/ OEL操作系统补丁被发生和分布的,因为Exadata具有内置的脚本(/opt/oracle.cellos/CheckHWnFWProfile)检查并将固件re-flash至
OS补丁中发布的Exadata特定版本。
在Exadata存储服务器(cell)中合格的版本是很重要的,它包含客户数据,以便re-flashing在启动时是自动的,如果有任何
不一致或错误/更换的修正部分。所有flash它们的固件镜像和工具在OS文件系统中本地可用,并分布在镜像或Oracle补丁。
CheckHWnFWProfile (2/2)
CheckHWnFWProfile –c :
- “strict”: 验证硬件配置文件是否正确。
- 该命令检查CPU类型和数量,组件工具,等等
- “loose”: 检查将不检查相同的驱动器和相同的驱动器固件
- 命令“alter cell validate configuration”是在cell执行CheckHWnFWProfile的另一种方法。相当于:/opt/oracle.SupportTools/CheckHWnFWProfile -c ms_loose‘strick’ 是默认的
有下列选项:
-strict:验证硬件配置文件是否正确。该命令检查CPU的类型和数量,组件固件,等等。
-U 如果配置文件检查失败,且固件需要刷新,
该命令必须在单一行中输入。运行该命令关闭系统后,重置ILOM,并在启动系统前等待10分钟。
任何固件更新是作为一个Oracle数据库/ OEL操作系统补丁被发生和分布的,因为Exadata具有内置的脚本(/opt/oracle.cellos/CheckHWnFWProfile)检查并将固件re-flash至
OS补丁中发布的Exadata特定版本。
在Exadata存储服务器(cell)中合格的版本是很重要的,它包含客户数据,以便re-flashing在启动时是自动的,如果有任何
不一致或错误/更换的修正部分。所有flash它们的固件镜像和工具在OS文件系统中本地可用,并分布在镜像或Oracle补丁。
Cell 磁盘配置
回滚cell补丁的过程是,有多个分区且保存一个旧(工作)分区来回滚,以防新分区安装失败。正是因为这个原因,我们现在要处理cell磁盘配置现。
磁盘配置 – 存储设备
- 12 个磁盘
–Cell 磁盘 0 和 1:
- ‘最后的’ 29GB 用于磁盘分区
- 剩余空间用于存放数据
–Cell 磁盘 2 到 11:
- Celldisk data only
- 16 个Flash FMODs
- CELLBOOT USB (4GB) (X4275 and X4275M2)
- 从11.2.2.4.2开始支持3TB 磁盘驱动器
11.2.2.4.2 also supports 3TB drives but it was not documented at that time since it was not ready for public announcement.
预计所有人都知道:一个cell有12个磁盘。
前两个磁盘有一个29GB分区,用于操作系统。
剩下的就用于数据和RECO。
接下来有16闪存模块和cellboot USB。
11.2.2.4.2也支持3TB驱动器,但那时并没有被记录,因为还没作好公开宣布的准备。
布局前两个磁盘
fdisk(不要使用它)。预计它在3TB驱动器运作不太好。如果你想显示它,使用分开的例子。
所以,如果你看一下磁盘0或1上的分区,它们在2号及以上磁盘上看上去不同。
你可以看到有3个正常分区和第4个扩展分区。
在扩展分区中的一些分区被用于cellOS和cell软件
例如:在磁盘0的分区是以其他系统磁盘(盘1)配置的RAID1
Raid 配置和状态 示例 “/boot” (md4)
使用 “mdadm –Q” 来检查raid 配置和状态
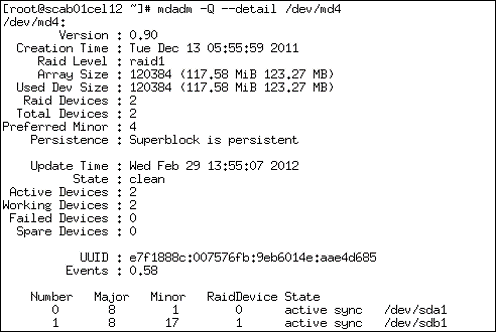
mdadm命令输出提供桥梁,显示RAID状态。
检查RAID配置的健康作为补丁管理的一部分被执行为。
磁盘配置– 系统分区
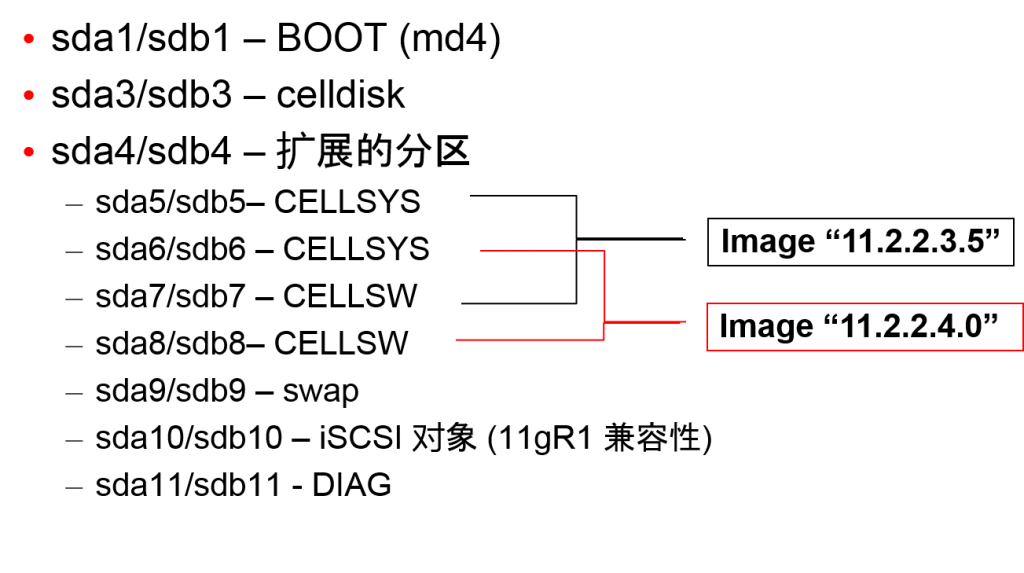
注:所有这些分区也将被列在iostat中(OS watcher)。因此知道什么设备用于什么目的是很重要的。
注意布局在不同版本有变化
这是SDA,我们在第二个磁盘也有相同的sdb。
raid设备在RAID 1的sda和sdb创建。
当raid设备被打了补丁,它们将被交换。
例如:当前的活跃镜像可以在MD6(系统)和MD8(软件),非活跃镜像在MD5(系统)和MD7(软件)
BOOT有内核和驱动程序来加4载OS;挂载mounted on/启动
扩展分区是传统的PC创建附加分区所需
“/”是在CELLSYS挂载
“/opt/oracle”是在CELLSW挂载
“/var/log/oracle”是在DIAG挂载
Sda10是从11gR1中的继承的,其中需要有iSCSI驱动,因为OCR /投票是不在ASM中。
在任何时候,我们有sda5/7或sda6/8处于活跃
重新成像将重新创建所有分区;打补丁将替换sda5/7和SDA6/8
磁盘配置– IOSTAT (ref)
Raid 设备和活跃分区
Active image version: 11.2.2.4.1.111122 Active image activated: 2011-11-23 06:37:51 -0700 Active image status: success Active system partition on device: /dev/md5 Active software partition on device: /dev/md7 In partition rollback: Impossible Cell boot usb partition: /dev/sdm1 Cell boot usb version: 11.2.2.4.1.111122 Inactive image version: 11.2.2.4.0.110929 Inactive image activated: 2011-11-23 01:46:01 -0700 Inactive image status: success Inactive system partition on device: /dev/md6 Inactive software partition on device: /dev/md8 Boot area has rollback archive for the version: 11.2.2.4.0.110929 Rollback to the inactive partitions: Possible
imageinfo的分区信息 (1/3)
| 字段 | 描述 |
| Active system partition on device
设备上的活跃系统分区 |
Cell操作系统root(/)分区设备。一个典型的成功的cell补丁将cell从活跃的分区切换到非活跃的分区。每个成功的cell补丁保持活跃和非活跃分区之间的cell切换。cell补丁不切换分区的情况很少。
这些是罕见的,被称为分区内补丁。 |
| In Partition Rollback
分区内回滚 |
一些cell 补丁不切换分区。这些是分区内补丁。这个区域表示回滚这样的补丁是否有足够信息。 |
| Cell boot usb partition
Cell 启动 usb 分区 |
Exadata Cell 启动和拯救 USB 分区。 |
分区内回滚只在 11.2.1.2.4 / 11.2.1.2.6中出现。
来自Exadata存储服务器软件用户指南。
因为不是每个人都了解cell磁盘配置,讨论“imageinfo‘的其它信息是有用的:即在什么系统/版本的信息在哪个磁盘可用。如果不讨论,仍有参考价值。
| 字段 | 描述 |
| Cell boot usb version
Cell 启动 usb 版本 |
在启动USB上的软件版本。在健康的cell中,该版本必须与活跃镜像版本行的值相同。 |
| Inactive image version
非活跃镜像版本 |
在最新补丁被应用前的cell版本。 |
| Inactive image activated
非活跃镜像被激活 |
激活非活跃镜像的时间戳。此字段与Active image activated字段类似。 |
| Inactive image status
非活跃镜像状态 |
非活跃镜像的状态。该字段与活跃镜像的状态类似。 |
| Inactive system partition on
device 设备上非活跃系统分区 |
非活跃镜像的root (/) 文件系统分区。 |
| Inactive software partition
on device 设备上非活跃软件分区 |
Oracle Exadata 存储服务器软件文件系统分区, /opt/oracle, 为非活跃镜像。 |
来自Exadata存储服务器软件用户指南。
大多数字段都清楚,这些信息来自存储cell指南和服务,告知人们当前使用的是什么分区以及可以回滚到什么分区。
| 字段 | 描述 |
| Boot area has rollback
archive for version 启动区有版本的回滚存档 |
对于使用非分区内cell补丁被打补丁的cell,这表示是否有适当的备份存档可用于将cell回滚到非活跃镜像版本。这个存档的存在是必要的,但不足以回滚到cell镜像的非活跃版本。 |
| Rollback to inactive
Partition 回滚到非活跃分区 |
对于非分区内打补丁的cell的总结指示器表示回滚是否可以在cell上运行来将它带回cell镜像的非活跃版本。在新的cell中,该字段为空或者其值为undefined。 |
Cell 补丁 – 补丁管理器
补丁管理器 – 简介
补丁管理器 …
- 是一个 shell 脚本
- 编排升级和降级(回滚)
- 一次为一个或多个cell节点打补丁,滚动或非滚动
- 处理 prereq 检查和验证
- 管理补丁分布
- 管理cell 磁盘 (处于) 激活
- 配合重启
补丁 README 和 MOS 笔记可能有影响打补丁问题的具体说明的其他信息。
因此,这总需要被检查。示例:最近更新在 Feb 13 2012 for 11.2.2.4.2
Exadata 存储服务器打补丁
非滚动补丁应用
- 优点
–打补丁总时间最低
–单个磁盘故障无风险
–无重新同步时间
- 缺点
–全部停机总共 2-3 小时
–多个cell上失败的补丁安装
Exadata 存储服务器打补丁
滚动补丁应用

- 优点
–无应用或数据库停机时间
–不会面临多个cell故障
–缺点
- ASM 高冗余以减少出现的磁盘故障
- 每个cell高达2小时
–捆绑补丁要求
“Manual Rolling Method”
为了避免在打补丁时遇到磁盘故障,建议使用高度冗余(HR)。
Some customers not having HR use the “manual rolling method”, which is for one cell at a time:一些没有高冗余的客户使用“手动滚动方法”,一次对一个cell操作:
- 删除故障组
- 重新平衡磁盘组
- 给cell打补丁
- 将磁盘再次添加到磁盘组
- 重新平衡
- 优点:更多的控制/同步点
- 缺点:额外的时间和负载
在进行非滚动打补丁之前,添加手动停用gd的内容。
当cell上线且diskrepair时间已过期,就会出现风险。
重新平衡 vs. 重新同步
- 重新平衡: 添加,删除或调整磁盘大小。
- 故障组或磁盘暂时不可用:被认为是可由Oracle ASM快速镜像重新同步功能恢复的瞬态故障。
Oracle ASM fast resync keeps track of pending changes to extents on an OFFLINE disk during an outage. Oracle ASM的快速重新同步功能跟踪停电时的离线磁盘上盘区的挂起的更改。当磁盘重新联机,盘区被重新同步。
再同步速度不受asm_power_limit影响。
磁盘组有一个disk_repair_timer,它指定你修复磁盘的时间,然后将它们重新上线。对于每个能成功上线的磁盘,挂起的删除操作将被取消且重新同步操作开始。如果disk_repair_time到期,磁盘将被删除。
补丁管理器 – 组件
- 补丁管理器:
–在compute节点以相当于cell的 root执行,配合补丁的应用
- $VERSION.patch.tar
–例如: 11.2.2.4.2.111221.patch.tar
–包含支持的补丁过程的shell脚本,例如:
- install.sh
- checkdeveachboot
- image_functions
- biosbootorder
Install.sh知道cell应是什么样(也在重新映像时并被调用); dostep.sh运行install.sh但并不真正知道如何进行低级别打补丁。
- $VERSION.$BUILD.iso
–例如: 11.2.2.4.2.111221.iso
- Bootable cd with cellbits
- db_patch_$VERSION.$BUILD.zip
–例如:db_patch_11.2.2.4.2.111221.zip
- dcli
- etc
–<bug number=”13513611″ description=”EXADATA 11.2.2.4.2 (MOS NOTE 1388400.1)”/>
- README’s
–TXT
–HTML
补丁管理器 – 日志
- 终端输出应该提供足够的信息来监测,了解详细信息或解决问题:
–(database) server where 补丁mgr runs:
- 补丁mgr.stdout, .stderr
- <cellname>.log
–Cells:
- /root/_补丁_hctap_/_p_/wait_out_tmp => current step
- /root/_补丁_hctap_/_p_/wait_out => cumulative steps
- 在 ‘zero boot’以及 ‘first boot’时,额外的日志文件也被创建…
- /var/log/cellos/install.post*
- /var/log/cellos/cell.bin.install.log
- /var/log/cellos/validations/*.log
- /var/log/cellos/validations.log
- /var/log/cellos/cellFirstboot.log
- /var/log/cellos/ipconf.log
- /var/log/messages
- /var/log/cellos/CheckHWnFWProfile.log
补丁管理器 – 清理
使用:
-cleanup
Clean up all 补丁 files and temporary content on all cells. This step can be done manually if 补丁 fails by removing directory /root/_补丁_hctap_ on each cell.
它删除了什么:
/opt/oracle.cellos/DISABLE_HARDWARE_FIRMWARE_CHECKS
/root/_补丁_hctap_
/root/dostep.sh
/root/.补丁_timeouts
/root/.griddisks_to_activate_if_补丁_failed
/tmp/_EXA_AXE_*
/root/_EXA_AXE_*
/opt/oracle.cellos/补丁/history/stat
/opt/oracle.cellos/补丁/bin/补丁stat.sh
WIP文件通常有失败的最重要的原因,因为这些实际上是在故障发生时运行的。
Wait_out_tmp-currentstep通常有列出的故障。
补丁管理器 – 最佳实践
- 使用 VNC
–最好在非exadata节点上使用VNC
–安全政策: 打补丁后从compute节点卸载
–
- 补丁管理器应始终从一个没有被打补丁的服务器启动
Asmdeactivationoutcome由补丁管理器PREREQ检查
- 不要从一个计算节点驱动补丁管理器,因为它正在打补丁
- 滚动:首先对在cell_group中唯一的cell以滚动方式尝试新的补丁
- 同时运行cell和计算补丁的缺点是没有同步点。意思是,如果有什么失败,你可能无法很快找到根本原因。
监控:
- 使用基于网络的控制台在补丁应用期间监控cell
- 从另一个终端会话使用less -rf patch mgr.stdout监控补丁活动
- 在每个被打补丁的cell上,可以显示文件尾部, /root/_patch_hctap_/_p_/wait_out
操作:
- 在ILOM更新期间你将失去任何连接,需要重新连接
- 不要从串行控制台或ILOM启动补丁管理器
- 对每个补丁或回滚过程在会话中使用一个新的日志
- 一旦在cell开始初始了打补丁,不要中断它
- 在打补丁时,不要重启或开闭cell
–如果补丁没有进展,查看patchmgr.stderr 和patchmgr.stdout 看看发生了什么。在cell上 /root/ _patch_hctap_/_p_/ wait_out_tmp查看发生了什么
- 不要在编辑模式下开启任何日志文件。使用less not vi
Cell 打补丁指南
Cell 打补丁流 – 测试环境
测试cell打补丁的最佳实践是等效的机器。
然而,由于资源有限,有一些替代:
| 测试环境 | 评价 |
| 较小的DBM | 无生产规模的性能测试 |
| 较旧的DBM | 无生产规模的性能测试
无固件打补丁测试 |
| 无-DBM | 对于测试cell打补丁来说不是一个选择 |
| 共享的DBM | 有多个DBM的较大的安装,对测试环境共享一个DBM |
对于cell补丁,理想的测试环境是生产系统的副本。
由于资源限制,这样的系统可能不可用。
但是,创建一个比理想稍差的环境仍有优势。
它本身就说明了要测试cell补丁必须有一个cell。
在这种情况下有这些选择:使用较少的cell,或较旧的cell(V1)
当然由于你选择了与生产系统不同,就会有风险。
例如:V1的硬件有不同的固件,拥有较少的cell可能会提示错误的时机,因为共享的DBM 可能难以补打丁。
安装和测试指南
1.查看补丁文档
–README 和引用的 Support Notes
2.在测试环境中应用并验证
–应用补丁
–验证补丁安装(Exachk)
–验证功能和性能
–自动化
–包括编写,以及测试和验证
–定义并测试备用计划
自动化:较少应用于cell打补丁,也取决于受众。
也可应用于cell打补丁相关的事,包括准备,测试和验证
由Exachk更换健康检查/再次检查健康检查/ Exachk上的其他位置
TBD:最新exachk和cell补丁的地址问题,
Cell补丁应用的HighLevel的步骤无非是:
准备
安装测试/补丁验证/自动化/备用计划
生产应用
- 3. 在生产环境中应用
–最新exachk的地址问题
–在StandbyFirst 应用(如果可用的话)
- 使用快照standby(如果可以的话)在standby损坏测试补丁
–回归的监控
Support Note 1262380.1 (补丁测试指南)
自动化:较少应用于cell打补丁,也取决于受众。
也可应用于cell打补丁相关的事,包括准备,测试和验证
由Exachk更换健康检查/再次检查健康检查/ Exachk上的其他位置
TBD:最新exachk和cell补丁的地址问题,
Cell补丁应用的HighLevel的步骤无非是:
准备
安装测试/补丁验证/自动化/备用计划
生产应用
Cell 补丁 – 准备
Cell 打补丁准备(1-2 周)
打补丁前的1或2周:
- 获取EXACHK分析(1070954.1)
- 查看补丁README(包括故障排除
- 发出一个”alter cell validate configuration”
- 考虑做各种的前提条件和 cell.conf 检查
- /opt/oracle.cellos/ipconf –verify
- 确保ILOM或串行控制台,KVM访问是可能的
- 最好还有物理访问
- Stage 补丁文件 (本地,不在NFS)
- 决定补丁将是不滚动/滚动/ “谨慎地滚动cautious rolling”
- 对于11.2.0.1,你必须在BP6或更高且GI BP4 来进行滚动补丁
- 现在测试系统应用并测试补丁
- 如果应用于生产,让补丁先运作几周
打补丁前1天:
- 就在打补丁前重新运行Exachk
ü 如果硬件组件失败,关闭补丁窗口。
ü确保实施了最佳实践
- “ALTER CELL VALIDATE CONFIGURATION” 生成:
ü /var/log/cellos/CheckHWnFWProfile.log
ü /var/log/cellos/checkdeveachboot.log
- 检查补丁级别
ü 与Critical Issues List 比较(MOS 1270094.1)
ü 有助于避免ASM问题
- 如果不满足前提条件,关闭补丁窗口
- 查看README 和 MOS notes了解最新更新
更改cell验证配置生成以下日志文件,以ms_loose选项运行
Cell 打补丁 – 最后一分钟准备
打补丁前几小时:
–获得“Fresh” 补丁, READMEs,,和 MOS Notes
- 检查打补丁的一天!
- 检查补丁上的md5sum
–检查ILOM反应,如果需要就重新设置
- alter cell 重启 bmc / ipmitool bmc 重置 cold / web 界面
–打开控制台和终端
- ILOM,串行控制台,KVM访问是可能的
–选择性地再次运行exachk并让它只检查cell (并减少需要的时间)
Cell 打补丁 – 准备
- 为Oracle ASM调整disk_repair_time
–更改磁盘组 <diskgroup name> 设置属性 ‘disk_repair_time’=’3.6h’;
–3.6h 是默认
–最小值应当反应打补丁超时 (2小时)
SELECT name, value
FROM v$asm_attribute
where group_number in
(select group_number
from v$asm_diskgroup
where name = ‘<DISKGROUP>’)
and name = ‘disk_repair_time’;
Cell 打补丁 –通用制备
- 如果 -rolling 选项会同补丁管理器工具被使用,那么补丁管理器确保所有磁盘的 asmdeactivationoutcome 是‘YES’:
dcli -g cell_group -l celladmin cellcli -e list griddisk attributes name,status, asmdeactivationoutcome | grep -v Yes
文件“cell_group” 列出要打补丁的cell(management name)
Cell 打补丁 – 补丁管理器作什么准备
- ./patchmgr –cells ~/cell_group –补丁_check_prereq
–在所有节点并行运行
–复制和提取prereqs(1分钟)
–不会复制补丁本身的iso
–验证细胞在线并具有root用户等效
–在所有cell执行前提条件检查:
- 检查空间和状态(1分钟)
- 文件系统空闲空间
- NFS/SMB 挂载
- CELLBOOT USB设备
- Cell服务状态
- 版本兼容性
–将 $VERSION.$BUILD.patch.tar 推至所有cell
–提取所有cell上的 $VERSION.$BUILD.patch.tar
Prereq 前提条件检查:

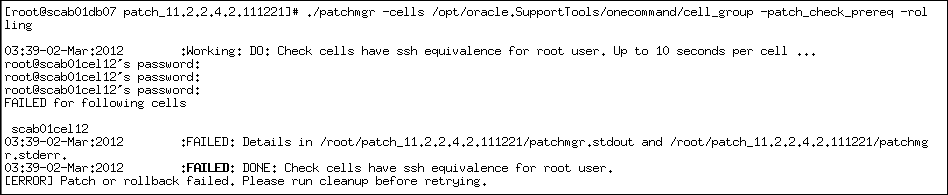
Cell 打补丁 – 准备失败
示例 – 补丁已被应用:

示例 – 无ssh设置:
应用一个cell补丁
应用一个cell补丁– 一般流程
- .下载任何变通方法/帮助
- 检查前提条件:
./patchmgr -cells cell_group
-patch_check_prereq [-rolling]
- 应用并监控补丁
./patchmgr -cells cell_group –patch [-rolling]
- 验证成功的补丁
–执行 ‘imageinfo’
–验证补丁日志文件
–检查 validations.log
–执行 CheckHWnFWProfile
- 清理: ./patchmgr -cells cell_group -cleanup
启动补丁管理器:

应用 – 高级步骤‘Rolling’
1.停用在一个cell上所有能停用的grid磁盘。能停用的grid磁盘属性asmdeactivationoutcome’设置为 ‘YES’。
2.确认被停用的磁盘处于脱机状态。
3.对cell打补丁。
4.在cell正确重启并上线后,激活被停用的grid磁盘。
5.确认在步骤4激活的所有grid磁盘都上线(不同步)。
6.移动到下一个要打补丁的cell并重复步骤。
Cell 打补丁 – 补丁分布
- 注:虽然不是关键的,但将作为补丁一部分的iso分布到所有cell的过程对资源/性能方面有影响。
- 使用cell_group文件中的IB主机名相比使用cell组中的管理名称对CPU有更大影响。
这是因为更多(补丁)数据在更小的窗口被转移到cell。正因如此,ssh 需要更快解密。
这支持在低活动期对补丁的建议。
打补丁后匹配硬件/固件
CheckHWnFWProfile:
- 该工具检查系统是否满足要求的硬件和固件规范,并报告所有不匹配。建议在升级每个cell后运行,但也要打补丁后由exachk执行。 It’s recommended to run this after the upgrade on each cell but also done by exachk which should be executed after 补丁ing also
[root ]# /opt/oracle.SupportTools/CheckHWnFWProfile -c strict
[SUCCESS] The hardware and firmware profile matches one of the supported profiles
或者
172.108.1.6:[WARNING ]The hardware and firmware are not supported.
See details below
[DiskControllerPCIeSlotWidth ]
Requires: x8 Found: x4
[WARNING ]The hardware and firmware are not supported. See details above
应用一个Cell 补丁– 影响
在滚动升级期间,cell 打补丁可能由于以下因素影响性能:
- 减少的IO带宽
- 在重新同步期间其他的IO
这只是示例,定时还取决于多个因素
例如,基准是 225 tps, Swingbench SOE。
在重新同步期间性能下降。注:只是一个 ¼ rack !
| 行为 | 时间戳 | TPS |
| Cel12 – ASM resync | 10:47-11:19 | 210 |
| cell 13打补丁 | 11:19-12:02 | 160 |
| Cel13 – ASM resync | 12:02-12:46 | 215 |
| cell 14打补丁 | 12:46-1:22 | 175 |
| Cell14 resync | 1:22-2:07 | 225 |
| 完成 | 2:07 | 210 |
Cell 补丁阶段和定时
Cell 补丁定时 – 概览 (1/4 rack v2)
非滚动示例:从 11.2.2.3.2 到 11.2.2.3.4
| 行为 | 时间 |
| CRS 关闭 (2 节点) | 1min 13sec |
| Cell 服务关闭(3 cells) | 0min 12sec |
| 补丁管理器前提条件 | 0min 48sec |
| 补丁管理器补丁 | 140min 39sec |
这个补丁只有一个ILOM 更新 (无磁盘固件,hca 等)
滚动示例: ¼ rack 从 11.2.2.4.1 到 11.2.2.4.2
| 行为 | 时间 |
| 补丁管理器前提条件 | 2min 0sec |
| 补丁管理器补丁 | 259min 3sec |
一般来说一个第五位版本不应该花费140分钟来打补丁。
Cell 补丁定时 – 故障 (qtr rack)
滚动示例:到 11.2.2.2.2
| 行为 | 时间 (分钟) |
| 打补丁总时间 | 233 |
| 减少的ASM冗余度保护的总时间 | 220 |
| 等待ASM重新同步的总时间 | 142 |
| 等待ASM磁盘下线的总时间 | 10 |
| 当ASM磁盘下线时等待重启和验证的总时间 | 68 |
滚动示例: 11.2.2.4.2 到 11.2.3.1
| 行为 | 时间 (分钟) |
| 打补丁总时间 | 159 |
| 减少的ASM冗余度保护的总时间 | 141 |
| 等待ASM重新同步的总时间 | 19 |
| 等待ASM磁盘下线的总时间 | 6 |
| 当ASM磁盘下线时等待重启和验证的总时间 | 132 |
数据库负载较低,所以重新同步时间较短
故障的定时 11.2.2.4.2 -> 11.2.3.1
| Normal | |
| 前提条件 | 0:01:26 |
| 补丁初始化阶段(重启前) | 0:13:16 |
| 完成 (重启前) | 0:09:47 |
| Reboot 1 | 0:05:31 |
| Zero‘ 启动补丁应用 | 0:06:00 |
| Reboot 2 | 0:06:19 |
| 第一次启动 | 0:06:21 |
| Reboot 3 | 0:05:15 |
| 检查阶段 | 0:05:20 |
| Grid磁盘激活 | 0:08:52 |
| 总计 | 1:08:07 |
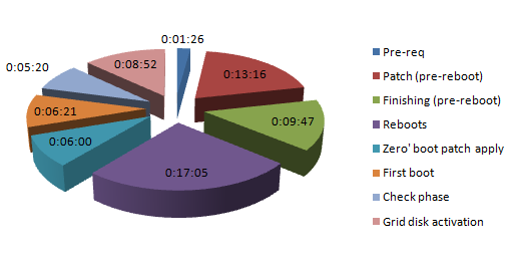
在一个cell打补丁的平均总时间可高达90分钟。
对于这个升级,即从11.2.2.4.2 => 11.2.3.1,cell打补丁花费+/- 70分钟。
当以滚动方式应用补丁,打补丁的总时间的大部分是并行所有cell花费的时间。
在这个例子中,70分钟内14分钟是花费在‘补丁PREREQ检查’(1.26)和补丁初始化(13.16)。这接近总时间的10%。
这是“好”的,因为并行操作能节省时间。对于应用的滚动cell,在补丁(重启前)或初始化后进行的每一步是基于节点到节点的方式。
我们说的补丁(11.2.3.1)应用于X4275,并其中有以下更新:
DiskControllerFirmwareRevision
DiskFwVersion
如果你看一下整体的故障,你可以在实际cell打补丁过程中轻松识别有不同的阶段:
1)前提条件检查,这即使在滚动模式也是所有节点并行进行,且最多要1.5分钟
2)补丁初始化,这即使在滚动模式也是所有节点并行进行,需要13分钟
3)补丁完成,基于每个cell完成,只需9分钟
4)重新启动,基于每个cell,要+/-5分钟
5)“零”启动,基于每个cell,要6分钟
6)重新启动,基于每个cell,要+/-6分钟
7)第一次启动,基于每个cell,要+/-7分钟
8)重新启动,基于每个cell,要+/-5分钟
10)检查阶段,基于每个cell,要+/-5分钟
11)grid磁盘激活/重新同步,基于每个cell,要+/-9分钟
“前提条件检查”阶段(1)补丁期间,-apply基本上将补丁复制到cell。
我们已经证明,这是不扩展,为此以bug被提交:bug13934922 – 补丁的ISO分布不可扩展
注:在初始网格磁盘激活,补丁管理器每隔60秒检查网格磁盘的状态是什么。
目前,最糟糕的情况下,一个新的循环启动后1秒该cell使所有磁盘重新同步,我们可能会浪费59秒。
在滚动方式下:当一个cell完成时,我们将下一个cell上立即启动
故障的定时 11.2.2.4.2 => 11.2.3.1 (多个)
| 完成 (重启前) | 0:10:19 | 完成 (重启前) | 0:08:48 | |
| 重启 | 0:16:18 | 重启 | 0:16:18 | |
| 0‘ 启动补丁应用 | 0:05:00 | 0′ ‘启动补丁应用 | 0:03:27 | |
| 第一次启动 | 0:06:49 | 第一次启动 | 0:06:49 | |
| 检查阶段 | 0:05:00 | 检查阶段 | 0:08:42 | |
| 网格磁盘激活 | 0:10:43 | 网格磁盘激活 | 0:02:45 | |
| 总计 | 0:54:09 | 总计 | 0:46:49 |
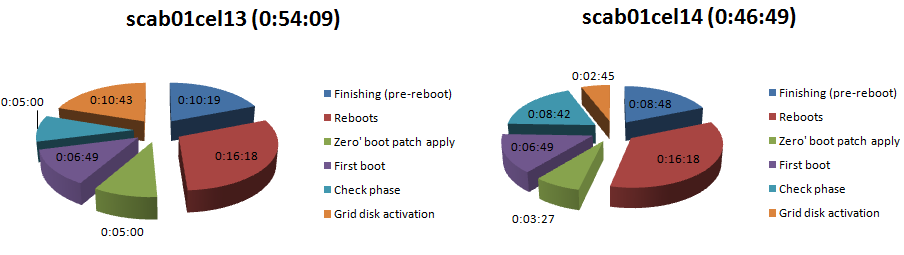
这是另一个打补丁练习的一个步骤。目标是明确总体上看如何。
你在这里缺失的是前提条件和补丁初始,因为它们有相同的。
注意到的总时间接近。一些定时完全匹配,这是巧合。
补丁 初始阶段
| 补丁重启前 > 10 秒 | |
| check_disks_and_partitions | 0:00:11 |
| Rebuild CELLBOOT USB | 0:03:37 |
| Check healthy states of Bootable or/and MD device(s) | 0:00:25 |
| reset_sp | 0:04:01 |
| image_instance | 0:03:39 |
| prepare_speedy_firmware_rollback | 0:00:15 |
| update_to_new_fw_for_out_of_partition_patch | 0:00:37 |
| sum other < 10 sec | 0:00:31 |
| SUM | 0:13:16 |
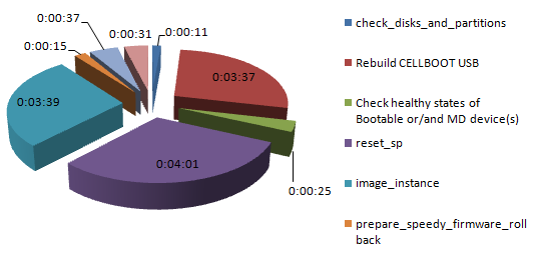
2)“补丁(重启前阶段)”基本上有两个步骤:
a)步骤1(补丁初始化),这是在所有cell间并行
b)在步骤1((补丁初始化)完成后,完成步骤将在一步步的基础上进行。
步骤 a)这是我们所说的“补丁初始化”。这需要+/- 12分钟,基本上花费大部分的时间做了以下内容:
重建CELLBOOT USB(3.5分钟)=>
make_cellboot_usb.sh -force:
当USB和系统分区有相同的版本时重新创建cellboot usb。如果在从image_functions调用这个脚本之前usb被挂载,unmounts usb。
这里发生的是
我们格式化USB(估计10秒)
新的initrd和cellbits doclib.zip / debugos / initrd的/ cellboot / cellfw从ISO镜像被复制到usb。我们一路做了一个md5sum。 (估计1.5分钟)
我们还将/opt/oracle.cellos/iso/lastGoodConfig中的lastGoodConfig复制到USB。 (1.5分钟)
GRUB安装(20秒)
大部分的工作是在LastGoodConfig的一个个文件的复制中。这需要时间且可能被改善。
reset_sp(4分钟)
reset_sp = yes默认为yes。在install.sh(run_it)中。
这意味着我们执行“ipmitool mc reset cold”,并等待240秒。
我们有可能会无法达到SP来重置它。打补丁可能会失败。
这就是为什么我们创建Bug 13934980 – 如果ILOM没有响应,CELL 打补丁前提条件-检查应该失败
“image_instance”(3.5分)
这是从do_instance.sh脚本调用的。程序image_instance实际上位于imaging_functions
称为:image_instance 带参数STORAGE/ /md5 /mnt/imaging/补丁 /root/_patch_hctap _ / _ P_的/ tmp / initrd的力量
时间被花费制作新的文件系统上的新的MD5(和MD7)在这种情况下
时间是花在复制和提取cellbits一切从ISO
摘要:在这里发生的是什么
新MD设备的格式
新cellbits被复制并提取和一些转的安装在新rpm_root
现有的配置文件复制到新的MD(密码,inittab文件,fstab中,sshd的,主机,但再生SSH密钥)
NB1:在这个阶段,我们做各种额外的检查,同时也是前提条件检查如:
检查可用空间
检查MD,磁盘和分区的健康
celld服务的状态
这意味着任何检查失败,这里将导致补丁失败,但它不是预期的。
NB2:prepare_speedy_firmware_rollback,我们在这里做的是隐藏固件较旧版本使回滚上的固件更新更快
NB3:update_to_new_fw_for_out_of_partition_patchDISK_ONLY在应用磁盘和LSI卡固件更新,以减少打补丁的时间,并确保正确的LSI属性设置
diskfirmware的更新可能需要更长的时间,取决于你是什么版本。
补丁完成阶段
| Finishing pre-reboot > 10 sec | |
| check_disks_and_partitions | 0:00:11 |
| Rebuild CELLBOOT USB | 0:04:38 |
| Check healthy states of Bootable or/and MD device(s) | 0:00:24 |
| cell_deactivate_griddisks | 0:00:22 |
| upgrade_cell_boot_hd | 0:00:41 |
| cell_updown.sh hookA | 0:00:24 |
| alter cell shutdown services all | 0:00:11 |
| set_cell_boot_usb | 0:02:12 |
| sum other < 10 sec | 0:00:44 |
| SUM | 0:09:47 |

这实际上是以前的幻灯片的步骤b):“补丁初始化”的完成。注意,这是在进行滚动补丁应用时,基于一个个cell完成的。这仍然是第一次重新启动。
大部分时间都是花费在
重建CELLBOOT USB(再次)(4.5分钟)
set_cell_boot_usb CELLBOOTONLY(2.5分钟)
请注意,这是在第一次重新启动发生之前的最后一步
在重建CELLBOOT USB时发生了什么,为什么我们再次运行它:
第一次创建是为了确保我们实际上可以编写和创建健康的USB,就像它存在。我们发现做粗略的检查是不够的,因为它不保证USB实际上可以被写入。过程中之后写入USB失败会有更坏的影响。
试图对坏的USB购买保险是粗略的尝试。
奖励是一个干净的新建的USB有从硬盘复制到USB的最新的可能救援使用的数据。
第二次创建用当cell通过USB重新启动时需要用于管理升级的东西填充。
set_cell_boot_usb中发生了什么:
内核被保存到/opt/oracle.cellos/iso/
usb的 分区和格式(这很奇怪,因为我们只是做了2 x cellboot USB.因此下面的bug被提交:bug 14036792 – CELL_BOOT_USBUN-DOING ALL THE WORK OF A DOUBLE CALL TO “REBUILD CELLBOOT”)
再次复制cellbits
提取cellboot.tbz(vmlinuz/grub)
为第一次重新启动准备好从现有的内核启动的USB。
NB1:check_disks_and_partitions用来检查降级 md 和标签
NB2:“Check healthy state”验证启动顺序
NB3:cell_deactivate_griddisks列出griddisk属性名称,状态,asmmodestatus
NB4:upgrade_cell_boot_hd:备份内核/启动,然后一个个删除文件,压缩归档文件,然后放置新cellboot.tbz
NB5:cell_updown.sh:这是需要被我们为升级而关闭任何服务之前需要完成的操作列表。
像之前说过的,这个阶段在首次重新启动之前(我们称之为“零启动”)
‘零启动’ 阶段
| Zero boot > 10 sec | |
| 10commonos/install.sh | 0:01:00 |
| 60cellrpms/install.sh | 0:01:00 |
| 90last/install.sh | 0:01:00 |
| init.d/upgradecbusb | 0:03:00 |
| sum other < 10 sec | 0:00:00 |
| SUM | 0:06:00 |
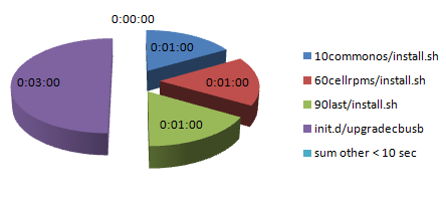
总结:在这一阶段重点发生了什么:
通过现有的内核从USB中启动的系统。没有服务将被启动,以服务任何ASM实例。
操作系统,将通过包(通用,内核,OFED,cell软件)进行更新。固件(非LSI,非磁盘)将被解压。
突出消耗时间最多的脚本:
10commonos / install.sh:从/opt/oracle.cellos/iso/cellbits/commonos.tbz安装通用包(openssh,ipmi,部分的等)
60cellrpms / install.sh:从cellrpms.tbz(exadata-firmware-cell-11.2.3.1.0.120304-1.x86_64.rpm)安装cell 额外软件包
[root@scab01cel13 tmp]# rpm -qpl exadata-firmware-cell-11.2.3.1.0.120304-1.x86_64.rpm
warning: exadata-firmware-cell-11.2.3.1.0.120304-1.x86_64.rpm: Header V3 DSA signature: NOKEY, key ID 1e5e0159
/opt/oracle.cellos/CheckHWnFWProfile
/opt/oracle.cellos/SUNBIOSPowerCycle
/opt/oracle.cellos/iso/cellbits/cellfw.tbz (SUNDiskControllerFirmware_B4, SUNInfinibandHCAFirmware_B0, Sunbios, ST360057SSUN600G)
90last / install.sh:停止不需要的服务,删除不需要的RPM。
init.d / upgradecbusb:调用set_cell_boot_usb“$ find_usb_mode”/保存$ MNT_CELLBOOT_USB $ MNT_CELLBOOT_LOCK“‘cat$ FACTORY_MARKER 2>的/ dev / null`”kernel
这样做是为USB准备一个新的内核。 (替换现有的内核)
在这个阶段,更多的步骤执行,但像上一张幻灯片一样,没花费那么多时间,所以不在这个幻灯片中处理
这并不总是意味着它们不重要。
这里缺少的步骤是:
/install/post/30kernel/install.sh,
/install/post/40debugos/install.sh,
/install/post/50ofed/install.sh,
/install/post/70sunutils/install.sh,
cellbin
这个阶段之后是第二次重启,我们称之为’Firstboot “,也许不如称之为”后成像的步骤“
顺便说一句:“FirstBoot.sh‘在‘Zero boot”期间调用,但我们退出FirstBoot.sh因为我们还在完成成像后的步骤
First boot 阶段
| First boot > 10 sec | |
| ipconf.pl -init | 0:00:36 |
| Setting firewall | 0:00:00 |
| CheckHWnFWProfile -U | 0:05:40 |
| sum other < 10 sec | 0:00:05 |
| SUM | 0:06:21 |
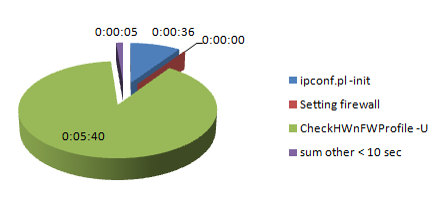
大多数时间花费在:
ipconf.pl-init
设置防火墙
CheckHWnFWProfile-U
总体而言,“Firstboot将”阶段处理在“零启动”启动的:
控制器高速缓存的设置,
检查网络,启动IPMI,
部署新的cell二进制文件,
设置防火墙和
最重要的应用固件。
固件由CheckHWnFWProfile-U应用作为S98exachkcfg的一部分
你会发现系统时间在这个步骤来回(bug针对它被提交:bug13986051 – SYSTEM TIME GOING BACK AND FORTH DURING CELL PATCHING)
Apr 18 12:12:43 Running /etc/rc.d/init.d/ipmi start …
Apr 18 12:12:44 Running /opt/oracle.cellos/ipconf.pl -init –force …
Apr 18 09:13:20 Created /.celld_dynamic_deploy after cell config applying
Fistboot后跟另一个(第三)重启…
检查阶段 11.2.2.4.2 -> 11.2.3.1
| Check Phase > 10 sec | |
| cellFirstboot.sh started | 0:02:25 |
| Check LSI Disk Controller | 0:01:25 |
| Miscelleneous each boot actions | 0:01:00 |
| checkdeveachboot | 0:00:30 |
| sum other < 10 sec | 0:00:00 |
| SUM | 0:05:20 |
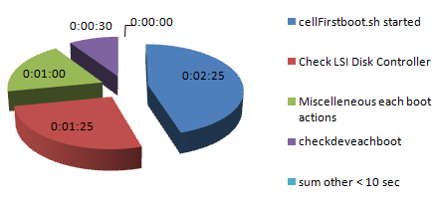
最后一个阶段是“检查”或“验证”阶段。这是因为一些验证被完成,如LSI缓存,CELLSRV状态和最重要的CheckHWnFWProfile,bootorder。
日志文件可以在/var/log/cellos/validations中找到,但是仍有一些配置的变化,如ipmisettings设置,删除现有的内核。
如果你发现在这里有很多的FirstBoot步骤再次被Firstboot.sh执行,那么这是正确的:
清理锁
LSI diskcontroler属性
ETH配置
这个阶段之后,我们还剩下一步,磁盘重新同步。
回滚一个Cell 补丁
回滚一个Cell 补丁 – 简介
- 回滚可以两种方式被触发
–在成功的打补丁练习后由用户触发
–作为补丁失败的一部分,无需用户干预而触发
–
- 回滚可以由 ‘rolling’ 和 ‘non-rolling’完成
- 发生了什么:
–‘其他r’ md 设备会被设置为启动并运行之前的版本。
– 固件的之前版本会被应用
- 从 11.2.2.4.2开始,我们降级驱动器固件,但只需要最低版本
回滚 回滚(前滚)实际上是回滚到更高的版本。
不确定这是否能行。这些信息仍应在磁盘上。
- 如果不能回滚怎么办?
–从拯救USB启动
–导入磁盘
–重试补丁
回滚不是为了修复故障,而是回到之前的镜像
回滚 回滚(前滚)实际上是回滚到更高的版本。
不确定这是否能行。这些信息仍应在磁盘上。
回滚– 前提条件检查
对于初始回滚的用户,以相同的指南和最佳实践更新cell是正常的做法。在这里前提条件也很关键。这些步骤的列表参见 ‘打补丁’ 的幻灯片。
回滚前提条件的验证也通过补丁管理器完成。
./patchmgr –cells $CELLFILE –rollback_check_prereq
‘rollback_check_prereq’的工作:
- 验证root用户等效性,空间和Cell服务状态
- 将 “dostep.sh” 推到所有cell
- 为补丁在cell执行相同的检查
回滚一个Cell 补丁 – 步骤
打开ILOM进行监测,并启动一个新的终端会话:
./patchmgr -cells cell_group –rollback [-rolling]
验证成功的回滚 (imageinfo)
运行 exachk
补丁管理器的回滚功能的做法以及回滚花费的时间应当被认为与补丁管理器以补丁功能应用补丁相等
./patchmgr -cells cell_group –rollback [-rolling]
- 初始回滚/从USB准备重启
- 以滚动的方式,其他cell会被置于standby模式
- Cell 将从USB重启,且会被‘updated’到之前的版本
- 固件从之前的 /opt/oracle.cellos/iso/cellbits 目录被降级
- CELLSYS 和 CELLSW 被 ‘swapped’
- Cell 再次重启
- 验证发生/ CheckHWnFWProfile
- 镜像版本的验证
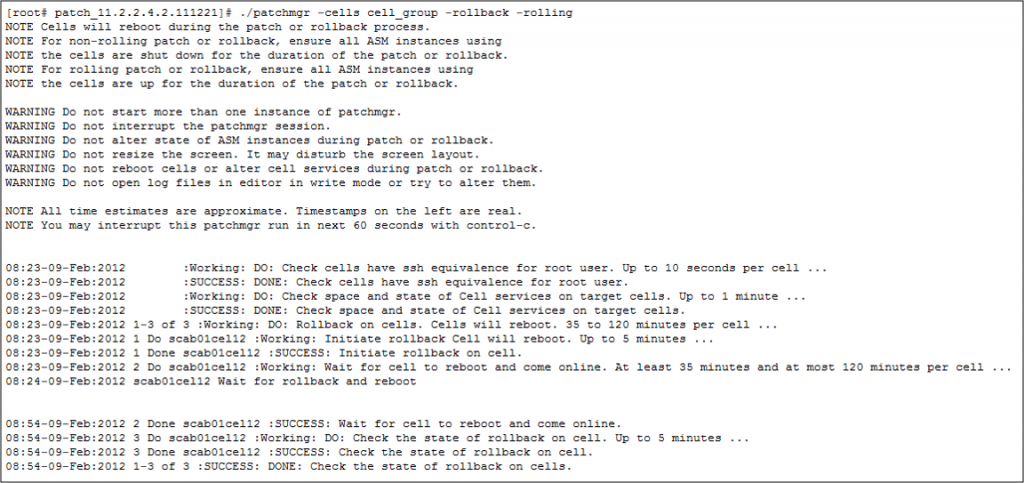
回滚– 一个 Cell 示例
- 注意只有3个步骤而在补丁应用中有5个
- 如果回滚失败:
- more investigation is required.需要更多的调查
- 最后的手段是CELLBOOT USB或重新成像
Cell 补丁 – 参考资料
参考
- MOS Notes
–Database Machine and Exadata Storage Server 11g Release 2 (11.2) Supported Versions (Doc ID 888828.1)
–Exadata Critical Issues (Doc ID 1270094.1)
–Exadata Diagnostic Collection Guide (Doc ID 1353073.1)
–INTERNAL Exadata Database Machine Hardware Firmware and 补丁 History (Doc ID 1358327.1)
–http://dbdev.us.oracle.com/twiki/bin/view/ExadataExternal/TroubleshootingTools
–INTERNAL Master Note for Oracle Database Machine and Exadata Storage Server (Doc ID 1274721.1)
- 补丁 README
补丁计划
–MOS 888828.1: 目前和以前的版本
–MOS 1270094.1: Exadata 关键问题
–MOS 1262380.1: Exadata 打补丁概览和补丁测试指南
–
–Exadata技术新闻
- blogs.oracle.com/MAA
–
Cell 补丁 – 案例
Cell 补丁案例 – 例 1
scab01cel14: #^#^# [WARNING] [COMMON] 4 Lock exists
scab01cel14: 18:0:0:0
scab01cel14:
scab01cel14: Starting MS services…
scab01cel14: The STARTUP of MS services was successful.
scab01cel14: [ERROR] Bootable or/and MD device(s) do not seem correct or consistent.
scab01cel14: [ERROR] 补丁 initiatlization failed.
scab01cel14: _EXIT_ERROR_Cell scab01cel14 10.133.40.42 10:40-09-Feb:2012: [ERROR] Failed. See details in the logs.
| From / To | 11.2.2.4.1 / 11.2.2.4.2 |
| 发生了什么 | 补丁应用中止 |
| 解决方案 | • /opt/oracle.cellos/validations/init.d/checkdeveachboot
• mdadm -Q –detail /dev/md11 • 清理补丁 • 在/tmp/cellos/locks/ 中的锁文件应当丢失 • 重试补丁 |
| 参考 | 13640357 / 13645385
当checkdeveachboot 在bug中提示后重试 这是11.2.3.1中一个已知的问题 |
Cell 补丁案例 – 例 2
01:41-09-Feb:2012 2 of 5 :SUCCESS: DONE: Waiting to finish pre-reboot 补丁 actions.
01:41-09-Feb:2012 3-5 of 5 :Working: DO: Finalize 补丁 and check final status on cells. Cells will reboot.
01:41-09-Feb:2012 3 Do scab01cel12 :Working: Cell will reboot. Up to 5 minutes …
01:41-09-Feb:2012 3 Done scab01cel12 :SUCCESS: Finalize 补丁 on cell.
01:41-09-Feb:2012 4 Do scab01cel12 :Working: Wait for cell to reboot and come online. At least 35 minutes and at most 1
20 minutes per cell …
01:41-09-Feb:2012 scab01cel12 Wait for 补丁 finalization and reboot
04:04-09-Feb:2012 4 Done scab01cel12 :FAILED: Details in /root/补丁_11.2.2.4.2.111221/补丁mgr.stdout and /root/补丁_
11.2.2.4.2.111221/补丁mgr.stderr.
04:04-09-Feb:2012 4 Done scab01cel12 :FAILED: Wait for cell to reboot and come online.
[ERROR] 补丁 or rollback failed. Please run cleanup before retrying.
| From / To | 11.2.2.4.1 / 11.2.2.4.2 |
| 发生了什么 | 补丁应用超时 |
| 解决方案 | • 重置 ILOM 并重启节点
• 清理补丁 • 重试打补丁后运作了 |
| 参考 | N/A |
Cell 补丁案例 – 例 3
# Problem:
在将一个v2 cell (X4275)从11.2.2.4.1.111203升级到11.2.2.4.2.111221后,四个griddisks无法再次上线也不能同步。
# Impacted Disks:
– DATA_SCAB01_CD_00_SCAB01CEL12
– RECO_SCAB01_CD_00_SCAB01CEL12
– DATA_SCAB01_CD_01_SCAB01CEL12
– RECO_SCAB01_CD_01_SCAB01CEL12
kfod does not list the disks
warning: GRIDDISK_STATUS_ALTER failed for guid 813838a7-a114-4549-bf3d-d3c356c0be2e as griddisk not found
| From / To | 11.2.2.4.1 / 11.2.2.4.2 |
| 发生了什么 | 在一个cell丢失4个grid磁盘 |
| 解决方案 | • 重置 ILOM
• 重置节点 • 激活磁盘 |
| 参考 | 13521289 / 13702763
(dmidecode -s system-product-name) |
Cell 补丁案例 – 例 4
# Slcc04cel08
05:41-18-Aug:2011 4 Done slcc04cel08 :FAILED: Details in
/tmp/补丁_11.2.2.3.5.110815/补丁mgr.stdout and
/tmp/补丁_11.2.2.3.5.110815/补丁mgr.stderr.
05:41-18-Aug:2011 4 Done slcc04cel08 :FAILED: Wait for cell to reboot and
come online.
[ERROR] 补丁 or rollback failed. Please run cleanup before retrying.
# /var/log/cellos/validations/celldstatus.log:
[ERROR] Exadata cell services failed to come up.
| From / To | Rolling 11.2.2.3.2 / 11.2.2.3.5 |
| 发生了什么 | Resplan无法使cellserv运作 |
| 解决方案 | • 禁用 resmanager / maint. Windows.
• 清理 • 重试 |
| 参考 | 12580529, 在11.2.2.4.0中解决 |
Cell 补丁案例 – 例 5
Triage:
我们为 ½ rack从 11.2.2.2.0 升级到 11.2.2.4.0 。所有挂在补丁的cell节点在wait_out_tmp文件中是standby 状态,且过去1个小时内没有对这个文件的更新。你能告诉我这是不是没问题,而且我在ilom控制台也没有看到任何信息
| From / To | 11.2.2.2.0 to 11.2.2.4. |
| 发生了什么 | 补丁是在standby状态超时
“ipmitool chassis power status” 检查超时,由于就在之前 的”ipmitool mc reset cold |
| 解决方案 | • 验证 “ipmitool chassis power status ” 能够执行
• 运行补丁管理器 -cleanup 然后重新运行补丁管理器-patch • 密切监控补丁管理器和它的日志文件并升级日志文件 |
| 预防 ? | 运行补丁管理器之前ipmitool mc 重置 cold 以避免这个问题 |
Cell 补丁–故障排除
故障排除– 有哪些问题
- 无响应ILOMs/ IPMItool超时
- Cell 无法启动
- Cell 服务无法启动
- Cell 关闭
- ‘imageinfo’显示成功,但重启cell 补丁后执行回滚
- 固件应用故障
–LSI 磁盘控制器
–“Bricked” 组件
- 磁盘损坏防止启动
- 在滚动的情况下: ASM bugs
- 意外中断
- 升级一个已经 “不健康” 的组件
- 在升级时的硬件故障
- CELLSYS / CELLSW 镜像损坏
好消息是人们会运行 pre-check
坏消息是: 人们不读 README

如何区分软件硬件问题
在升级失败的情况下:
硬件问题:
- 在控制台启动时发现
- 示例 bricked 控制器
- 补丁管理器等待
- 返回前需要很长时间 / 不响应
- 读出固件或系统日志时发现
- 性能下降
- 过些时间重启/ 重置可能有帮助
- 示例 ILOM 中 10 分钟等待应该是最大值。
- 重置 ILOM 不是每次都有效。拔出 AC等2分钟再插回去。
软件问题:
- 在验证检查期间更常发现
- 读取特定组件的日志文件和踪迹时发现
匹配硬件/固件
如果 CheckHWnFWProfile 失败且固件需要被刷新,那么在验证网格磁盘已下线且cell关闭后在有问题的系统运行以下命令再次尝试失败的固件升级。
[root ]# rm /opt/oracle.cellos/TRIED_*
[root ]# /opt/oracle.SupportTools/CheckHWnFWProfile -U
/opt/oracle.cellos/iso/cellbits
Now updating the ILOM and the BIOS …
该命令必须在单一行中输入。运行命令,关闭系统电源后,重置ILOM,并等待10分钟,然后启动系统。
从失败的补丁恢复
- 不是每个情况下是完全可恢复的
–有时组件是“bricked” ,需要先更换
- 对于失败的cell中,补丁可以被重试
–从cell_group 文件删除成功的cell
–
- 保存日志但经常清理
./patchmgr -cells cell_group -cleanup
- 参见README 的解决方案并重试
进行Cell 拯救,当:
- 系统磁盘故障,启动或文件系统在升级后不工作
| 步骤 | 行为 |
| 1. | 重启 |
| 2. | 进入拯救模式,即当看到Exadata splash屏幕,快速多次按下 ESC – 下拉到菜单底部并在拯救模式启动 |
| 3. | 选择 r 进行完整重建 |
| 4. | 选择 y 继续 |
| 5. | 给出拯救密码 (sos1exadata) |
| 6. | 选择 n 保存数据 |
| 7. | 如果需要继续,选择 y |
| 8. | 当提示作为 localhost 登录:提示登录作为 root/sos1exadata 和 sync; 重启以继续拯救 |
| 步骤 | 行为 |
| 9. | 让cell完成拯救并显示“now poweroff” 提示 – 按y键poweroff |
| 10. | 从LO/ILOM 再次启动 |
| 11. | 它会至少重启一次 |
| 12. | 作为 root/welcome1登录 |
| 13. | 通过 imageinfo验证cell正常,查找 “Active image status: success” |
| 14. | cellcli -e ‘import celldisk all force’ |
| 15. | 检查所有网格磁盘是否恢复 |
| 16. | 需要时重新应用配置:例如: cellcli -e ALTER CELL smtpServer=\’smtp.com\’, smtpPort=\’25\’, smtpUser=\’\’, smtpPwd=\’\’, smtpUseSSL=true, smtpFrom=\’celladmin\’, smtpFromAddr=\’celladmin@y.com\’, smtpToAddr=\’x@y.com\’, notificationMethod=\’mail\’, notificationPolicy=\’critical,warning,clear\’ |
- 如果cell不启动,可能需要拯救,使用diagnostics.iso工具:
- 用来启动服务器诊断问题
- 重新创建损坏的CELLBOOT USB当闪存盘
- 丢失
- 损坏
/opt/oracle.SupportTools/make_cellboot_usb.sh -force –verbose
- 如果恢复需要比预期更长的时间,或者如果它超过了客户能承受的风险水平,确保下线的griddisks被删除。
Cell 补丁 – 收集数据并获取帮助
诊断要收集哪些数据
- 补丁管理器日志
–屏幕上的内容
–*.log, 和 *std* 文件在补丁管理器工具运行的目录中
–在/root/_patch_hctap_ directory 和 /boot 目录中的文件
- 所有 *.log, *.txt, *.log, _p_/wait* 文件
- imageinfo 对有问题的cell的输出
- /var/log/cellos 命令的所有内容
- 也有助于收集时间
在实际的第一次重启期间创建的打补丁/升级的日志文件:
| 脚本 / 日志文件 | 目的 |
| install.post.10commonos.install.sh.log | 内核 / initrd / rpm likge glibc 等 |
| install.post.20sunutils.install.sh.log | 安装 ipmitool / Lib_Utils / MegaCli / ipmiflash |
| install.post.30kernel.install.sh.log | 安装内核创建 initrd |
| install.post.40debugos.install.sh.log | 安装其他的debug 包,如kerneldebug |
| install.post.50ofed.install.sh.log | 备份 openib.conf 并安装 rds/ofed packages |
| install.post.60cellrpms.install.sh.log | 安装其他的包,如 iscsi 同时设置安全 limits.conf |
| 脚本 / 日志文件 | 目的 |
| install.post.90last.install.sh.log | 停止服务/设置配置/删除工具 |
| cell.bin.install.log | 安装 jdk 和 cell rpm |
| vldrun.upgrade_reimage_boot.log | 设置验证状态 – 重启 |
| install.post.status | 对以上的检查 |
硬件和固件检查的输出
/opt/oracle.SupportTools/CheckHWnFWProfile -c loose > hwfw.`hostname`.txt
[SUCCESS] The hardware and firmware profile matches one of the supported profiles
- ipmitool 事件日志
ipmitool sel elist > ipmitool_sel_elist.`hostname -s`.txt
13cc | 12/19/2011 | 06:12:42 | System Firmware Progress | Option ROM initialization | Asserted
13cd | 12/19/2011 | 06:12:45 | System Firmware Progress | Option ROM initialization | Asserted
13ce | 12/19/2011 | 06:13:07 | System Firmware Progress | System boot initiated | Asserted
–
- sundiag.sh 输出zip文件
sundiag_2012_02_07_13_13/messages / alert.log / lspci / megacli / celldisk / disk devices / fdom
- ILOM 快照
- Note 1020204.1
- 控制台日志
ipmitool sunoem cli ‘show /SP/console/history’ > serialconsole.`hostname -s`.txt
如果只能访问cell的 ILOM,你可以使用:
ipmitool -H <ILOM ip address or hostname for the troubled cell> \
-U root \
-P <ILOM root user password> \
sunoem cli ‘show /SP/console/history’ > serialconsole.mycel01.txt
- $CELLTRACE目录的所有内容
- /opt/oracle.oswatcher/osw/archive中的OSWatcher数据
如果补丁失败且cell使用“其他”镜像怎么办?
Active image version: 11.2.2.3.0.110408
Active image activated: 2011-04-10 23:59:43 -0700
Active image status: success
Active system partition on device: /dev/md5
Active software partition on device: /dev/md7
Inactive image version: 11.2.2.2.2.110311
Inactive image activated: 2011-04-09 15:51:51 -0700
Inactive image status: failure
Inactive system partition on device: /dev/md6
Inactive software partition on device: /dev/md8
对于 < 11.2.3.1的镜像:
我们可以 mount /dev/md6 并像验证一样查看文件
[root@dscgif10s ~]# mkdir failed_补丁
[root@dscgif10s ~]# mount /dev/md6 failed_补丁
[root@dscgif10s ~]# cd failed_补丁/
[root@dscgif10s failed_补丁]#cd var/log/cellos/validations
-rw-r—– 1 root root 142 Apr 9 15:49 checklsi.log
-rw-r—– 1 root root 685 Apr 9 15:51 beginfirstboot.log
-rw-r—– 1 root root 822 Apr 9 15:51 ipmisettings.log
-rw-r—– 1 root root 4278 Apr 9 15:51 misceachboot.log
…
-rw-r—– 1 root root 994 Apr 10 22:41 checkconfigs.log
= 11.2.3.1: 信息被复制到 /var/log/cellos/dev/md?
丢失一个磁盘– 磁盘离线
Griddisk被停用
Mon Mar 05 12:28:35 2012
GMON checking disk modes for group 3 at 1126 for pid 34, osid 15525
NOTE: checking PST for grp 3 done.
WARNING: Disk 0 (RECO_SCAB01_CD_00_SCAB01CEL12) in group 3 mode 0x15 is now being offlined
WARNING: Disk 0 (RECO_SCAB01_CD_00_SCAB01CEL12) in group 3 in mode 0x15 is now being taken offline on ASM inst 2
NOTE: initiating PST update: grp = 3, dsk = 0/0xedecf9e2, mode = 0x6a, op = 4
NOTE: cache closing disk 0 of grp 3: RECO_SCAB01_CD_00_SCAB01CEL12
GMON updating disk modes for group 3 at 1127 for pid 34, osid 15525
NOTE: PST update grp = 3 completed successfully
NOTE: initiating PST update: grp = 3, dsk = 0/0xedecf9e2, mode = 0x7e, op = 4
GMON updating disk modes for group 3 at 1128 for pid 34, osid 15525
NOTE: PST update grp = 3 completed successfully
Mon Mar 05 12:28:35 2012
WARNING: Disk 0 (RECO_SCAB01_CD_00_SCAB01CEL12) in group 3 will be dropped in: (180) secs on ASM inst 2
Mon Mar 05 12:32:40 2012
GMON updating for reconfiguration, group 3 at 1135 for pid 36, osid 15529
NOTE: group RECO_SCAB01: updated PST location: disk 0012 (PST copy 0)
NOTE: group RECO_SCAB01: updated PST location: disk 0024 (PST copy 1)
NOTE: group RECO_SCAB01: updated PST location: disk 0002 (PST copy 2)
NOTE: group 3 PST updated.
Mon Mar 05 12:32:40 2012
NOTE: membership refresh pending for group 3/0x415c08eb (RECO_SCAB01)
GMON querying group 3 at 1136 for pid 19, osid 5315
SUCCESS: refreshed membership for 3/0x415c08eb (RECO_SCAB01)
SUCCESS: alter diskgroup RECO_SCAB01 drop disk RECO_SCAB01_CD_00_SCAB01CEL12 force /* ASM SERVER */
SUCCESS: PST-initiated drop disk in group 3(1096550635))
NOTE: starting rebalance of group 3/0x415c08eb (RECO_SCAB01) at power 1
Starting background process ARB0
Mon Mar 05 12:32:43 2012
ARB0 started with pid=30, OS id=18950
NOTE: assigning ARB0 to group 3/0x415c08eb (RECO_SCAB01) with 1 parallel I/O
NOTE: Attempting voting file refresh on diskgroup RECO_SCAB01
merge_alertlogs.sh
merge_alertlogs.sh:
- 不支持的/非官方的
- 不针对客户,在 here
- 根据时间合并多个警告日志的脚本
- 在多个alert.logs相同时间戳发生的事件将以实例顺序输出
从哪里获得帮助
- 记录一个SR
- 上传的所有踪迹,并记录到SRSR
- EXADATA_TRIAGE 列表
- 总是包括
- imageinfo 命令的输出
- OS 和版本
- 需要的补丁版本
- SR号