Exadata vs Greenplum vs Netezza

以下汇总的command 可以用于收集Exadata数据库一体机的诊断信息:

实例相关参数v$parameter Exadata相关的统计信息 v$sysstat 与Exadata相关的一些动态性能视图v$cell,v$cell_state,v$cell_thread_history,v$cell_request_totals - /etc/oracle/cell/network-config/cellinit.ora - /etc/oracle/cell/network-config/cellip.ora - cellcli -e list alerthistory detail - cellcli -e list cell detail - cellcli -e list celldisk detail - cellcli -e list griddisk detail - cellcli -e list iormplan detail - cellcli -e list metricdefinition detail - cellcli -e list metriccurrent detail - cellcli -e list metrichistory detail - cellcli -e list physicaldisk detail - /opt/oracle/cell/cellsrv/deploy/config/cellinit.ora - /opt/oracle/cell/log/diag/asm/cell/*/trace/alert.log - /opt/oracle/cell/log/diag/asm/cell/*/trace/ms-odl.trc - ls -alt /opt/oracle/cell/log/diag/asm/cell/*/trace/
以下是Maclean.Liu所编写或收集的有关Exadata V2 Oracle-sun Database Machine(DBM)数据库一体机的汇总文章列表:


Oracle Exadata v2的价格
Exadata V2 Pricing
一次Exadata上的ORA-600[kjbmprlst:shadow]故障分析
Exadata Server Hardware Details
Exadata用户的困境
My Opinion On Exadata V2
Warning:Even Exadata has a wrong memlock setting
Oracle Exadata Database Recommended Patch (BP3) for Bug 10387939
Exadata Database Machine Host的操作系统OS版本
数据仓库:Oracle Exadata和Netezza的比较
Exadata Smart Flash Logging新特性
Database Appliance并非Mini版的Exadata-还原真实的Oracle Unbreakable Database Appliance
Oracle Sun Exadata V2 ,X2-2,X2-8 主要配置对比
Exadata X2-2 vs EMC Greenplum DCA vs Netezza TwinFin 12主要配置大对比
Booting Exadata!
I/O Resource Management with Exadata
Exadata. Are you ready?
Database Machine & Exadata Storage
Oracle Exadata Overview
Exadata and Database Machine 11.2
Exadata MAA Best Practices Series Using DBFS on Exadata (Use Cases and Performance Expectations)
Teradata to Exadata Migration Methodology
Exadata V2 Sun Oracle Database Machine
Updates on New Exadata Pricing & Packaging
Exadata MAA Best Practices Series Session:Exadata Backup and Recovery
Maximizing Database Application Performance with Flash and Solid State Disks (SSDs)
Extreme Performance with Oracle Data Warehousing
从Exadata Storage Software 11.2.2.4开始引入了Exadata Smart Flash Logging的新特性,该特性允许LGWR进程将redo同时并行写入flash cache 和 disk controller 中, 只要在flash cache 和 disk controller中有任意一个率先写完成就会通知RDBMS数据库继续工作, 该特性着眼于改善了Exadata对Redo写入的响应时间和吞吐量。(The feature allows redo writes to be written to both flash cache and disk controller cache, with an acknowledgement sent to the RDBMS as soon as either of these writes complete; this improves response times and thoughput.);特别有利于改善log file sync等待事件是主要性能瓶颈的系统。
当频繁写redo重做日志的IO成为Exadata一体机的主要性能瓶颈的时候,Exadata开发部门自然想到了通过DBM上已有的flashcache来减少响应时间的办法。但是又要保证不会因为flashcache的引入而导致redo关键日志信息的丢失:
The main problem that number of writes in redo logs is very high, even there are no activity in database. Therefore Flash Cache disk will reach his write limit very fast – some days or months (I am not see exact test results). In this way you will lost flash cache disk and all data on them. But losing redo logs is very unpleasant case of database unavailability, which can lie in big downtime and possible data loss.
As you already know, 11.2.2.4.0 introduced the Smart Flash Log feature. For customers that are not in 11.2.2.4.0, don’t suggest putting the redo logs on a diskgroup that uses griddisks carved from flashdisks. There are different issues when using redo logs on the flashcache in previous versions and those should be avoided.
只要是安装过Exadata Storage Software 11.2.2.4补丁的系统都会隐式地启用该Exadata Smart Flash Logging特性,但是它同时也要求数据库版本要大于Database 11.2.0.2 Bundle Patch 11。
Metalink目前没有介绍如何在已经启用Exadata Smart Flash Logging的DBM上禁用(disable)该特性。
实际每个cell会分配512MB的flashcache用于Smart Flash Logging,因此现在每个cell的可用flash空间为 364.75Gb 。
不仅局限于Online Redo Log可以受益于Smart Flash Logging,Standby Redo Log 也可以从该特性中得到性能提升,前提是满足必要的软件版本组合cell patch 11.2.2.4 and Database 11.2.0.2 Bundle Patch 11 or greate。
可以通过CellCLI 命令行了解现有的Smart Flash Logging配置,若有输出则说明配置了Smart Flash Logging。
CellCLI> LIST FLASHLOG DETAIL
更多信息可以参考文档”Exadata Smart Flash Logging Explained”,引用如下:
Smart Flash Logging works as follows. When receiving a redo log write request, Exadata will do parallel writes to the on-disk redo logs as well as a small amount of space reserved in the flash hardware. When either of these writes has successfully completed the database will be immediately notified of completion. If the disk drives hosting the logs experience slow response times, then the Exadata Smart Flash Cache will provide a faster log write response time. Conversely, if the Exadata Smart Flash Cache is temporarily experiencing slow response times (e.g., due to wear leveling algorithms), then the disk drive will provide a faster response time. Given the speed advantage the Exadata flash hardware has over disk drives, log writes should be written to Exadata Smart Flash Cache, almost all of the time, resulting in very fast redo write performance. This algorithm will significantly smooth out redo write response times and provide overall better database performance. The Exadata Smart Flash Cache is not used as a permanent store for redo data – it is just a temporary store for the purpose of providing fast redo write response time. The Exadata Smart Flash Cache is a cache for storing redo data until this data is safely written to disk. The Exadata Storage Server comes with a substantial amount of flash storage. A small amount is allocated for database logging and the remainder will be used for caching user data. The best practices and configuration of redo log sizing, duplexing and mirroring do not change when using Exadata Smart Flash Logging. Smart Flash Logging handles all crash and recovery scenarios without requiring any additional or special administrator intervention beyond what would normally be needed for recovery of the database from redo logs. From an end user perspective, the system behaves in a completely transparent manner and the user need not be aware that flash is being used as a temporary store for redo. The only behavioral difference will be consistently low latencies for redo log writes. By default, 512 MB of the Exadata flash is allocated to Smart Flash Logging. Relative to the 384 GB of flash in each Exadata cell this is an insignificant investment for a huge performance benefit. This default allocation will be sufficient for most situations. Statistics are maintained to indicate the number and frequency of redo writes serviced by flash and those that could not be serviced, due to, for example, insufficient flash space being allocated for Smart Flash Logging. For a database with a high redo generation rate, or when many databases are consolidated on to one Exadata Database Machine, the size of the flash allocated to Smart Flash Logging may need to be enlarged. In addition, for consolidated deployments, the Exadata I/O Resource Manager (IORM) has been enhanced to enable or disable Smart Flash Logging for the different databases running on the Database Machine, reserving flash for the most performance critical databases.
以及<Exadata Smart Flash Cache Features and the Oracle Exadata Database Machine>官方白皮书,公开的文档地址:
[gview file=”http://www.oracle.com/technetwork/database/exadata/exadata-smart-flash-cache-366203.pdf”]
实测了以下Exadata smart scan对于INDEX STORAGE FAST FULL SCAN似乎实际并不生效,详见以下测试。不仅普通的B*tree index也包括compressed index、reverse key index等类型。
Why is my Exadata smart scan not offloading?
Exadata Smart Scan and Index Access
上面2篇文章介绍了了类似的XD offload 对index fast full scan不生效的问题, 相关的BUG有:
Bug 8257122 – Exadata smart scan caching does not work for INDEX FAST FULL scan (Doc ID 8257122.8)
以下测试了对NORMAL INDEX和bitmap index fast full scan的OFFLOAD情况:
SQL> select blocks,bytes/1024/1024/1024 from dba_segments where segment_name='LARGE_TABLE';
BLOCKS BYTES/1024/1024/1024
---------- --------------------
7127040 54.375
Elapsed: 00:00:00.19
SQL> alter system flush buffer_cache;
System altered.
Elapsed: 00:00:00.19
SQL> select count(*) from LARGE_TABLE where object_id between 1000 and 20000;
COUNT(*)
----------
486735872
Elapsed: 00:00:23.29
SQL> alter system flush buffer_cache;
System altered.
Elapsed: 00:00:00.19
SQL> select /*+ OPT_PARAM('cell_offload_processing' 'false') */ count(*) from LARGE_TABLE where object_id between 1000 and 20000;
COUNT(*)
----------
486735872
Elapsed: 00:03:24.22
SQL> create index pk_lt on large_table (object_id,data_object_id) tablespace larget parallel nologging;
Index created.
Elapsed: 00:01:14.18
SQL> alter index pk_lt noparallel;
Index altered.
SQL> exec dbms_stats.gather_table_stats('SYS','LARGE_TABLE',cascade=>TRUE, estimate_percent=>100, degree=>8);
PL/SQL procedure successfully completed.
Elapsed: 00:13:12.61
select a.name,b.value
from v$sysstat a , v$mystat b
where
a.statistic#=b.statistic#
and (a.name in ('physical read total bytes','physical write total bytes',
'cell IO uncompressed bytes') or a.name like 'cell phy%' );
NAME VALUE
---------------------------------------------------------------- ----------
physical read total bytes 0
physical write total bytes 0
cell physical IO interconnect bytes 0
cell physical IO bytes saved during optimized file creation 0
cell physical IO bytes saved during optimized RMAN file restore 0
cell physical IO bytes eligible for predicate offload 0
cell physical IO bytes saved by storage index 0
cell physical IO bytes sent directly to DB node to balance CPU 0
cell physical IO interconnect bytes returned by smart scan 0
cell IO uncompressed bytes 0
10 rows selected.
alter system flush buffer_cache;
set timing on;
set linesize 200 pagesize 2000
select /*+ FULL(LARGE_TABLE) */ count(*) from LARGE_TABLE where object_id between 1000 and 20000;
COUNT(*)
----------
486735872
Elapsed: 00:00:23.30
TABLE ACCESS STORAGE FULL| LARGE_TABLE | 403M| 1925M| 1935K (1)|
SQL> select a.name,b.value
2 from v$sysstat a , v$mystat b
3 where
a.statistic#=b.statistic#
and (a.name in ('physical read total bytes','physical write total bytes',
'cell IO uncompressed bytes') or a.name like 'cell phy%' ); 4 5 6
NAME VALUE
---------------------------------------------------------------- ----------
physical read total bytes 5.8303E+10
physical write total bytes 0
cell physical IO interconnect bytes 6055421032
cell physical IO bytes saved during optimized file creation 0
cell physical IO bytes saved during optimized RMAN file restore 0
cell physical IO bytes eligible for predicate offload 5.8303E+10
cell physical IO bytes saved by storage index 0
cell physical IO bytes sent directly to DB node to balance CPU 0
cell physical IO interconnect bytes returned by smart scan 6055396456
cell IO uncompressed bytes 5.8321E+10
10 rows selected.
Elapsed: 00:00:00.01
SQL>
SQL> alter system flush buffer_cache;
set timing on;
set linesize 200 pagesize 2000
System altered.
SQL> SQL>
SQL>
SQL> explain plan for select count(*) from LARGE_TABLE where object_id between 1000 and 20000;
Explained.
Elapsed: 00:00:00.02
SQL> @?/rdbms/admin/utlxplp
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 800139279
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 356K (1)| 00:00:14 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
|* 2 | INDEX STORAGE FAST FULL SCAN| PK_LT | 403M| 1925M| 356K (1)| 00:00:14 |
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - storage("OBJECT_ID"<=20000 AND "OBJECT_ID">=1000)
filter("OBJECT_ID"<=20000 AND "OBJECT_ID">=1000)
15 rows selected.
Elapsed: 00:00:00.02
SQL> select count(*) from LARGE_TABLE where object_id between 1000 and 20000;
COUNT(*)
----------
486735872
Elapsed: 00:02:01.66
SQL> oradebug tracefile_name
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_ora_39539.trc
SQL> select a.name,b.value
2 from v$sysstat a , v$mystat b
3 where
a.statistic#=b.statistic#
and (a.name in ('physical read total bytes','physical write total bytes',
'cell IO uncompressed bytes') or a.name like 'cell phy%' ); 4 5 6
NAME VALUE
---------------------------------------------------------------- ----------
physical read total bytes 1.3300E+10
physical write total bytes 0
cell physical IO interconnect bytes 1.3300E+10
cell physical IO bytes saved during optimized file creation 0
cell physical IO bytes saved during optimized RMAN file restore 0
cell physical IO bytes eligible for predicate offload 0
cell physical IO bytes saved by storage index 0
cell physical IO bytes sent directly to DB node to balance CPU 0
cell physical IO interconnect bytes returned by smart scan 0
cell IO uncompressed bytes 0
10 rows selected.
Elapsed: 00:00:00.01
END OF STMT
PARSE #47310019587768:c=2000,e=2137,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=1,plh=800139279,tim=1353385966411213
EXEC #47310019587768:c=1000,e=67,p=0,cr=0,cu=0,mis=0,r=0,dep=0,og=1,plh=800139279,tim=1353385966411365
WAIT #47310019587768: nam='SQL*Net message to client' ela= 3 driver id=1650815232 #bytes=1 p3=0 obj#=-1 tim=1353385966411401
WAIT #47310019587768: nam='cell single block physical read' ela= 511 cellhash#=451279719 diskhash#=3519799300 bytes=8192 obj#=25183 tim=1353385966414839
WAIT #47310019587768: nam='cell multiblock physical read' ela= 16720 cellhash#=451279719 diskhash#=3519799300 bytes=1048576 obj#=25183 tim=1353385966433058
WAIT #47310019587768: nam='cell multiblock physical read' ela= 2965 cellhash#=451279719 diskhash#=3519799300 bytes=1048576 obj#=25183 tim=1353385966440986
...........................
select count(*) from LARGE_TABLE where owner like '%SY%';
QL> explain plan for select count(*) from LARGE_TABLE where owner like '%SY%';
Explained.
Elapsed: 00:00:00.00
SQL> @?/rdbms/admin/utlxplp
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 3706014413
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5 | 19017 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 5 | | |
| 2 | BITMAP CONVERSION COUNT | | 26M| 127M| 19017 (1)| 00:00:01 |
|* 3 | BITMAP INDEX STORAGE FAST FULL SCAN| BIT_LT | | | | |
------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - storage("OWNER" LIKE '%SY%' AND "OWNER" IS NOT NULL)
filter("OWNER" LIKE '%SY%' AND "OWNER" IS NOT NULL)
16 rows selected.
Elapsed: 00:00:00.01
SQL> set linesize 200 pagesize 2000
SQL> select count(*) from LARGE_TABLE where owner like '%SY%';
COUNT(*)
----------
362643456
Elapsed: 00:00:01.07
SQL> select a.name,b.value
2 from v$sysstat a , v$mystat b
3 where
a.statistic#=b.statistic#
and (a.name in ('physical read total bytes','physical write total bytes',
'cell IO uncompressed bytes') or a.name like 'cell phy%' ); 4 5 6
NAME VALUE
---------------------------------------------------------------- ----------
physical read total bytes 173424640
physical write total bytes 0
cell physical IO interconnect bytes 173424640
cell physical IO bytes saved during optimized file creation 0
cell physical IO bytes saved during optimized RMAN file restore 0
cell physical IO bytes eligible for predicate offload 0
cell physical IO bytes saved by storage index 0
cell physical IO bytes sent directly to DB node to balance CPU 0
cell physical IO interconnect bytes returned by smart scan 0
cell IO uncompressed bytes 0
10 rows selected.
Elapsed: 00:00:00.02
SQL>
这是一套Exadata 上的11.2.0.1 四节点RAC 系统,从今年初开始频繁地因为LMS后台进程出现内部错误ORA-600[kjbmprlst:shadow]而导致实例意外终止, 虽然是4节点RAC 保证了其高可用性, 但是仍因为 实例经常意外终止 导致应用程序交易失败。
实际我在7月份已经分析过该问题了, 详见<Oracle RAC内部错误:ORA-00600[kjbmprlst:shadow]一例>一文 , kjbmprlst:shadow内部函数用以管理kjbm shadow锁(/libserver10.a/kjbm.o )信息,存在某个已关闭的lock没有及时message给master node的代码漏洞。 实际上当时我已经给出了禁用DRM 可能可以避免该ORA-600[kjbmprlst:shadow] 的看法 ,但是 翻阅MOS 上所有现有的ORA-600[kjbmprlst:shadow] case均没有提及disable DRM可以是一种workaround的途径, 提交SR 也没有得到Oracle GCS关于该看法的 肯定回答, 此外还考虑到 核心的产品环境 使用11.2.0.1 这个bug 较多的版本确实不合适, 升级到 11.2.0.2 已修复该Bug 10121589 的bundle Patch 也算是一种不错的方案 ,所以也就没有深究下去。
之后就一直在做升级Exadata到11.2.0.2 的一些准备工作, 但是用户最后考虑到升级Exadata的步骤过于复杂, 很多步骤是不可回退的, 而且在国内升级的案例目前也不多, 推翻了 升级的方案, 于是有了下面的这一段故障分析
故障特征
如上面所说的这是一套Exadata上的4节点 11.2.0.1 RAC , 应用程序是 Oracle 自己的Billing and Revenue Management (BRM) 。从今年初开始多次出现ORA-600[kjbmprlst:shadow]内部错误, 引发该内部错误的是RAC 关键后台进程 LMS ( global cache server process) ,结果是导致实例意外终止。
该ORA-600[kjbmprlst:shadow]在10月份频发的发生(几乎一个礼拜2次),故障发生还存在以下2个特征:
初步分析
通过应用方拿到了某次故障发生当天每一个小时的AWR报告, 这次故障发生在凌晨 03:05 的 1号节点上, 于是开始分析当时的 1号实例的性能负载。
分析AWR 报告的一种方法就是 通过对比多个时间段的报告 来了解性能变化 ,当然前提是知道问题发生的时段, 这里我们来对比2个时段的信息,这三个时段分别是:
1. 问题发生前的几分钟, 因为1号实例上 3点以后的AWR 报告缺失,所以这里使用的是 02:00 ~ 03:00 的AWR
2. 问题发生前的1小时 , 01:00~02:00 的AWR
首先观测DB TIME:
| Snap Id | Snap Time | Sessions | Cursors/Session | |
|---|---|---|---|---|
| Begin Snap: | 14225 | 12-Oct-11 02:00:05 | 284 | 152.2 |
| End Snap: | 14226 | 12-Oct-11 02:59:59 | 288 | 150.1 |
| Elapsed: | 59.91 (mins) | |||
| DB Time: | 809.98 (mins) |
| Snap Id | Snap Time | Sessions | Cursors/Session | |
|---|---|---|---|---|
| Begin Snap: | 14224 | 12-Oct-11 01:00:10 | 284 | 152.3 |
| End Snap: | 14225 | 12-Oct-11 02:00:05 | 284 | 152.2 |
| Elapsed: | 59.91 (mins) | |||
| DB Time: | 257.62 (mins) |
AWR中的DB TIME可以一定程度上反映数据库实例的繁忙程度。这里 01:00 到 02:00 时间段的AAS= 257/60 = 4.28,而问题发生的时间段的 AAS = 809 / 60 = 13 , 说明实例的工作负载明显上升了。
再来看主要等待事件:
| Event | Waits | Time(s) | Avg wait (ms) | % DB time | Wait Class |
|---|---|---|---|---|---|
| enq: TX – row lock contention | 10,072 | 16,079 | 1596 | 33.08 | Application |
| log file sync | 166,546 | 10,579 | 64 | 21.77 | Commit |
| gc buffer busy acquire | 55,828 | 8,017 | 144 | 16.50 | Cluster |
| gc buffer busy release | 21,203 | 5,904 | 278 | 12.15 | Cluster |
| gc current block busy | 29,196 | 3,362 | 115 | 6.92 | Cluster |
| Event | Waits | Time(s) | Avg wait (ms) | % DB time | Wait Class |
|---|---|---|---|---|---|
| log file sync | 258,415 | 4,875 | 19 | 31.54 | Commit |
| gc buffer busy acquire | 44,471 | 3,349 | 75 | 21.66 | Cluster |
| DB CPU | 1,880 | 12.16 | |||
| gc current block busy | 42,722 | 1,748 | 41 | 11.31 | Cluster |
| gc buffer busy release | 10,730 | 1,127 | 105 | 7.29 | Cluster |
问题发生时段的主要等待事件是 enq: TX – row lock contention 这说明存在大量的行锁争用,此外gc buffer busy acquire/release 和 gc current block busy 全局缓存争用等待时长也明显较 之前的 01:00- 02:00 多了数倍,这说明问题发生时段 节点间对全局缓存资源的争用进一步被加剧了。01:00 – 02:00 时段的 enq: TX – row lock contention 不是前5的等待事件,但实际每秒处理的事务数更多为71.8个(问题发生时段为每秒46.3个事务),这说明造成大量行所争用的的原因不是事务变多, 而是应用程序特性造成的。
引起频繁 enq: TX – row lock contention等待事件 和 全局缓存资源争用 的最主要SQL语句均是1usg75g3cx4n6:
| Cluster Wait Time (s) | Executions | %Total | Elapsed Time(s) | %Clu | %CPU | %IO | SQL Id | SQL Module | SQL Text |
|---|---|---|---|---|---|---|---|---|---|
| 4,047.30 | 20,470 | 22.75 | 17,790.11 | 21.01 | 0.04 | 0.00 | 1usg75g3cx4n6 | update |
SQL “1usg75g3cx4n6” 是一条Update更新语句,在此不列出。
问题发生时段该语句 1 号实例上运行了20470次,平均每次运行耗时 0.87s , cluster wait time 占该SQL总执行时间的22.75% ,而在01:00 – 02:00 期间该语句共运行了32845 次,平均每次运行耗时 0.02s , cluster wait time 占该SQL总执行时间的 67.44 %。
以上信息说明1号实例在问题发生时段 由SQL语句1usg75g3cx4n6 因为enq: TX – row lock contention(主要因素) 和 gc 全局缓存争用 (次要因素)相互作用引起了巨大的负载。引起enq: TX – row lock contention行锁争用的主要原因是 并发的DML更新相关的行数据。
深入分析
除了在问题发生时段数据库负载加剧,出现大量的行锁和全局缓存争用外,问题时段还出现了大规模的动态资源管理操作DRM( Dynamic Resource Management)。
引入DRM的目的是尽可能减少RAC 中CPU和 消息通信的消耗,DRM的资源管理决定依据相关对象的全局缓存操作历史, 该特性会定期自动找出集群中频繁访问某个缓存对象的节点实例,并将该缓存对象re-master到该实例上以优化RAC性能。 DRM 由 LMON、LMD 和 LMS 进程协同完成, LMS负责传输实际的 gcs resouce和 lock 锁信息 , 11g中受到_gc_policy_time隐藏参数的影响,默认最短每10分钟可能被触发。当设置_gc_policy_time=0 ,则object affinity 和 11g 中引入的read mostly policies新特性均将被禁用。
AWR报告中1号实例问题时段的 DRM 统计:
| Name | Total | per Remaster Op | Begin Snap | End Snap |
|---|---|---|---|---|
| remaster ops | 2 | 1.00 | ||
| remastered objects | 2 | 1.00 | ||
| replayed locks received | 215,517 | 107,758.50 | ||
| replayed locks sent | 339,349 | 169,674.50 | ||
| resources cleaned | 0 | 0.00 | ||
| remaster time (s) | 7.4 | 3.70 | ||
| quiesce time (s) | 4.3 | 2.13 | ||
| freeze time (s) | 0.1 | 0.04 | ||
| cleanup time (s) | 0.4 | 0.21 | ||
| replay time (s) | 1.0 | 0.48 | ||
| fixwrite time (s) | 0.9 | 0.47 | ||
| sync time (s) | 0.8 | 0.38 | ||
| affinity objects | 525 | 525 |
以下为01:00- 02:00 时段的DRM 统计:
| Name | Total | per Remaster Op | Begin Snap | End Snap |
|---|---|---|---|---|
| remaster ops | 5 | 1.00 | ||
| remastered objects | 8 | 1.60 | ||
| replayed locks received | 110,902 | 22,180.40 | ||
| replayed locks sent | 68,890 | 13,778.00 | ||
| resources cleaned | 0 | 0.00 | ||
| remaster time (s) | 12.9 | 2.57 | ||
| quiesce time (s) | 1.4 | 0.28 | ||
| freeze time (s) | 0.2 | 0.03 | ||
| cleanup time (s) | 0.9 | 0.17 | ||
| replay time (s) | 0.5 | 0.10 | ||
| fixwrite time (s) | 1.9 | 0.38 | ||
| sync time (s) | 8.0 | 1.60 | ||
| affinity objects | 526 | 525 |
可以看到在问题发生时段 DRM 发送(sent)了更多的replayed locks锁资源 ,这里的replay是指将本地锁信息传送到新的master 实例(REPLAY – Transfer of the local lock information to the new master.) , 而负责发送这些replayed locks锁资源的 正是LMS 进程。
如上文所述1、2、4节点均出现过该ORA-600[kjbmprlst:shadow]故障,但是唯有3号节点从没有出现过该问题, 打开3号节点在问题发生时段(03:00-04:00) 的AWR报告后就有重大的发现:
| Elapsed Time (s) | Executions | Elapsed Time per Exec (s) | %Total | %CPU | %IO | SQL Id | SQL Module | SQL Text |
|---|---|---|---|---|---|---|---|---|
| 3,590.52 | 0 | 17.30 | 34.71 | 63.63 | 59v4zh1ac3v2a | DBMS_SCHEDULER | DECLARE job BINARY_INTEGER := … | |
| 3,589.83 | 0 | 17.29 | 51.69 | 37.98 | b6usrg82hwsa3 | DBMS_SCHEDULER | call dbms_stats.gather_databas… | |
| 2,173.79 | 1 | 2,173.79 | 10.47 | 62.16 | 28.75 | b20w3p880j2gs | DBMS_SCHEDULER | /* SQL Analyze(1) */ select /*… |
可以发现3号节点当时正在运行”call dbms_stats.gather_database_stats_job_proc ( )” 11g中自动收集统计信息的作业,该作业运行了较长时间(一个小时内尚未完成), 我们知道10g以后引入了默认的自动收集统计信息的作业,在11g中得到了加强, 这一作业会自动收集自上一次收集以来更新超过总数据量10%的 对象的统计信息, 因为该核心产品数据库是大型的OLTP应用,在03:00之前已经发生了大量的数据更改,所以这导致gather_database_stats_job_proc 要收集许多大对象上的统计信息,而这会引发该3号实例频繁Request之前在 1、2号实例中被更新的全局缓存资源,频繁地访问影响了DRM的decision, 导致大量的object 被 re-master 到 3号节点上。
| Name | Total | per Remaster Op | Begin Snap | End Snap |
|---|---|---|---|---|
| remaster ops | 14 | 1.00 | ||
| remastered objects | 25 | 1.79 | ||
| replayed locks received | 1,088,009 | 77,714.93 | ||
| replayed locks sent | 202,112 | 14,436.57 | ||
| resources cleaned | 0 | 0.00 | ||
| remaster time (s) | 30.8 | 2.20 | ||
| quiesce time (s) | 8.5 | 0.60 | ||
| freeze time (s) | 0.4 | 0.03 | ||
| cleanup time (s) | 3.3 | 0.24 | ||
| replay time (s) | 6.4 | 0.46 | ||
| fixwrite time (s) | 7.7 | 0.55 | ||
| sync time (s) | 4.5 | 0.32 | ||
| affinity objects | 4,294,967,289 | 4,294,967,289 |
可以看到3号实例接收了大量的replayed lock (replayed locks received) ,而发送的lock则很少。而实际发送(sent) 给 3号实例这些锁信息 资源的 正是 1号实例上的LMS进程。
翻阅alert.log 和视图 我发现每一次的gather_database_stats_job_proc均在凌晨3点的 3号实例发生, 因此每一次故障发生时3号实例只要接收这些replayed locks 资源即可,其LMS进程 仅发送少量的 replayed locks , 所以造成了上面所说的3号实例从不发生该ORA-600[kjbmprlst:shadow]
我们再来阅读上发生ORA-600[kjbmprlst:shadow]故障的LMS进程的trace文件中的部分内容:
*** 2011-10-12 02:25:22.770 DRM(22812) win(8) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22813) win(1) lms 1 finished replaying gcs resources *** 2011-10-12 03:05:29.717 lms 1 finished fixing gcs write protocol DRM(22813) win(2) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol *** 2011-10-12 03:05:30.312 DRM(22813) win(3) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22813) win(4) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22813) win(5) lms 1 finished replaying gcs resources *** 2011-10-12 03:05:31.280 lms 1 finished fixing gcs write protocol DRM(22813) win(6) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22813) win(7) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol *** 2011-10-12 03:05:32.269 DRM(22813) win(8) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22814) win(1) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22814) win(2) lms 1 finished replaying gcs resources *** 2011-10-12 03:05:33.479 lms 1 finished fixing gcs write protocol DRM(22814) win(3) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22814) win(4) lms 1 finished replaying gcs resources *** 2011-10-12 03:05:34.333 lms 1 finished fixing gcs write protocol DRM(22814) win(5) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol DRM(22814) win(6) lms 1 finished replaying gcs resources lms 1 finished fixing gcs write protocol *** 2011-10-12 03:05:35.315 DRM(22814) win(7) lms 1 finished replaying gcs resources Incident 1035732 created, dump file: /maclean1_lms1_20075_i1035732.trc ORA-00600: internal error code, arguments: [kjbmprlst:shadow], [], [], [], [], [], [], [], [], [], [], [] 2011-10-12 03:05:36.811503 : kjbmprlst: internal error on replaying 0x618cd.371 from 3 2011-10-12 03:05:36.811541 : kjbmbassert [0x618cd.371] 2011-10-12 03:05:36.811559 : kjbmsassert(0x618cd.371)(2) 2011-10-12 03:05:36.811636 : kjbmsassert(0x618cd.371)(3) 2011-10-12 03:05:36.811667 : kjbmsassert(0x618cd.371)(4) kjmpbmsg fatal error on 39 MSG [39:KJX_B_REPLAY] .Yq inc=64 len=136 sender=(3,3) seq=0 fg=ip stat=KJUSERSTAT_DONE spnum=14 flg=x24 flow ctrl: ver=60 flag=169 len=136 tkts=0 seq=0 wrp=0 sndr=3 dest=1 rcvr=2 FUSION MSG 0x2b178baa5120,39 from 3 spnum 14 ver[64,22813] ln 136 sq[3,8] REPLAY 1 [0x618cd.371, 574166.0] c[0x59f904e08,-17597] [0x1,xc69] grant 1 convert 0 role x0 pi [0x0.0x0] flags 0x0 state 0x100 disk scn 0x0.0 writereq scn 0x0.0 rreqid x0 msgRM# 22813 bkt# 99097 drmbkt# 99097 pkey 574166.0 undo 0 stat 5 masters[32768, 3->32768] reminc 64 RM# 22813 flg x6 type x0 afftime x9776dffe nreplays by lms 0 = 0 nreplays by lms 1 = 0 hv 9 [stat 0x0, 1->1, wm 32768, RMno 0, reminc 34, dom 0] kjga st 0x4, step 0.36.0, cinc 64, rmno 22813, flags 0x20 lb 98304, hb 114687, myb 99097, drmb 99097, apifrz 1 FUSION MSG DUMP END MSG [65521:PBATCH] inc=64 len=8376 sender=3 seq=279807301 fg=q flow ctrl: ver=1 flag=37 len=8376 tkts=0 seq=279807301 wrp=1 sndr=3 dest=1 rcvr=2 MSG [39:KJX_B_REPLAY] .Y'z inc=64 len=136 sender=(3,3) seq=0 fg=ip stat=KJUSERSTAT_DONE spnum=14 flg=x24 FUSION MSG 0x2b178baa31c8,39 from 3 spnum 14 ver[64,22813] ln 136 sq[3,8] REPLAY 1 [0x527f5.27a, 574166.0] c[0xa2f7eddc0,2158] [0x1,xf33] grant 1 convert 0 role x0 pi [0x0.0x0] flags 0x0 state 0x100 disk scn 0x0.0 writereq scn 0x0.0 rreqid x0 msgRM# 22813 bkt# 99582 drmbkt# 99582 pkey 574166.0 undo 0 stat 5 masters[32768, 3->32768] reminc 64 RM# 22813 flg x6 type x0 afftime x9776dffe nreplays by lms 0 = 0 nreplays by lms 1 = 0 hv 33 [stat 0x0, 1->1, wm 32768, RMno 0, reminc 34, dom 0] kjga st 0x4, step 0.36.0, cinc 64, rmno 22813, flags 0x20 lb 98304, hb 114687, myb 99582, drmb 99582, apifrz 1 FUSION MSG DUMP END ......................... ------------process 0xcf22a6d40-------------------- proc version : 0 Local node : 0 pid : 20075 lkp_node : 0 svr_mode : 0 proc state : KJP_NORMAL Last drm hb acked : 114687 flags : x80 current lock op : (nil) Total accesses : 11763805 Imm. accesses : 11763774 Locks on ASTQ : 0 Locks Pending AST : 0 Granted locks : 0 AST_Q: PENDING_Q: GRANTED_Q: KJM HIST LMS1: 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 20:39:0 1:0 13:65521:0 20:39:0 20:39:0 20:39:0 START DEFER MSG QUEUE 0 ON LMS1 flg x87: MSG [61:KJX_SYNC_RCVCHANNEL] inc=64 len=424 sender=(3,3) seq=98262147 fg=iq stat=KJUSERSTAT_DONE spnum=11 flg=x1 SYNC_RCVCHANNEL 0xca303f2f0 from 3 spnum 11 ver[64,196610] receiver 0 last sent seq 0.98262028 receiver 1 last sent seq 1.545148943 receiver 2 last sent seq 1.279807365 MSG [25:KJX_FTDONE] inc=64 len=64 sender=(3,3) seq=109225856 fg=s stat=KJUSERSTAT_ATTACHFAILED spnum=11 flg=x0 MSG [61:KJX_SYNC_RCVCHANNEL] inc=64 len=424 sender=(3,3) seq=98262146 fg=iq stat=KJUSERSTAT_DONE spnum=11 flg=x1 SYNC_RCVCHANNEL 0xca405e758 from 3 spnum 11 ver[64,196610] receiver 0 last sent seq 0.98262028 receiver 1 last sent seq 1.545148943 receiver 2 last sent seq 1.279807365 MSG [25:KJX_FTDONE] inc=64 len=64 sender=(3,3) seq=6400108 fg=s stat= spnum=11 flg=x20 END DEFER MSG QUEUE 0 DUMP ON LMS1 SEQUENCES: [sidx 0] 0:0.0 1:711171046.0 2:279807300.1 3:43212975.0 DEFER MSG QUEUE 1 ON LMS1 IS EMPTY SEQUENCES: [sidx 1] 0:0.0 1:711171047.0 2:279807292.1 3:43212974.0 DEFER MSG QUEUE 2 ON LMS1 IS EMPTY SEQUENCES: [sidx 2] 0:0.0 1:711171047.0 2:279807300.1 3:43212975.0
可以看到在实际出发ORA-600[kjbmprlst:shadow]之前,LMS后台进程确实在进行频繁地DRM操作。
我们不难看出出发ORA-600[kjbmprlst:shadow]的原因是:数据库较高的性能负载, 1号实例上SQL 语句引发的大量行锁争用 和 3号节点上的 gather_database_stats_job_proc 自动统计信息作业 同时存在 , 导致1号实例上的LMS进程频发地执行DRM操作 , 最终在较高的工作负载情况下触发了管理kjbm shadow锁的代码bug 。
经过分析发现2、4号实例发生该ORA-600[kjbmprlst:shadow]故障与1号节点的情形相似,整个RAC中唯有3号节点例外,因为总是由它来执行gather_database_stats_job_proc, 导致它总是成为DRM的受益者 , 而其他3个节点成为受害者。
但是注意 可能你要问 那不就是简单的由自动统计作业引发的故障吗? 用得着分析这么多吗, 直接关掉该作业 或者换个时段就可以了。
回答:实际上如果仅仅是gather_database_stats_job_proc的话是不足以引发该故障的, 一方面由于节点之间的所跑得应用程序都是一样的,也没有采取分区或者分schema , 这导致节点之间的全局缓存资源争用加剧 , 另一方面 因为每个Buffer Cache都较大, 均存放了大量的全局缓存资源, 且数据的更新十分频繁 , 这导致gather_database_stats_job_proc作业开始执行后 大量的全局资源涌向3号实例 ,同时也触发了DRM的决定, 以至于1、2、4号节点上的LMS 在短期内有极大的工作压力 , 最终导致了 bug 被触发。仅仅禁用该gather_database_stats_
虽然以上分析了一大堆但是我对解决该ORA-600[kjbmprlst:shadow]故障的看法没有丝毫改变, 而且更坚定了。Disable DRM 禁用DRM特性可以从根本上改变LMS进程的行为方式,彻底杜绝该ORA-600[kjbmprlst:shadow]故障发生的可能性。
但我仍需要一些佐证!
资料信息
翻阅MOS 一个Note 映入我的眼帘,<Bug 12834027 – ORA-600 [kjbmprlst:shadow] / ORA-600 [kjbrasr:pkey] with RAC read mostly locking [ID 12834027.8]> 这个Note 我在上一次分析这个问题的时候已经阅读过了, 当时该Note的描述该问题会在11.2.0.1 上发生,不提供任何workaround 方法 ,唯一的解决途径是打上11.2.0.2 + Bp 的补丁。
但是我发现这个Note 在最近的 21-OCT-2011 被修改了,内容如下:
Bug 12834027 ORA-600 [kjbmprlst:shadow] / ORA-600 [kjbrasr:pkey] with RAC read mostly locking
This note gives a brief overview of bug 12834027.
The content was last updated on: 21-OCT-2011
Click here for details of each of the sections below.
Affects:
Product (Component) Oracle Server (Rdbms)
Range of versions believed to be affected Versions BELOW 12.1
Versions confirmed as being affected
11.2.0.2
Platforms affected Generic (all / most platforms affected)
Fixed:
This issue is fixed in
12.1 (Future Release)
Symptoms:
Related To:
Internal Error May Occur (ORA-600)
ORA-600 [kjbmprlst:shadow]
ORA-600 [kjbrasr:pkey]
RAC (Real Application Clusters) / OPS
_gc_read_mostly_locking
Description
ORA-600 [kjbmprlst:shadow] / ORA-600 [kjbrasr:pkey] can occur with RAC
read mostly locking.
Workaround
Disable DRM
or
Disable read-mostly object locking
eg: Run with "_gc_read_mostly_locking"=FALSE
这一次翻到这个Note 是在10月28日 ,而这个Note是在10月21日更新的, 不得不说这个更新来的很及时, 提供了2种 workaround 的方式 , 包括彻底禁用DRM ,和之前所说的禁用_gc_read_mostly_locking 特性,相关的bug note 说明了 另一个Exadata case的经过:
Hdr: 12834027 N/A RDBMS 11.2.0.2.0 RAC PRODID-5 PORTID-226 12730844 Abstract: ORA-600 [KJBMPRLST:SHADOW] & [KJBRASR:PKEY] IN A READ MOSTLY & SKIP LOCK ENV *** 08/04/11 04:22 am *** PROBLEM: -------- 3 nodes got crashed and restarted in exadata cluster. DIAGNOSTIC ANALYSIS: -------------------- 8 node Exadata RAC instance. Below instances got terminated and it rejoined cluster around 11:46 Today (01-Aug). Instance2 (gmfcdwp2) got ORA-600 [kjbmprlst:shadow] at 11:46 AM and instance got terminated by LMS1 process. LMS1 (ospid: 14922): terminating the instance due to error 484 instance got terminated by LMS1 process LMS1 (ospid: 28176): terminating the instance due to error 484 instance got terminated by LMS1 process which was seen in instance 4 and 8.
这个case和我们的惊人的相似, 也是几个Exadata上特定的instance number 会出现ORA-600 [kjbmprlst:shadow]。
另一方面需要评估禁用DRM 对于整体性能的影响,其实这一点我已经在<Important parameters For Oracle BRM Application in 11gR2>中介绍了, Oracle 官方推荐为 BRM 应用程序 禁用 DRM 特性 (真绕口) , 而因为这套系统使用的是默认的Exadata 出场的实例参数设置,所以。。。
解决方案
1. 禁用DRM 特性,可以彻底避免LMS进程因为DRM操作而引发bug , 具体做法是设置隐藏参数_gc_policy_time为0。
影响评估:
DRM 特性可以一定程度上优化数据库性能, 但是对于没有分区或分schema 的应用程序而言 DRM并不会带来好处。 Oracle 官方推荐在BRM应用程序 上 要禁用DRM特性, 见Metalink 文档<Questions About BRM Support For Oracle DB 11GR2 And Exadata [ID 1319678.1]>:
“_gc_policy_time=0 to disable DRM.” 修改该_gc_policy_time参数 需要重启实例
2. 部分禁用DRM 特性 , 设置 _gc_read_mostly_locking= False。 设置 _gc_read_mostly_locking= False可以避免replayed lock 大量传输 ,极大程度上减少LMS触发bug的可能性。 修改该参数同样需要重启实例
案例总结
写了这么久有点累了, 也有点不知所云。 可能会再写一篇 介绍11g 中新加入的Read-mostly locking DRM 新特性,本来想在这篇里一并介绍但是发现篇幅有点长了。
有时候我们解决一个问题只需要某个恰当的方案就足够了, 这个方案可以来源于Metalink 、Google 或者朋友, 我们并不知道这种做法、解决方式实际这么生效 , 但是总归或多或少 它生效了。 但是这不代表 真正意义上理解这个故障或者问题了, 譬如 我花了大约 3-4个小时的时间来分析这个问题, 虽然得到的 结论几乎和我在7月份的那一次是一样的 ,但是透过 分析的过程 我还是获益良多 , 这是唯有自己分析方能产生的结果。
同学们, 享受这分析过程带来的 乐趣吧!
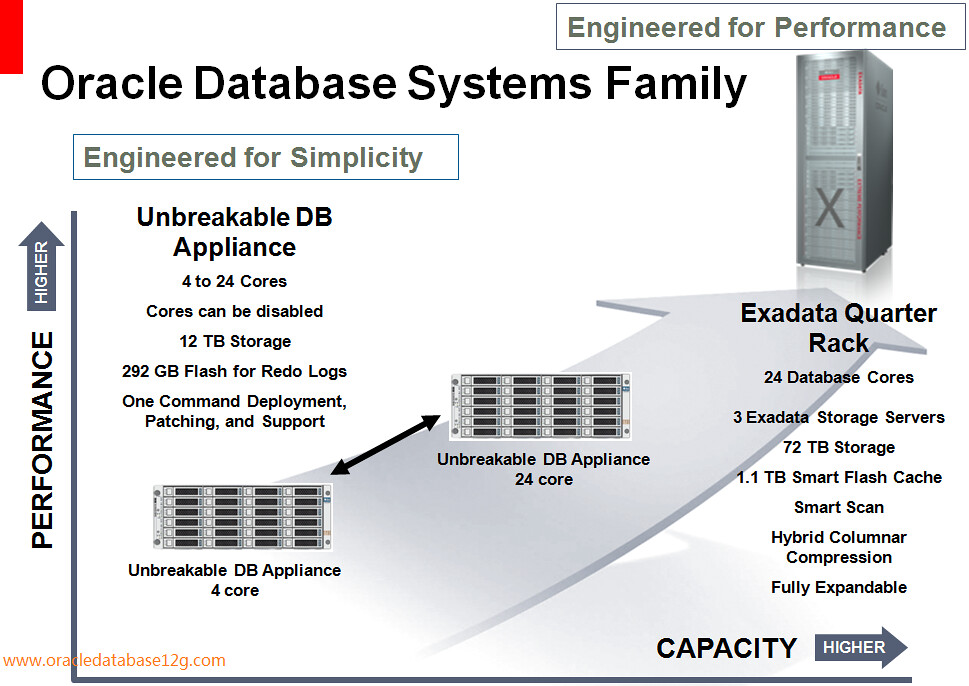
下图列出了Oracle Exadata X2-2 vs EMC Greenplum DCA vs Netezza TwinFin 12 三种一体机的主要配置对比:

Oracle甲骨文系统有限公司在北京时间9月23日发布了一款Oracle数据库机即Oracle Database Appliance。Oracle Database Appliance是一款面向中小型企业的使用简单、用得起的高可用数据库专用服务器,该数据库机基于Sun Fire服务器、Oracle Enterprise Linux和Oracle Database Server 11g release 2 Enterprise Edition,构成一套双节点的Oracle Real Application Cluster集群以供使用。
Database Appliance的正面图

Database Appliance的后视图

Oracle Unbreakable Database Appliance的硬件采用4-RU的机架。包括以下这些硬件配置:
- 24 SAS dual ported disk slots
- 20 x 600GB
- 12TB RAW, 4 TB usable
- 4 x 73GB SSD (Flash Disks) for redo logs
- 2 Socket x86 per server
- 6 Cores per Socket, 12 cores per server
- 96 GB of Memory per server
- 2-12 cores per server enabled on demand
- Redundant 1Gb internal private network
- 2x 10Gb public network per server
- 6x 1Gb public network per server
- Redundant power and cooling
- Hot-serviceable components
- Triple-mirrored storage
显然在即将举行的Oracle Open World 2011大会上Oracle Database Appliance将会成为热议的焦点。这里我们来细数一下Oracle Database Appliance这款数据库机产品的优势和弱点。
用户目前最为关心的恐怕还是Oracle Unbreakable Database Appliance为我们带来了那些特性和优势:
1.一套高度统一标准的平台
所有的Oracle Database Appliance数据库机均才采用一致的硬件配置、软件版本、硬件固件,这导致所有的客户手头所拥有的Database Appliance几乎没有什么差别,也就意味着用户在使用Database Appliance过程中所遇到的问题将是高度相似的;充分利用这一点,Database Appliance的用户可以分享全世界所有其他客户的使用经验,这让问题的迅速定位、解决变成可能。Database Appliance在配置上要比Exadata数据库一体机更为统一。
2. 一套整合的平台
Database Appliance中的每一个组件,包括共享存储、内联网络、数据库主机和Oracle企业版数据库服务器软件在出厂时均已经被整合好了。这同客户从多个厂商那里采购硬件时是不同,客户从DELL、IBM、HP那里订购服务器主机、从EMC、Netapp那里采购存储、从Cisco那里采购网络设备,当这些硬件设备全部到齐后需要一支具有丰富经验的IT team协作来部署Oracle RAC,这其中需要DBA、SA、Storage Admin多种职责的team成员合作并耗费较长的时间才能构建一套RAC集群系统。因为在这个复杂的配置过程中可能出现的网络配置错误或者存储问题可能几天也无法完成工作,更别提在系统今后的运维过程中可能留下的隐患。而如果用户采用Database Appliance这一整合的平台,就可以在很短的时间内完成部署投入使用。
3. 一套高可用的平台
Oracle Database Appliance 采用极为简单的系统架构,在此之下是Oracle数据库被久经考验的高可用方案。包括冗余的风扇和电源、2路冗余的网络以及使用ASM自动存储管理特性实现的三路存储冗余,此外还采用了2节点的RAC RAC集群系统,并具有在不同的地理位置部署2台Database Appliance以实现Oracle Data Guard数据保护的能力。基于客户的自身对可用性和容量的要求,还可以在2节点RAC集群的基础上部署Oracle RAC ONE Node。
4.一套可扩展的平台 – 灵活的CPU许可证(CPU Licensing)
Oracle Database Appliance 提供了在x86平台上首创的灵活CPU License许可证采购方式。通过Oracle Database Appliance,客户可以只购买当前需要的CPU数量的LICENSE;当系统有扩容需求时,客户可以购买额外的CPU使用许可证以便在现有系统上启用更多的CPU内核,最大可以扩展到24 cores。所有的Database Appliance采用Intel Xeon X5675作为主机CPU。
出厂的Oracle Database Appliance 最低启用4 cores ,最多启用满配的24 cores。
当需要为系统扩容启用更多的CPU时只需要:
5.一套管理简单的平台
Oracle Database Appliance附带的Appliance Manager 可以显著地简化appliance整个的安装流程。据某些用户介绍整个安装过程将不超过2个小时,很少需要人工参与,仅仅需要为SCAN Listener监听器分配必要的 IP和DNS域名解析服务,安装完成后用户即获得一套完善的2节点RAC集群系统,以及空的可立即投入使用的数据库DB。
Oracle官方宣传的Database Appliance安装概念:

Oracle Appliance Manager 可部署的模块包括:
Oracle Appliance Manager 的存储管理模块包括:
Oracle Appliance Manager 的Patching补丁模块包括 :
Oracle Appliance Manager 的检验诊断工具包括:
使用Appliance Manager部署的示例流程:
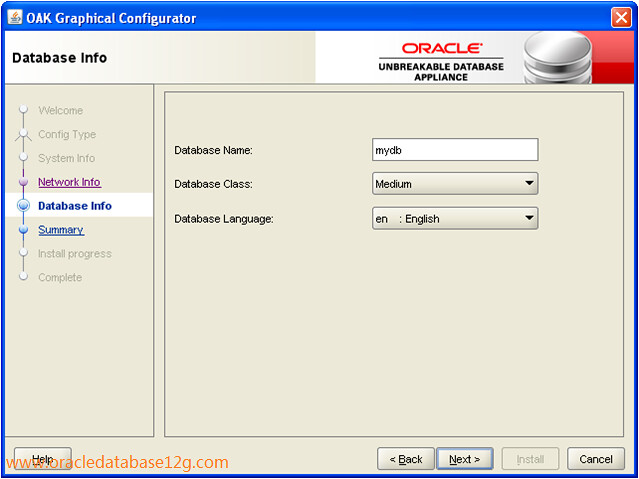
就上述这些特性来看,Database Appliance对于中小型正在发展的企业还是有不小的诱惑力的。当然任何产品都有其弱势的地方,我们来说说Database Appliance的不足:
Oracle Unbreakable Database Appliance不是Mini版的Exadata!
在Oracle正式揭幕Database Appliance之前,当时还称之为( Comet – CPU Cores by Demand),有很多人预测Appliance将会是Mini版的Exadata,将继承数据库一体机的一些独有优势。
但是实际看来,Oracle Unbreakable Database Appliance除了和Exadata一样也叫数据库机外并没有太多的共同点。一个最大的区别在于Database Appliance没有使用Exadata Storage software,这一Exadata的核心组件。而仅仅是采用了最普通的Oracle Database 11g release 2企业版和Oracle Enterprise Linux的组合,Database Appliance没有Smart Scan、没有Storage Index、没有Hybrid Columnar Compression,这些令人惊艳的X特性,这恐怕是最最令人失落的一点!(想用Smart Scan?请先买Exadata的单!)
单系统扩展难
虽然Database Appliance提供了方便的CPU License扩展方案,但是一旦单台满配置的Database Appliance无法满足客户的要求时,要想在Database Appliance的基础上扩展几乎是不可能的。
无法客制化硬件
单一配置的Database Appliance没有为增加客制化的硬件留有余地,这意味着用户不可能为Appliance增加光纤HBA卡或者其他任何控制器。但是这一点也保证了Appliance的硬件配置是高度统一标准的。
Oracle Unbreakable Database Appliance的售价
好了,看了上面一堆的评述你肯定对Database Appliance这玩样的售价抱着很大的好奇心,我们来看看Oracle Unbreakable Database Appliance的价格(仅供参考)。
| Street Prices with 30% HW discount | ||||||
| Configuration | HW List | SW list | System list | 40% SW discount | 60% SW discount | 80% SW discount |
| EE – 4 cores | 50000 | 95000 | 145000 | 92000 | 73000 | 54000 |
| RAC One Node – 4 cores | 50000 | 115000 | 165000 | 104000 | 81000 | 58000 |
| RAC – 4 cores (2×2) | 50000 | 141000 | 191000 | 119600 | 91400 | 63200 |
| EE – 12 cores | 50000 | 285000 | 335000 | 206000 | 149000 | 92000 |
| RAC One Node – 12 cores | 50000 | 345000 | 395000 | 242000 | 173000 | 104000 |
| RAC – 12 cores (6×2) | 50000 | 423000 | 473000 | 288800 | 204200 | 119600 |
| EE – 24 cores (12×2) | 50000 | 570000 | 620000 | 377000 | 263000 | 149000 |
| RAC One Node – 24 cores (12×2) | 50000 | 690000 | 740000 | 449000 | 311000 | 173000 |
| RAC – 24 cores (12×2) | 50000 | 846000 | 896000 | 542600 | 373400 | 204200 |
以上可以看到实际Database Appliance的硬件报价(HW List)仅为50000美元,Oracle Database Server 11.2 EE + 4 cores的组合总报价为145000美元,最搞折扣情况下的总报价为54000美元。
再来看看Database Appliance的售后支持费用,以下列出了Database Appliance 一年的support报价:
| Support Prices with 30% HW discount | ||||||
| Configuration | HW Supt List | SW Supt list | Support list | 40% SW discount | 60% SW discount | 80% SW discount |
| EE – 4 cores | 6000 | 20900 | 26900 | 16740 | 12560 | 8380 |
| RAC One Node – 4 cores | 6000 | 25300 | 31300 | 19380 | 14320 | 9260 |
| RAC – 4 cores (2×2) | 6000 | 31020 | 37020 | 22812 | 16608 | 10404 |
| EE – 12 cores | 6000 | 62700 | 68700 | 41820 | 29280 | 16740 |
| RAC One Node – 12 cores | 6000 | 75900 | 81900 | 49740 | 34560 | 19380 |
| RAC – 12 cores (6×2) | 6000 | 93060 | 99060 | 60036 | 41424 | 22812 |
| EE – 24 cores (12×2) | 6000 | 125400 | 131400 | 79440 | 54360 | 29280 |
| RAC One Node – 24 cores (12×2) | 6000 | 151800 | 157800 | 95280 | 64920 | 34560 |
| RAC – 24 cores (12×2) | 6000 | 186120 | 192120 | 115872 | 78648 | 41424 |
Database Appliance或许是一步好棋
Exadata一直被Oracle宣称为其30年来最耀眼的明星,但显然这明星不是中小企业所能请得动的。Database Appliance的出现彻底补足了Oracle目前数据库机产品线的缺口。现在Oracle拥有低端的4 cores Appliance, 中端的 24 cores Appliance, 以及高端的Exadata X2-2和 X2-8。
Oracle的整个数据库一体机(Database Machine)战略以及其中的主要产品都已经付出水面,Oracle的硬件帝国建筑于SUN之上,然而风格却与SUN迥异。
根据文档《Oracle Sun Database Machine High Availability Best Practices (Doc ID 1069521.1)》的介绍,Oracle官方推荐在Exadata Database Machine上设置 asm_power_limit为4,使用4这个推荐值可以把Exadata上由于ASM rebalance产生的Io损耗对应用的影响最小化。
当使用更快速的ASM数据重平衡时(更大的ASM_POWER_LIMIT),可能潜在地增加对应用的影响,最大的asm_power_limit是11。
根据测试当ASM_POWER_LIMIT=1时添加或移除exadata cell对吞吐量的影响在30MBPS ,当ASM_POWER_LIMIT=11时为330MBPS 。
这里的吞吐量影响并不包括数据压实阶段( compaction phase),数据压实有利于性能但并非为了维护数据正确性所必须的。
